各位朋友,大家好,我是 Payne,欢迎大家关注我的博客,我的博客地址是:https://blog.yuanpei.me。最近这段时间,我一直在学习 ABP vNext 框架,在整个学习过程中,我基本就是在“文档”和“源码”间来回横跳。我个人推荐大家,多去阅读一点优秀的代码,因为阅读 ABP vNext 的源代码简直就是一种享受,它可以暂时让你摆脱如泥沼一般的业务代码。言归正传,ABP vNext 是一个支持多租户架构的框架,在了解了其多租户的实现原理以后,从中收获一点微不足道的小技巧。正好前几天,刚刚同一位朋友讨论完分库、分表这类话题。因此,在今天这篇博客中,我想和大家一起探讨下 EF Core 关于分库、分表以及多租户架构的实现。此中曲折,可以说是初窥门径,或许我无法提供给你一个开箱即用的方案,至少它可以带给你一点启发。有读者朋友建议我,不要总是写这种“高深”、“复杂”的话题,适当地迎合读者写点不需要动脑子的东西。对此,我想说,我有我个人技术上的追求,希望大家理解!
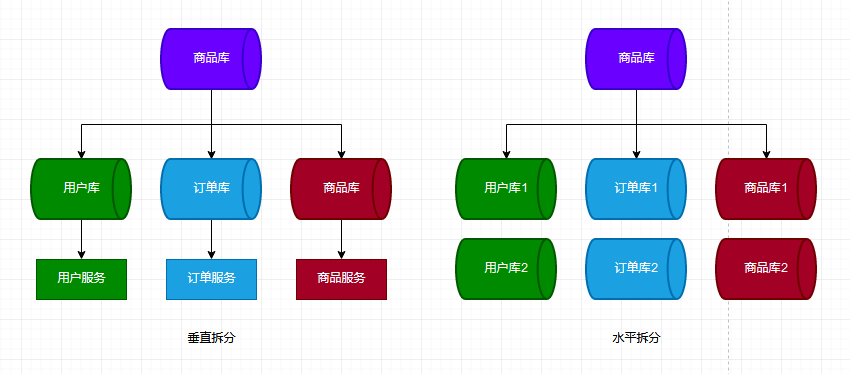
首先,我们一起来探讨分库这个话题。从字面含义上了解,分库就是指应用程序拥有多个数据库,而这些数据库则拥有相同的表结构。你可能会问,为什么我们需要分库、分表?答案自然是性能,性能,还是TM的性能。我相信,大家都曾经或多或少地听到过垂直拆分、水平拆分这样的术语,下图展示了如何在数据库这一层级上进行拆分:
其实,我们可以从索引存储、B+树高度、QPS 和 连接数 这四个不同的角度来审视这个话题。相关观点认为,当单表数据量达到一定量级(阿里巴巴Java开发手册中为500W)时,由于内存无法存储其索引,此时SQL查询会产生磁盘IO;行记录的大小决定了B+树的每个叶子节点能存储多少记录,所以,行记录的大小会影响B+树的高度;单个MySQL物理机实例写QPS峰值大概为1万,一旦业务量达到某个量级,这个瓶颈会逐步凸显出来;单个MySQL实例最大连接数有限,更多的访问量意味着需要更多的连接数。
在谈论分库、分表的时候,我们忍不住会去想譬如“自动分表”和“路由”这样的问题,这些子库、子表,到底是提前在数据库里分好呢,还是在运行时期间自动去拆分呢,以及我对库/表进行拆分以后,我应该怎么样找到某条数据对应的库/表。我承认,这些问题并不简单,但当我们对问题进行简化以后,分库本质上就是动态地切换数据库,对不对?无非是拆分后的数据库可能会是类似db_0、db_1等等这样的序列。
对于数据库的自动拆分,博主尝试过的一种方案是:首先,通过Add-Migration生成迁移。然后,通过循环修改连接字符串的方式,调用Context.Database.Migrate()方法为一个数据库迁移表结构和种子数据。当然,有些朋友不认同在生产环境使用迁移的做法,认为对数据库的操作权限还是应该交给 DBA 来管理,这当然无可厚非。我表达的一直都是一种思路,我不想一个工作六年的人,对技术的态度永远都停留在“能跑”、“能抄”这种水平。
一旦想清楚这一层,实现起来还是非常简单的。我们在配置中准备多个数据库来模拟分库的场景,实际应用中到底是用范围、Hash 还是 配置,大家结合自己的场景来决定就好。其实,这个思路还可以用来做读写分离,无非是这个库更特殊一点,它是个从库。好了,我们一起来看下面的代码:
// 这里随机连接到某一个数据库
// 实际应该按照某种方式获得数据库库名后缀
var shardings = _options.Value.MultiTenants;
var sharding = shardings[new Random().Next(0, shardings.Count)];
_chinookContext.Database.GetDbConnection().ConnectionString = sharding.ConnectionString;
Console.WriteLine("--------分库场景--------");
Console.WriteLine(_chinookContext.Database.GetDbConnection().ConnectionString);
Console.WriteLine(_chinookContext.Album.ToQueryString());
Console.WriteLine(_chinookContext.Artist.ToQueryString());
事实上,如果选择性地忽略 “路由” 和 “自动分表” 这两个特性,我们已经在 EF 层面上局部的实现了 “分库” 功能:
好了,聊完分库,我们再来聊聊分表。分表就是指同一个数据库里拥有多张结构(Schema)相同的表。一个典型的例子是,Excel里的多张Sheet,只要它们拥有相同的结构(Schema),就可以视为同一类型的数据,虽然它们拥有不同的表名。和分库类似,分表的着眼点是避免产生“大表”,从而达到提高查询性能的目的。而对应到 EF(EntityFramework) 的场景中,分表本质上就是在解决 EF 动态适配表名的问题。同样的,下面两张图展示了如何在表这个层级进行拆分:
图片援引自:雨点的名字 - 分库分表(1) — 理论
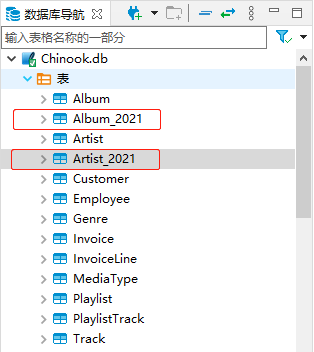
譬如,我们以年为单位,产生了Album_2020和Album_2021两张表。那么,在已经定义好了实体Album的情况下,有没有办法可以让实体Album动态地去适配这两张表呢?或许,熟悉 EF 的你,此刻正在心里暗笑道,这有何难,只要在对应实体的OnModelCreating()方法中,修改ToTable()方法的参数就好了啊。可如果你亲自试一试,就会知道这是你的一厢情愿啦!
事实上,EF 针对实体和表的映射关系做了缓存,这意味着,一旦在OnModelCreating()方法中确定映射关系,这组映射关系将被缓存下来。在 EF 中,这组映射关系的缓存行为,由IModelCacheKeyFactory接口来决定,它提供了一个Create()方法,如果该方法的返回值与上一次相同,则不会调用OnModelCreating()方法。所以,我们的思路就是,让这个Create()方法返回不同的对象。为此,我们考虑实现IModelCacheKeyFactory接口,并用这个自定义实现来替换微软的默认实现。我们一起来看下面的代码:
public class DynamicModelCacheKeyFactory : IModelCacheKeyFactory
{
public object Create(DbContext context)
{
return context is ShardingContext shardingContext
? (context.GetType(), shardingContext.ShardingSuffix)
: (object)context.GetType();
}
}
为了配合DynamicModelCacheKeyFactory的使用,我们还需要定义用于分表的ShardingContext,它继承自DbContext,我们为其扩展了ShardingSuffix属性,并通过注入的IShardingPolicyProvider接口来获取一个分表后缀。比如,我们有Order表,经过拆分后获得Order_01、Order_02这样的子表,所以,这个分表后缀其实就是01、02。没错,我们还是要去修改ToTable()方法中的表名,不同的是,这里的表名是动态的。注意到,Create()方法返回的是一个元组,所以,不同的ShardingSuffix会产生不同的映射关系。
public class ShardingContext : DbContext
{
public DbSet<Artist> Artist { get; set; }
public DbSet<Album> Album { get; set; }
private readonly IShardingPolicyProvider _shardingPolicyProvider;
public string ShardingSuffix { get; private set; }
public ShardingContext(
DbContextOptions<ShardingContext> options,
IShardingPolicyProvider shardingPolicyProvider
) : base(options)
{
_shardingPolicyProvider = shardingPolicyProvider;
ShardingSuffix = _shardingPolicyProvider.GetShardingSuffix();
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
// Album
// 动态映射表名,譬如:Album_2021
modelBuilder.Entity<Album>().ToTable($"Album_{ShardingSuffix}");
modelBuilder.Entity<Album>().HasKey(x => x.AlbumId);
modelBuilder.Entity<Album>()
.Property(x => x.AlbumId).HasColumnName("AlbumId");
modelBuilder.Entity<Album>()
.Property(x => x.Title).HasColumnName("Title");
modelBuilder.Entity<Album>()
.Property(x => x.ArtistId).HasColumnName("ArtistId");
// Artist
// 动态映射表名,譬如:Artist_2021
modelBuilder.Entity<Artist>().ToTable($"Artist_{ShardingSuffix}");
modelBuilder.Entity<Artist>().HasKey(x => x.ArtistId);
modelBuilder.Entity<Artist>()
.Property(x => x.ArtistId).HasColumnName("ArtistId");
modelBuilder.Entity<Artist>()
.Property(x => x.Name).HasColumnName("Name");
}
}
关于分库、分表以后,怎么去匹配对应的库或者表,这类问题我们称之为路由问题。常见的策略主要有,范围、Hash 和 配置:
HASH(userId) % N,其中,N表示当前拆分表的数目。可以预见的问题是,当N变化的时候,会产生数据迁移的需求,所以,这种方式并不利于扩容,在这里,我们是使用年份来作为分表后缀的。为了方便演示,在实现ShardingByYearPolicy类时,我们直接使用了当前时间,这意味着我们会将Album实体映射到Album_2021这张表,以此类推。在实际使用中,更推荐大家使用 雪花算法 生成Id,因为这样,我们就可以通过Id反推出具体的时间范围,进而决定要映射到哪一个库、哪一张表。关于子表的生成,博主这里是通过迁移来实现的,考虑到EF自动创建数据库/表,都需要先创建迁移,所以,这并不是一个开箱即用的方案。
class ShardingByYearPolicy : IShardingPolicyProvider
{
public string GetShardingSuffix()
{
return $"{DateTime.Now.ToString("yyyy")}";
}
}
好了,现在我们可以编写简单的代码,来验证我们的这些想法是都正确,即使是最简单的控制台程序,我还是喜欢用依赖注入:
// 注入ShardingContext
services.AddDbContext<ShardingContext>(options => {
options.UseSqlite(config.GetValue<string>("Database:Default"));
//替换默认实现
options.ReplaceService<IModelCacheKeyFactory, DynamicModelCacheKeyFactory>();
});
// 注入IShardingPolicyProvider
services.AddTransient<IShardingPolicyProvider, ShardingByYearPolicy>();
接下来,我们可以通过ShardingContext来匹配Album_2021表:
// 这里应该连接到Album_2021表
// 实际应该按照某种方式获得表名后缀
Console.WriteLine("--------分表场景--------");
Console.WriteLine(_shardingContext.Database.GetDbConnection().ConnectionString);
Console.WriteLine(_shardingContext.Album.ToQueryString());
Console.WriteLine(_shardingContext.Artist.ToQueryString());
此时,我们会得到下面的结果:
至此,如果选择性地忽略 “路由” 和 “自动分表” 这两个特性,我们已经在 EF 层面上局部的实现了 “分表” 功能。怎么样,是不是还行?
最后,我们来聊聊多租户架构这个话题。可能有朋友觉得多租户架构和分库、分表没什么关系,不好意思啊,这是个非常合理的联想,因为还真就有关系,甚至我们还能继续发散到读写分离。你想想看,多租户架构中,如果一个租户一个数据库,这是不是就是分库的场景。而在分库的场景中,如果一个是主库,一个是从库,这是不是就是读写分离的场景。在学习数学的过程中,学会转化问题是一种重要的思维,即让一个不熟悉的问题变成一个熟悉的问题,在今天这篇博客中,从分库发散到多租户、读写分离,正是这一思路的体现,通常情况下,多租户架构有多数据库和单数据库两种实现方式。
多数据库,指每一个租户一个数据库。这种实现方式的好处是,租户间的数据天然隔离,数据库的访问压力天然隔离。可由于所有租户都共享一套应用程序,随着数据库越来越多,维护的成本亦越来越高。参考分库的实现,我们可以非常容易地实现租户数据库的切换。这里,我们的思路是,调用方在 HTTP 请求中加入自定义的首部字段X-TenantId,DbContext通过该字段来匹配对应的链接字符串,这样就可以实现多数据库的多租户架构:
public class TenantInfoProvider : ITenantInfoProvider
{
private const string X_TENANT_ID = "X-TenantId";
private readonly IHttpContextAccessor _httpContextAccessor;
public TenantInfoProvider(IHttpContextAccessor httpContextAccessor)
{
_httpContextAccessor = httpContextAccessor;
}
public string GetTenantId()
{
var httpContext = _httpContextAccessor.HttpContext;
if (httpContext != null && httpContext.Request.Headers.ContainsKey(X_TENANT_ID))
return httpContext.Request.Headers[X_TENANT_ID].FirstOrDefault();
return null;
}
}
接下来,假设我们AppSettings.json文件维护各个租户的连接字符串信息。通常,在实际场景中,我们会将这些信息存储在数据库中:
{
"Database": {
"Default": "Data Source=Chinook.db",
"MultiTenants": [
{
"tenantId": "01",
"ConnectionString": "Data Source=Chinook01.db"
},
{
"tenantId": "02",
"ConnectionString": "Data Source=Chinook02.db"
}
]
}
}
此时,我们可以通过下面的代码片段来实现租户切换:
var tenantId = _tenantInfoProvider.GetTenantId();
var database = _options.Value.MultiTenants.FirstOrDefault(x => x.TenantId == tenantId);
if (database == null)
throw new Exception($"Invalid tenantId \"{tenantId}\"");
_chinookContext.Database.GetDbConnection().ConnectionString = database.ConnectionString;
Console.WriteLine("--------多租户 + 多数据库--------");
Console.WriteLine($"TenantId:{tenantId}");
Console.WriteLine(_chinookContext.Database.GetDbConnection().ConnectionString);
Console.WriteLine(_chinookContext.Album.ToQueryString());
Console.WriteLine(_chinookContext.Artist.ToQueryString());
可以注意到,一切如我们所预料的一样,程序自动切换到01这个租户:
单数据库,指所有租户都在一个数据库里,使用相同的表结构(Schema),并通过TenantId字段进行区分。ABP vNext 中的多租户架构就是这种模式,而我之前的公司,则是单数据库 + 多数据库的混合模式。这种实现方式的好处是数据库非常精简,而缺点同样很明显,一旦某个租户出现问题,非常容易波及所有租户,因为所有租户都在一个数据库里,数据库的压力实际上是大家一起分担的,租户间相互影响的可能性非常大。
同样地,我们依然需要用到X-TenantId这个请求头,由于所有租户都在一个数据库上,我们不会再试图去修改链接字符串。EF Core 中针对实体提供了HasQueryFilter()扩展方法,该访问允许我们传入一个 Lambda 表达式。此时,我们所有的请求都会自动带上类似Album.TenantId = 'xxxx'这样的条件,这样我们就实现了单数据库的多租户架构。
public class MulitiTenancyContext : DbContext
{
public DbSet<Artist> Artist { get; set; }
public DbSet<Album> Album { get; set; }
private readonly ITenantInfoProvider _tenantInfoProvider;
public MulitiTenancyContext(
DbContextOptions<MulitiTenancyContext> options,
ITenantInfoProvider tenantInfoProvider
) : base(options)
{
_tenantInfoProvider = tenantInfoProvider;
}
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
modelBuilder.ApplyConfiguration(new ArtistMap());
modelBuilder.ApplyConfiguration(new AlbumMap());
// 利用 HasQueryFilter 进行租户间数据隔离
var tenantId = _tenantInfoProvider.GetTenantId();
if (!string.IsNullOrEmpty(tenantId))
{
modelBuilder.Entity<Album>().HasQueryFilter(x => x.TenantId == tenantId);
modelBuilder.Entity<Artist>().HasQueryFilter(x => x.TenantId == tenantId);
}
}
}
为了在实体上应用这个过滤条件,参照 ABP vNext 中的实现,我们定义了IMulitiTenancy接口,所有实体均需要实现TenantId字段。为了简化设计,我们直接使用字符串类型来定义租户Id,而在 ABP vNext 中很多主键都被定义为 Guid,我们掌握核心原理即可,不用过分强求和 ABP vNext 的一致。
// IMulitiTenancy
public interface IMulitiTenancy
{
public string TenantId { get; set; }
}
// Album
public class Album : IMulitiTenancy
{
public int AlbumId { get; set; }
public string Title { get; set; }
public int ArtistId { get; set; }
public string TenantId { get; set; }
}
此时,我们可以编写简单的测试代码,来验证我们的想法是否正确。同样地,我还是使用了依赖注入:
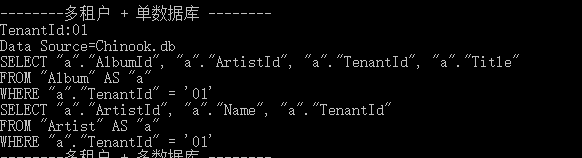
// 这里应该查询01租户内的Album
var tenantId = _tenantInfoProvider.GetTenantId();
Console.WriteLine("--------多租户 + 单数据库--------");
Console.WriteLine($"TenantId:{tenantId}");
Console.WriteLine(_mulitiTenancyContext.Database.GetDbConnection().ConnectionString);
Console.WriteLine(_mulitiTenancyContext.Album.ToQueryString());
Console.WriteLine(_mulitiTenancyContext.Artist.ToQueryString());
可以注意到,打印出的 SQL 语句中自动带出了过滤条件:
这篇博客主要探讨了 EF 在分库、分表及多租户架构上实施的可能性。分库、分表的目的是为了提高数据库的查询性能,在这个过程中,我们可以考虑范围、Hash和配置三种路由策略,它们各自有自己的优缺点,需要使用者结合业务场景去衡量。虽然分库、分表在面对百万级别以上的数据时,不失为一种提高性能的方案,可世间万物都是双刃剑,它同样带来了一系列新的问题,譬如跨库写带来的分布式事务问题,跨库读带来的Join、Count()、排序、分页等问题,数据迁移问题等等,而如果希望通过Hash(Id)来进行拆分,还需要解决全局Id唯一的问题。所以说,这是一个没有标准答案的问题,需要使用者自己去进行取舍。多租户架构、读写分离均可以看作是特殊的分库场景,EF Core 中新增的HasQueryFilter()方法则帮助我们解决了单数据库的多租户架构问题。好了,以上就是这篇博客的全部内容啦,如果大家对文中的观点有建议或者意见,欢迎大家在评论区留言,谢谢!
附本文源代码:https://github.com/Regularly-Archive/2021/tree/master/EF.Sharding
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。