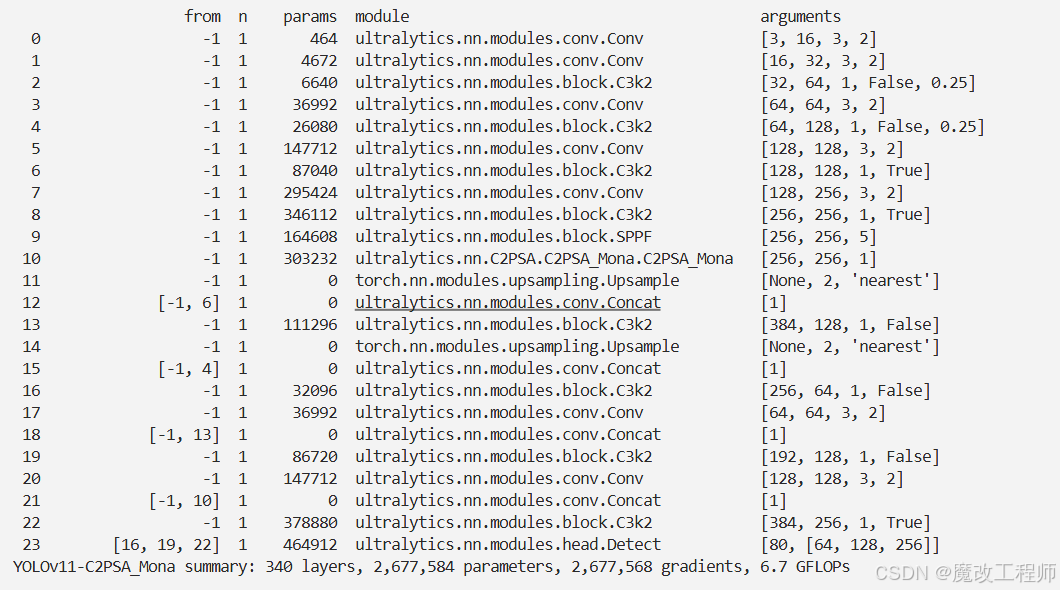
本文介绍了新型视觉适配器微调方法Mona,并将其集成到YOLO26中。传统全参数微调成本高、存储负担重且有过拟合风险,现有PEFT方法性能落后。Mona仅调整5%以内的骨干网络参数,在多个视觉任务中超越全参数微调。其核心亮点包括参数效率高、性能突破和即插即用。适配器模块包含降维、多认知视觉滤波器等单元,通过深度可分离卷积和多尺度卷积核处理视觉信号,还加入分布适配层优化输入分布。我们将Mona集成到YOLO26,经注册和配置yaml文件后进行实验,展现出良好效果。
文章目录: YOLO26改进大全:卷积层、轻量化、注意力机制、损失函数、Backbone、SPPF、Neck、检测头全方位优化汇总
专栏链接: YOLO26改进专栏

Mona(Multi-cognitive Visual Adapter)是一种新型视觉适配器微调方法,旨在打破传统全参数微调(full fine-tuning)在视觉识别任务中的性能瓶颈。Mona 方法通过引入[多认知视觉滤波器] 多认知视觉滤波器&zhida_source=entity)和优化输入分布,仅调整 5% 的骨干网络参数,就能在实例分割、目标检测、旋转目标检测等多个经典视觉任务中超越全参数微调的效果,显著降低了适配和存储成本,为视觉模型的高效微调提供了新的思路。
论文地址:论文地址
代码地址:代码地址
Mona是由清华大学、国科大、上海交大、阿里巴巴联合提出的新型视觉适配器微调方法,相关论文《5%>100%: Breaking Performance Shackles of Full Fine-Tuning on Visual Recognition Tasks》已被CVPR2025收录,其核心目标是打破传统全参数微调的性能与成本枷锁,为视觉大模型高效微调提供新方案。
Mona的适配器模块包含降维、多认知视觉滤波器、激活函数、升维等单元,并内置跳跃连接(Skip-Connections),可无缝集成至Swin-Transformer等主流视觉骨干网络,整体流程为:输入特征经LayerNorm处理后,先降维至内部维度,再通过多认知滤波器增强特征表达,经GELU激活和dropout后升维还原,最终与原始特征残差连接输出。
gamma和gammax调整输入特征分布,使预训练特征更适配适配器的处理逻辑,提升微调效率。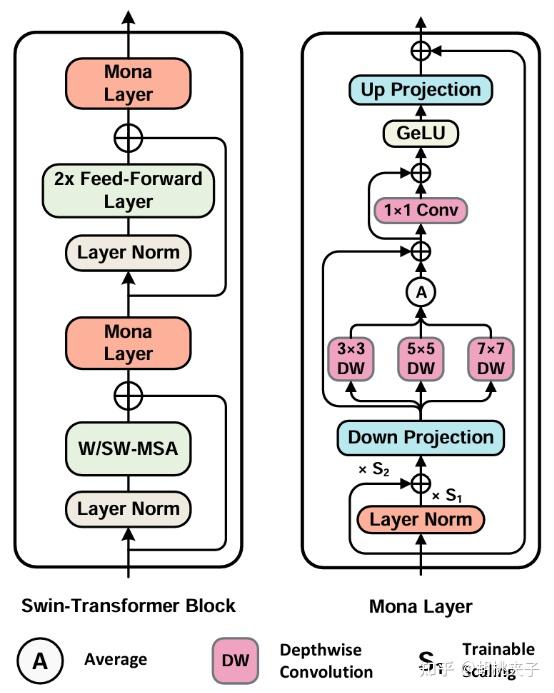
class Mona(BaseModule):
def __init__(self,
in_dim,
factor=4):
super().__init__()
self.project1 = nn.Linear(in_dim, 64)
self.nonlinear = F.gelu
self.project2 = nn.Linear(64, in_dim)
self.dropout = nn.Dropout(p=0.1)
self.adapter_conv = MonaOp(64)
self.norm = nn.LayerNorm(in_dim)
self.gamma = nn.Parameter(torch.ones(in_dim) * 1e-6)
self.gammax = nn.Parameter(torch.ones(in_dim))
def forward(self, x, hw_shapes=None):
identity = x
x = self.norm(x) * self.gamma + x * self.gammax
project1 = self.project1(x)
b, n, c = project1.shape
h, w = hw_shapes
project1 = project1.reshape(b, h, w, c).permute(0, 3, 1, 2)
project1 = self.adapter_conv(project1)
project1 = project1.permute(0, 2, 3, 1).reshape(b, n, c)
nonlinear = self.nonlinear(project1)
nonlinear = self.dropout(nonlinear)
project2 = self.project2(nonlinear)
return identity + project2import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
# 修改为自己的配置文件地址
model = YOLO('./ultralytics/cfg/models/26/yolo26-C2PSA_Mona.yaml')
# 修改为自己的数据集地址
model.train(data='./ultralytics/cfg/datasets/coco8.yaml',
cache=False,
imgsz=640,
epochs=10,
single_cls=False, # 是否是单类别检测
batch=8,
close_mosaic=10,
workers=0,
# optimizer='MuSGD', # 使用MuSGD优化器,会报错
optimizer='SGD',
amp=False,
project='runs/train',
name='yolo26-C2PSA_Mona',
)
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。