MAXX等 +X类的函数会产生行迭代(关于行上下文),即一行行执行某个指定计量公式,那什么是上下文转换,具体点就是行上下文转筛选上下文是怎么个转法?
有下面一这样一张表,原始表有前面两列,第三列是在PBI里定义的,X = CALCULATE(SUM(Sheet1[Column2])),由于使用了CALCULATE,内部会做上下文转换再执行SUM,所以得出X与Column1一样的值。
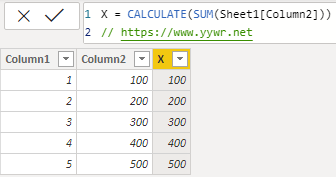
这种转换具体一点就是当公式在具体的某一行执行时,会将这一行的所有字段值做为筛选器,对整张表做筛选,筛选完成之后再执行SUM这个函数。
再具体到这里的例子中,当计算第一行的时候,使用1对表的[Column1]进行筛选,使用100对表的[Column2]进行筛选,筛选出的表结果再执行 SUM[Sheet1[Column1],我们手动在EXCEL里操作一下,结果就是100。
为了验证这个理解,我们将原表添加一行,如下,我们添加的这一行,所有列值和原来的最后一行一样,也就是说现在最后两行的数据是一模一样的。
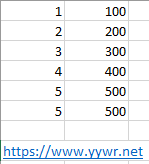
按照上面的理解,我们手动筛选一下,当计算最后两行的时候,筛选出来的应该是两行,得出的结果应该是1000,那么在PBI里面也是这样吗?
结果很明显,就是这么理解的。
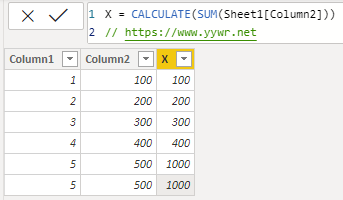
这里引出了另一个问题,如果在实践当中可能涉及到这种两行数据一样的情况,那么在做数据准备阶段是否需要保留或者人工添加一列ID,来确保行上下文件转换筛选出来的结果只有唯一的一行呢?
