对于一个蹒跚学步的孩子来说,要知道什么是苹果,您只需要指着一个苹果说“苹果”(可能会重复这个过程几次)。现在孩子能够识别各种颜色和形状的苹果。
简而言之,由于您的主要任务是选择一个模型并在一些数据上对其进行训练,因此可能出错的两件事是“坏模型”和“坏数据”。 让我们从不良数据的示例开始。
训练数据数量不足
对于一个蹒跚学步的孩子来说,要知道什么是苹果,您只需要指着一个苹果说“苹果”(可能会重复这个过程几次)。现在孩子能够识别各种颜色和形状的苹果。
机器学习还没有完全成熟,大多数机器学习算法都需要大量的数据才能正常工作。即使是非常简单的问题,您通常也需要数千个示例,而对于复杂的问题,如图像或语音识别,您可能需要数百万个示例(除非您可以重用现有模型的部分内容)。
数据的不合理有效性
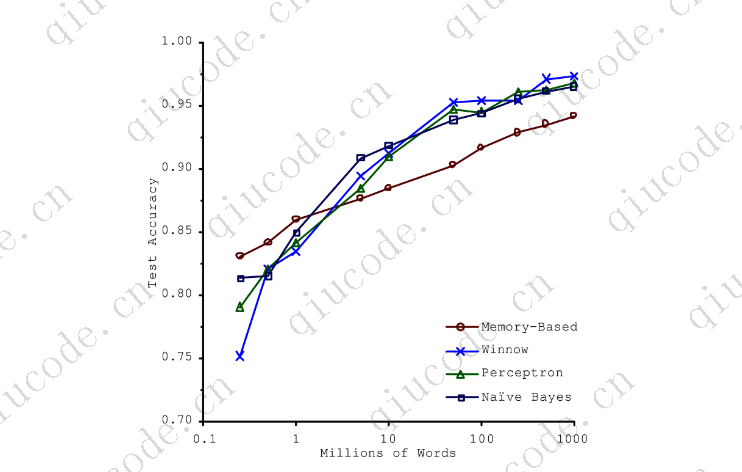
在2001年发表的一篇著名论文中,微软研究人员MicheleBanko和EricBrill展示了非常不同的机器学习算法,包括相当简单的算法,一旦获得足够的数据(如下图所示),它们在自然语言消歧这一复杂问题上的表现几乎相同。
正如作者所说,“这些结果表明,我们可能需要重新考虑在算法开发上花费时间和金钱与在语料库开发上花费时间和金钱之间的权衡。”
Peter Norvig等人进一步推广了数据比复杂问题的算法更重要的观点年发表的一篇名为《数据的不合理有效性》的论文中指出,然而,应该注意的是,中小型数据集仍然很常见,而且获得额外的训练数据 并不总是容易或廉价的,所以不要放弃算法。
非代表性训练数据
为了很好地进行归纳,训练数据必须能够代表您想要归纳的新案例,这一点至关重要。无论你使用基于实例的学习还是基于模型的学习,都是如此。
例如,你早些时候用来培训线性模型的一组国家并不完全具有代表性;它不包含人均国内生产总值低于23500美元或高于62500美元的任何国家。下图显示了添加这些国家的数据是什么样子的。
如果根据这些数据训练一个线性模型,您将得到实线,而旧模型则由虚线表示。正如您所看到的,添加几个缺失的国家不仅会显著改变模型,而且它清楚地表明,这样一个简单的线性模型可能永远不会很好地工作。似乎非常富裕的国家并不比中等富裕的国家更幸福(事实上,他们似乎稍微不幸福!),相反,一些贫穷的国家似乎比许多富裕的国家更幸福。
通过使用不具代表性的训练集,您训练的模型不太可能做出准确的预测,特别是对于非常贫穷和非常富有的国家。

关键是要使用代表您想要泛化的案例的训练集。这通常比听起来更难:如果样本太小,就会有采样噪声(即,由于偶然而产生的非代表性数据),但如果抽样方法有缺陷,即使是非常大的样本也可能不具有代表性。这就是所谓的抽样偏差。
抽样偏差的例子
也许抽样偏差最著名的例子发生在1936年大选期间,当时兰登和罗斯福两人针锋相对:《文学文摘》进行了一次大规模的民意调查,向大约1000万人发送了邮件。它得到了240万个答案,并充满信心地预测兰登将获得57%的选票。相反,罗斯福赢得了62%的选票。缺陷在于《文学文摘》的抽样方法:
- 首先,为了获得发送民意调查的地址,《文学文摘》使用电话–电话簿、杂志订阅者名单、俱乐部会员名单等等。所有这些名单都倾向于更富有的人,他们更有可能投票给共和党(因此是兰登)。
- 其次,只有不到25%的受访者回答了这个问题。这再次引入了抽样偏差,潜在地排除了不太关心政治的人,不喜欢《文学文摘》的人,以及其他关键群体。这是一种特殊的抽样偏差,称为无响应偏差。
这里是另一个例子:假设你想建立一个系统来识别funk音乐视频。建立训练集的一种方法是在YouTube上搜索“放克音乐”,然后使用生成的视频。但这是假设YouTube的搜索引擎返回一组代表YouTube上所有放克音乐视频的视频。在现实中,搜索结果很可能偏向于流行艺术家(而且如果你生活在巴西你会得到很多“funkcarioca”的视频,听起来一点也不像詹姆斯布朗。另一方面,还有什么方法可以让你得到一个大的训练集?
劣质数据
显然,如果您的训练数据充满错误、异常值和噪声(例如,由于低质量的测量),这将使系统更难检测到潜在的模式,因此您的系统不太可能表现良好。花时间清理训练数据通常是非常值得的。事实是,大多数数据科学家花了很大一部分时间来做这件事。以下是一些需要清理训练数据的例子:
- 如果某些实例明显是离群值,那么简单地丢弃它们或尝试手动修复错误可能会有所帮助。
- 如果某些实例缺少一些特征(例如,5%的客户没有指定他们的年龄),您必须决定是要完全忽略该特性、忽略这些实例、填充缺失值(例如,使用年龄中位数),还是使用该特征训练一个模型和不使用该特征训练一个模型。
不相关功能
俗话说:垃圾进,垃圾出。你的系统只有在训练数据包含足够多的相关特征而不是太多无关特征的情况下才能够学习。机器学习项目成功的一个关键部分是提出一套很好的功能来进行训练。这个过程称为特征工程,包括以下步骤:
- 特征选择(在现有特征中选择最有用的特征进行训练)
- 特征提取(结合现有的特征产生更有用的特征–正如我们前面看到的,降维算法可以帮助)。
- 通过收集新数据创建新特征。
现在我们已经看了很多坏数据的例子,让我们看几个坏算法的例子。
过度拟合训练数据
说你要去外国旅游,出租车司机宰了你。你可能会想说那个国家所有的出租车司机都是小偷。过度概括是我们人类经常做的事情,不幸的是,如果我们不小心,机器也会落入同样的陷阱。在机器学习中,这被称为过度拟合:它意味着模型在训练数据上表现良好,但它不能很好地泛化。
下图显示了一个高次多项式生活满意度模型的例子,它强烈地过拟合训练数据。即使它在训练数据上的表现比简单线性模型好得多,你真的会相信它的预测吗?

深度神经网络等复杂模型可以检测到数据中的微妙模式,但如果训练集有噪声,或者训练集太小,这会引入采样噪声,那么模型很可能会检测到噪声本身的模式(如出租车司机的例子)。显然,这些模式不会推广到新的实例。
例如,假设您向生活满意度模型提供更多属性,包括诸如国家名称之类的非信息性属性。在这种情况下,一个复杂的模型可能会检测到这样的模式:在训练数据中,所有名字中带有w的国家的生活满意度都大于7:新西兰(7.3),挪威(7.6),瑞典(7.6)。(7.3)和瑞士(7.5)你对w-satisfaction规则适用于卢旺达或津巴布韦有多大信心?显然,这种模式纯粹是偶然出现在训练数据中的,但是模型没有办法分辨- 个模式是真实的还是仅仅是数据中噪声的结果。
当模型相对于训练数据的数量和噪声太复杂时,就会发生过拟合。以下是可能的解决方案:
通过选择参数较少的模型(例如,线性模型而不是高次多项式模型)、通过减少训练数据中的属性数量或通过约束模型来简化模型。
收集更多的训练数据。
减少训练数据中的噪声(例如,修复数据错误并删除异常值)。
约束模型以使其更简单并降低过度拟合的风险称为正则化。 例如,我们之前定义的线性模型有两个参数,θ0和θ1。 这为学习算法提供了两个自由度来使模型适应训练数据:它可以调整线的高度 (θ0) 和斜率 (θ1)。 如果我们强制 θ1 = 0,算法将只有一个自由度,并且正确拟合数据会更加困难:它所能做的就是向上或向下移动线条以尽可能接近训练实例, 所以它最终会接近平均值。 确实是一个非常简单的模型! 如果我们允许算法修改 θ1 但强制它保持较小,那么学习算法实际上将具有一到两个自由度之间的某个位置。 它将生成一个比具有两个自由度的模型更简单的模型,但比只有一个自由度的模型更复杂。 您希望在完美拟合训练数据和保持模型足够简单以确保其能够良好泛化之间找到适当的平衡。
下图图显示了三种模型。虚线表示在用圆圈表示的国家(没有用正方形表示的国家)上训练的原始模型,实线是第二个使用所有国家/地区(圆形和正方形)训练的模型,虚线是使用与第一个模型相同的数据训练的模型,但使用了正则化约束。您可以看到,正则化迫使模型具有更小的斜率:这个模型不像第一个模型那样适合训练数据(圆),但它实际上更好地推广到了在训练过程中没有看到的新示例(正方形)。

学习期间应用的正则化量可以由超参数控制。 超参数是学习算法(而不是模型)的参数。 因此,它不受学习算法本身的影响; 它必须在训练之前设置并在训练期间保持不变。 如果您设置正则化 超参数设置为一个非常大的值,您将得到一个几乎平坦的模型(斜率接近于零); 学习算法几乎肯定不会过度拟合训练数据,但找到好的解决方案的可能性较小。 调整超参数是构建机器学习系统的重要组成部分(您将在后续篇章中看到详细的示例)。
优化训练数据
正如您可能猜到的那样,欠拟合与过拟合正好相反:当您的模型过于简单,无法了解数据的底层结构时,就会出现欠拟合。例如,生活满意度的线性模型容易出现欠拟合;现实比模型更复杂,因此它的 预测必然是不准确的,即使在训练示例中也是如此。
以下是修复此问题的主要选项:
- 选择功能更强大的型号,参数更多。
- 为学习算法提供更好的特征(特征工程)。
- 减少对模型的约束(例如通过减少正则化超参数)。
后退一步
现在你对机器学习已经了解很多了。然而,我们经历了这么多的概念,你可能会感到有点迷失,所以让我们退一步,看看大图片:
- 机器学习是通过从数据中学习,使机器在某些任务上做得更好,而不是必须显式地编写规则。
- 有许多不同类型的ML系统:监督或不监督,批处理或在线,基于实例或基于模型。
- 在ML项目中,您在培训集中收集数据,并将培训集提供给学习算法。如果算法是基于模型的,则调整一些参数以使模型与训练集相适应(即对训练集本身进行良好的预测),然后希望它也能对新的情况做出良好的预测。如果该算法是基于实例的,它只需用心学习这些示例,并通过使用相似度度量将它们与所学习的实例进行比较,从而推广到新的实例。
- 如果你的训练集太小,或者数据不具有代表性,有噪声,或者被不相关的特征污染(垃圾输入,垃圾输出),系统的性能将不会很好。最后,您的模型既不能太简单(否则会欠拟合),也不能太复杂(否则会过拟合)。
还有最后一个重要的主题:一旦你训练了一个模型,你不想只是“希望”它推广到新的情况。您想要评估它,并在必要时对其进行微调。让我们看看如何做到这一点。