传统语音合成技术受限于高昂的数据需求和庞大的模型参数规模,难以实现个性化语音的实时生成。而字节跳动与浙江大学联合推出的 MegaTTS3,以其 0.45亿参数轻量级架构 和 零样本语音克隆 能力,打破了这一僵局。作为首个完全开源的高效语音生成模型,MegaTTS3 不仅支持中英双语无缝切换,还能通过短短几秒的音频样本克隆音色,甚至灵活调整口音强度,堪称语音合成领域的“瑞士军刀”
架构解析:扩散模型与Transformer的协同创新
MegaTTS3 的核心架构融合了 扩散模型(Diffusion Model) 与 Transformer 的优势,通过模块化设计实现语音属性的精准解耦与控制。其技术亮点包括:
- 多模态信息解耦
- 内容、音色、韵律分离建模:借鉴前作
Mega-TTS2的研究成果,MegaTTS3将语音分解为内容(文本语义)、音色(说话人特征)和韵律(语调节奏)三个独立维度,并通过多参考音色编码器(MRTE)和韵律语言模型(PLM)分别优化,显著提升克隆语音的自然度。 - 自回归时长模型(ADM):动态捕捉语音节奏变化,确保长句合成的连贯性。
- 内容、音色、韵律分离建模:借鉴前作
- 轻量化扩散Transformer主干
- 采用
TTS Diffusion Transformer架构,仅0.45亿参数即可实现与数十亿参数模型相媲美的生成质量。通过混合专家(MoE)设计,模型仅激活部分参数,大幅降低推理资源消耗。
- 采用
- 高效训练策略
- 基于
38k小时中英文混合数据训练,结合轻量级监督微调(SFT)和直接偏好优化(DPO),在保证质量的同时提升训练效率。
- 基于
技术新亮点:不止于“克隆”
- 零样本语音克隆的突破
- 仅需3-5秒的参考音频,即可实时生成与目标说话人音色高度相似的语音,无需微调。这一能力得益于其音色编码器的跨说话人泛化能力,支持从儿童到老人、不同语种的多样化音色捕捉。
- 口音强度可控的语音生成
- 用户可通过调节参数生成带有特定口音的语音(如“带粤语腔调的普通话”),为虚拟角色赋予地域特色或个性化表达。
- 中英混合朗读与语音修复
- 支持同一段文本中中英文自然切换,解决传统模型在双语混合场景下的生硬断句问题。同时,模型可自动修复含噪声或低质量的输入音频,提升鲁棒性。
- CPU环境下的高效推理
- 模型体积仅数百MB,支持在无GPU的本地设备(如普通PC或手机)上实时生成语音,打破硬件限制。
本地部署
首先我们得下载anaconda或miniconda这款用于python虚拟环境管理软件。也许,你有所纳闷,我一贯使用python3自带的venv模块来搭建python虚拟环境,可为什么这次却使用miniconda了呢?
究其原因,是因为MegaTTS3依赖了pynini,而这个依赖库却对windows系统并不是那么的友好,换句话说,若使用python3自带的venv模块来构建的虚拟环境,大概率是安装不了pynini这个依赖库了。
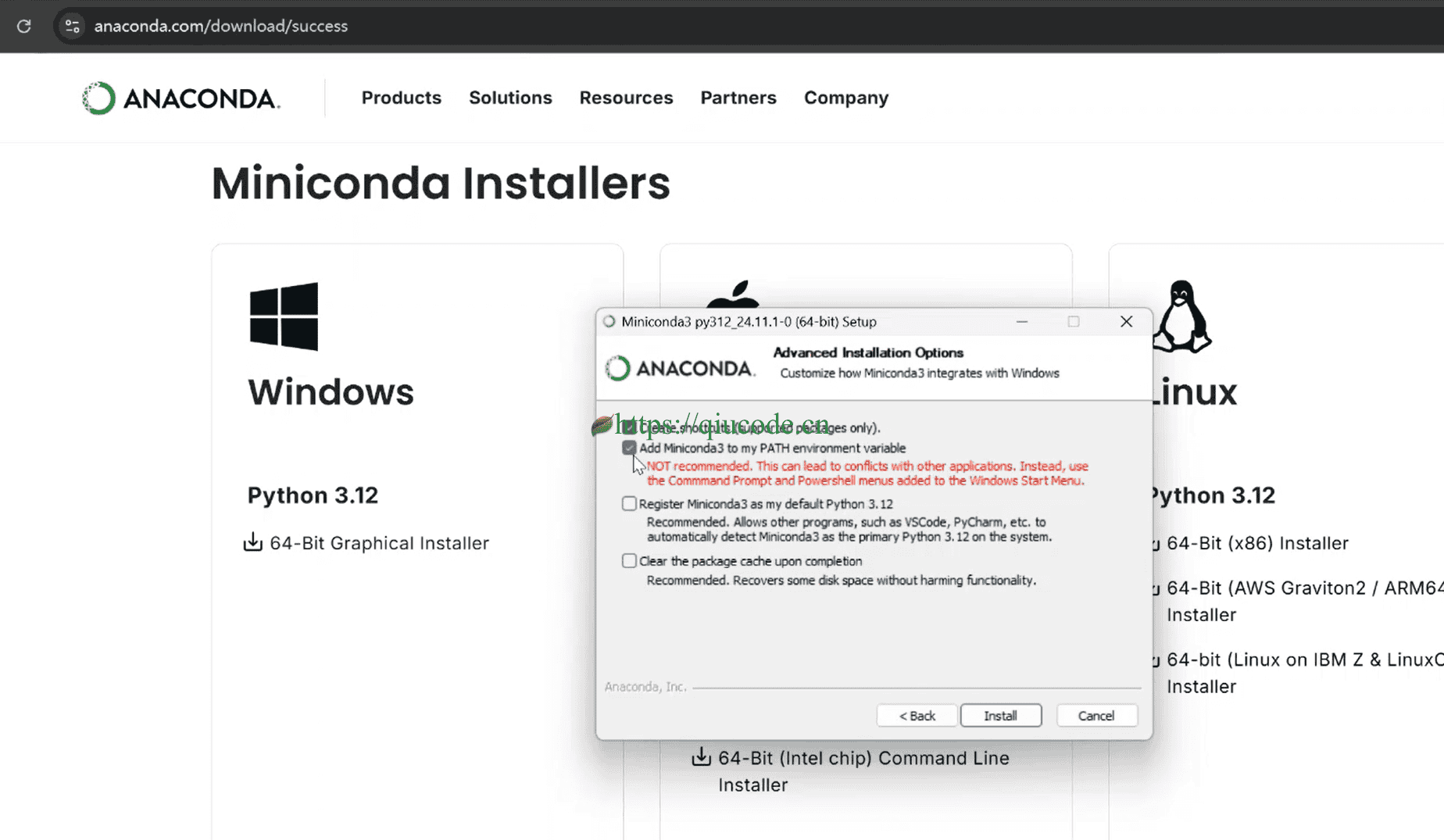
安装miniconda

在安装miniconda时,需将它的安装路径添加到环境变量(PATH)中。
clone MegaTTS3推理代码
我们把MegaTTS3的推理代码给clone到本地。
https://github.com/bytedance/MegaTTS3

使用miniconda创建虚拟环境
我们打开一个Terminal,输入以下命令来搭建一个用于MegaTTS3的虚拟环境:
conda create -n megatts3-env

等它创建初始化成功后,我们继续输入以下命令来激活刚刚创建好的虚拟环境。
conda activate megatts3-env

安装依赖
安装pynini==2.1.5
我们cd到刚刚clone MegaTTS3推理代码的目录下,安装pynini==2.1.5。

安装 WeTextProcessing==1.0.3
这个依赖库就是MegaTTS3所必须的,而它又依赖了我们上面刚刚安装的pynini。这就是为什么使用venv模块创建的虚拟环境安装不了pynini依赖库的原因了,前提是在windows系统下噢。
pip install WeTextProcessing==1.0.3

安装MegaTTS3推理代码所需的依赖库
在安装MegaTTS3推理代码的依赖库之前,我们得修改requirements.txt文件,将WeTextProcessing==1.0.41这一行给删除了,你问了,那就回答你,至于为什么删除它,那是我们刚刚不安装了吗!

删除了WeTextProcessing==1.0.41这一行后,保存并关闭requirsments.txt文件。随后在Terminal输入以下命令:
pip install -r requirements.txt

设置MegaTTS3虚拟环境的环境变量
至于为什么要设置,若你这么问了,具体的我也回答不上来了,详情请浏览我的博客:秋码记录
conda env config vars set PYTHONPATH="D:/AI-project/MegaTTS3;%PYTHONPATH%"
将其中的D:/AI-project/MegaTTS3替换成你clone MegaTTS3推理代码存放在本地电脑的路径。

下载模型
由于MegaTTS3的模型在Hugginface上,若是下载,得设置好网络。
或者使用国内的hugginface镜像网站:https://hf-mirror.com/ByteDance/MegaTTS3 进行下载。
huggingface-cli download ByteDance/MegaTTS3 --local-dir ./checkpoints --local-dir-use-symlinks False

下载字节提供的音色
这款MegaTTS3之所以是半开源的clone voice,就是你想要clone自己的音色,你得把你的声音提交给字节,直到审核通过了,字节会为你上传的同名音频生成同名的.npy文件,至于这是什么文件,也许,只有字节内部的人知道了。

运行tts/gradio_api.py
依赖库安装好了,模型也下载好了,音色也下载下来,那么现在便可以来运行这个MegaTTS3,到底有没有它宣传的那么好了。
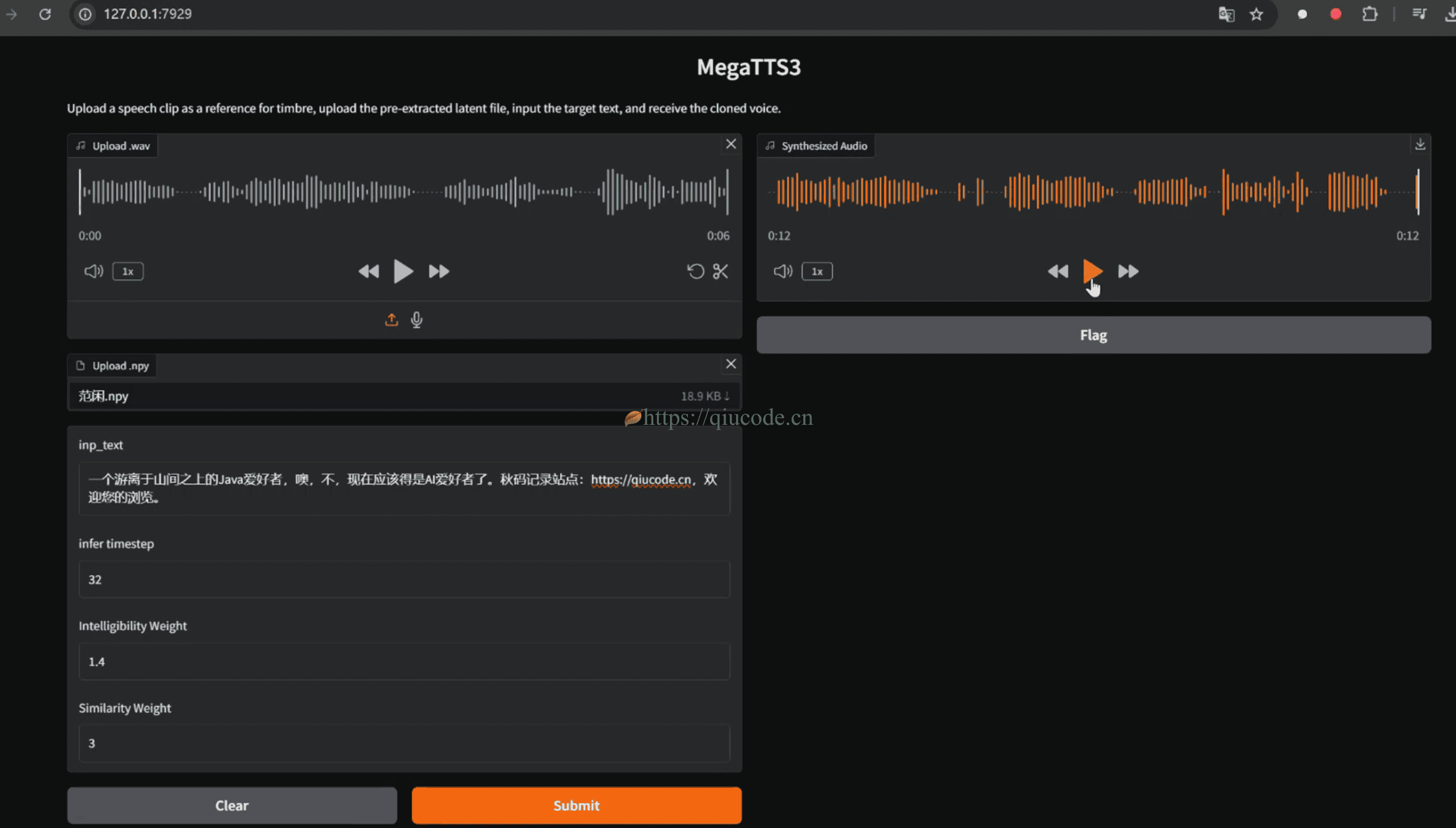
我们在浏览器中输入Terminal所提示的本地URL,出现下图,便可以文本生成音频了。
首先我们上传刚刚下载的字节提供的音色。
第一个框(Upload wav)是上传wav格式的音频。
第二个框(Upload npy)是上传与你第一个框上传的音频同名的.npy文件。
然后,输入文本,点击Submit进行生成。