DeepSeek V4的发布不仅是一次技术迭代,更是一场AI行业的降维打击。1.6T参数的MoE架构、100万token上下文的高效处理、MIT协议开源,再加上仅为竞品1/7的定价策略,这款中国AI大模型正以颠覆性的技术架构和商业逻辑重新定义行业标准。本文将从模型架构、训练方法到地缘政治影响,全面解析V4如何改写AI竞争格局。

4月24日,DeepSeek把V4发出来了。
等了快一年半。
从去年1月R1横空出世,到现在V4preview上线,中间隔了整整15个月。这15个月里DeepSeek几乎没什么大动静,偶尔发几个小更新,然后继续沉默。外面传V4要来的消息从今年1月开始就没断过,一拖再拖,拖到4月才算是真正落地。
我在它发布当晚就把技术报告翻了一遍,用了一天时间跑了一些测试。
这篇文章,是我目前能给出的最诚实的判断。
不吹,不黑,就是说我看到的东西。
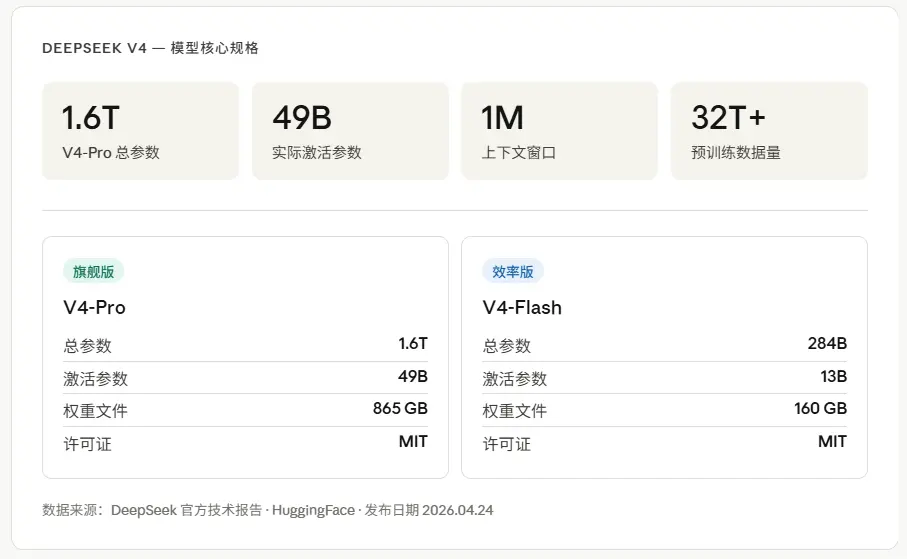
V4这次发布了两个模型,V4-Pro和V4-Flash。
V4-Pro是旗舰,1.6T总参数,每次推理激活49B。V4-Flash是效率版,284B总参数,激活13B。两个都支持100万token上下文,都走MIT协议开源,Hugging Face上直接可以下载。
这里有个数字我觉得很多人没理解清楚,1.6T参数和49B激活到底意味着什么?
MoE架构的核心逻辑是,模型里有大量”专家”,但每次处理一个token的时候,只有其中一小部分被激活。所以V4-Pro虽然总参数量是1.6T,实际上跑起来的计算量,是按49B这个规模来走的。这就是为什么它能在效率上远超同参数量的Dense模型。
打个比喻,就像一家有1600个员工的公司,但每次完成一个任务只需要调49个人,其他人待机。
V4-Pro在Hugging Face上的权重文件是865GB,V4-Flash是160GB。如果你有128GB内存的MacBook,Flash版可能跑得起来,Pro版……理论上能从磁盘流式加载专家,但这个体验不会太好。
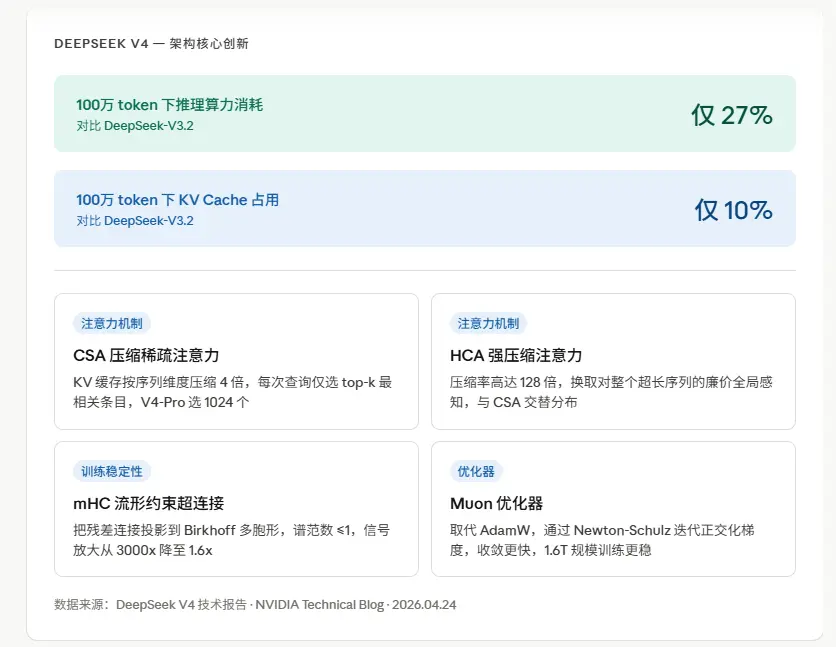
说实话,V4这次最让我眼前一亮的地方不是参数规模,是它怎么解决长上下文的效率问题。
大家都知道100万token的上下文不是什么新鲜事,Gemini很早就支持了,Claude也一直在做长上下文。但这里有个巨大的坑,叫做注意力机制的二次方复杂度,context越长,计算量按平方增长,不是线性,是平方。这意味着把上下文从10万扩到100万,计算量理论上会变成100倍。
所以大多数公司的百万上下文,是一个”能用但很贵”的功能,真正大规模调用起来会让账单爆炸。
DeepSeek V4做的事情,是从架构层面把这个问题切掉了。
他们用了一套叫混合注意力机制的东西,把两种新型注意力交织在一起。
第一种叫CSA(压缩稀疏注意力)
传统注意力是每个token要跟序列里所有其他token算相关性,CSA的思路是先把KV缓存沿序列维度压缩,V4的压缩率是4倍,然后用一个”索引器”给每次查询挑出最相关的top-k个压缩条目来做注意力。V4-Pro每次选1024个,V4-Flash选512个。同时保留一个128 token的滑动窗口,确保局部上下文不会被遗漏。
第二种叫HCA(强压缩注意力)
如果说CSA还算精细化处理,HCA就是粗暴压缩了,压缩率128倍,把大量token合并成一个条目,然后在这个高度压缩的表示上做稠密注意力。这让模型用极低的算力代价,获得对整个超长序列的一个全局感知。
CSA和HCA交替分布在模型的不同层里。V4-Pro从HCA层开始,V4-Flash前两层用滑动窗口,然后交替进行。这样模型在每一层都能在”精准的稀疏查找”和”粗糙的全局视角”之间动态切换,而不是非此即彼。
结果就是,100万token上下文下,V4-Pro的单token推理算力只有V3.2的27%,KV Cache只有10%。
相同上下文长度,计算量降到了27%,内存占用降到了10%
这不是小优化,这是架构层面的降维。这意味着100万token的上下文,在V4上变成了一个经济上可行的日常功能,而不是只有土豪客户才能烧得起的premium特性。
然后还有第三个架构创新,叫mHC(流形约束超连接)。
这个是训练稳定性方面的东西。标准Transformer里的残差连接,就是把层的输入直接加到层的输出上,这个设计在浅层网络里没问题,但在极深的模型里,信号传播会出现不稳定,放大、震荡、训练崩溃。
mHC的做法是把残差连接投影到一个叫Birkhoff多胞形的数学流形上,用Sinkhorn-Knopp算法来强制满足双随机矩阵的约束,把谱范数限制在≤1。
听起来很抽象,翻译成大白话,不用mHC的时候,DeepSeek自己的27B实验里出现了3000倍的信号放大,训练直接崩了,用了mHC之后,放大倍数降到1.6倍,在1.6T参数规模下依然稳定训练。
这个东西已经被IBM、Fireworks AI和多个研究团队标记为”深度网络训练稳定性的基础性贡献”,未来可能影响远不止注意力机制。
最后是Muon优化器
过去大家训练大模型基本都用AdamW,DeepSeek V4换成了Muon。Muon的核心原理是用Newton-Schulz迭代近似地把梯度更新矩阵正交化,然后再应用为权重更新。实际效果是更快收敛、训练更稳定,在1.6T这个量级上,优化器的稳定性是catastrophic failure和正常训练之间的差别。
所以V4这次的架构不是”更大的V3″,是在注意力、残差连接和优化器三个层面都做了实质性的重构。
V4的后训练管线跟之前不太一样。
它用的是两阶段方法,先分培,再合并。
第一阶段,针对每个专业领域单独培养专家模型,数学专家、代码专家、Agent任务专家、通用指令专家,每个专家先做SFT精调,然后用GRPO(一种强化学习技术,之前R1就用过)在领域专属的奖励模型下做RL训练,让每个专家在自己的领域里先练到极限。
第二阶段,用OPD(On-Policy Distillation,策略蒸馏)把所有专家的能力整合进一个统一模型。
OPD和普通蒸馏有个本质区别,普通蒸馏是学生直接模仿老师的输出,OPD是学生先自己生成回答,然后10个专家老师来评判和纠正,学生从这个feedback里学习。
这个流程的好处是什么?
传统多能力联合训练有一个臭名昭著的问题,叫知识干扰,数学的逻辑严谨性和创意写作的灵活性互相打架,代码的确定性思维和通用推理互相妥协,最终训出来的是一个到处都还可以,但哪里都不极致的模型。
V4的两阶段方法先让每个能力跑到天花板,再整合。从benchmark结果来看,这个思路是有效的。
这里有一个美中不足,DeepSeek在技术报告里自己承认了,V4用了10个老师模型的输出来做OPD。OpenAI和Anthropic已经公开指控,中国AI公司包括DeepSeek,通过2.4万个欺诈账号跑了1600万次对话,涉嫌从Claude等模型里非法蒸馏能力。美国白宫在V4发布前一天(4月23日)专门发了个备忘录,称”工业规模级”的能力窃取是国家安全威胁。
DeepSeek没有直接回应这个指控,中国外交部称这是”对中国AI成就的污蔑”。
这条线没定论,但它会是V4后续生命周期里绕不开的阴影。
先把数字摆出来。
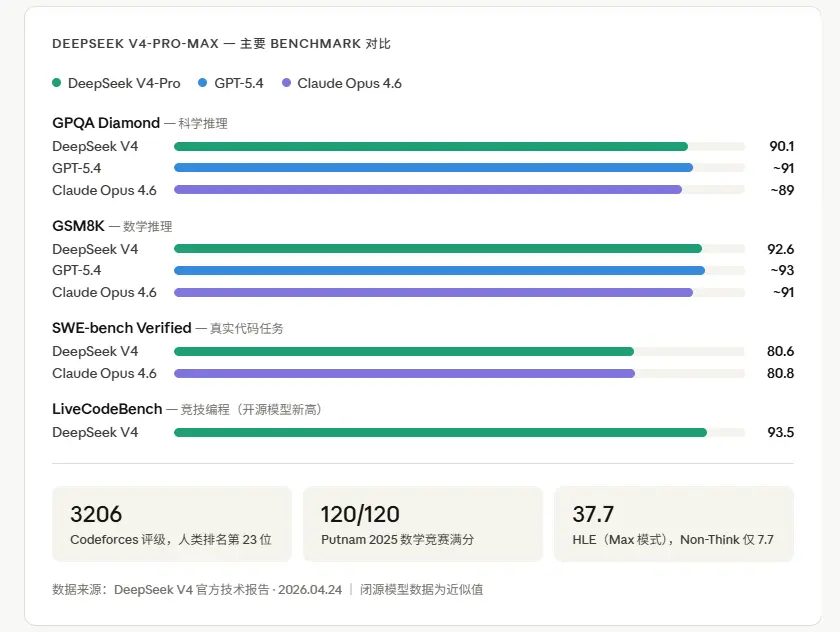
V4-Pro-Max的成绩单,GPQA Diamond 90.1,GSM8K 92.6,MMLU Pro 87.5,LiveCodeBench 93.5(这是新的开源模型最高分),Codeforces评级3206(在人类参赛选手里排名第23位)。
跟闭源模型比,与Claude Opus 4.6、GPT-5.4在编程benchmark上基本持平,在SWE-bench Verified上拿了80.6%,跟Claude Opus 4.6只差0.2个点。
这些数字看起来很猛,但有几个地方需要冷静看。
第一,”V4-Pro-Max”这个模式是最大推理预算下的结果,不是日常使用状态。
V4提供三个推理模式:Non-Think、Think High、Think Max。同一个模型,HLE(超高难度基准)这个benchmark,Non-Think模式下7.7分,Max模式下37.7分,差了将近5倍。
benchmark上晒的数字是Max模式,实际API调用成本和速度会有很大差异,不是一回事。
第二,知识类任务还是有差距。
DeepSeek自己的技术报告里承认,V4″落后最先进前沿模型大约三到六个月”。在知识密集型benchmark上,V4-Pro-Max仍然落后于Gemini 3.1 Pro。MMLU-Pro、SimpleQA、GPQA Diamond、HLE,这几个任务代表的是广博的世界知识积累,参数量越大优势越明显,Gemini目前还是压着V4的。
第三,超长上下文的检索质量有天花板。
100万token的理论很美,现实是在MRCR测试里,超过128K token之后检索准确率开始下降,到100万token的时候只有66%。这不是废了,但离”完美处理100万token”还有差距。用来做全书代码库理解可以,用来做精确法律文档检索的话要谨慎。
第四,V4-Pro和V4-Flash的差距比你想的小。
在同等推理预算下,Flash-Max在推理类benchmark上的成绩非常接近Pro-Max,差距只有1到2个点,但API成本是Pro的12分之一。如果你的业务不需要极致的知识广度,Flash-Max可能是性价比最炸裂的选择。
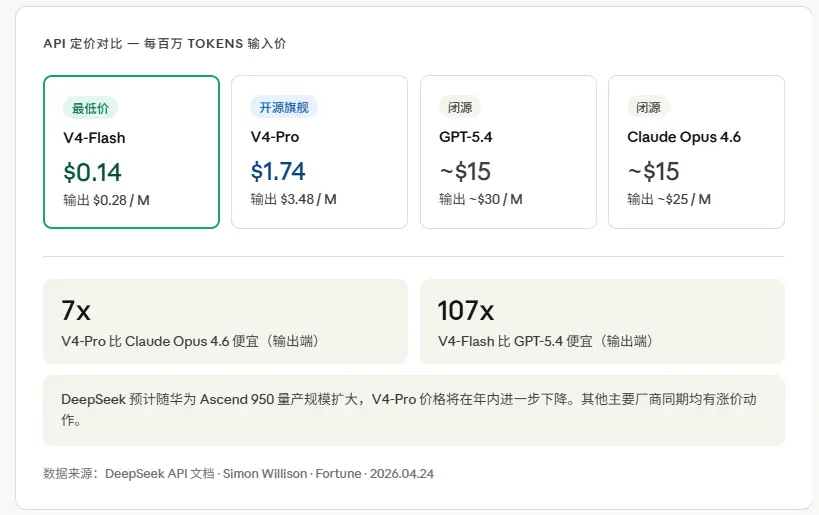
这个环节我有点语言匮乏,因为DeepSeek的定价逻辑已经不能用”便宜”来形容了,这是真不要钱。
V4-Flash,输入$0.14/百万token,输出$0.28/百万token。
V4-Pro,输入$1.74/百万token,输出$3.48/百万token。
对比一下
GPT-5.4和Claude Opus 4.6的输出价格是$25到$30/百万token。
V4-Pro是$3.48。
相同编程benchmark性能,V4-Pro比Claude Opus 4.6便宜7倍以上。
V4-Flash比GPT-5.4 Nano还便宜,是目前价格最低的小型前沿模型。
还有一个细节更厉害,DeepSeek说等华为Ascend 950处理器今年量产规模上来之后,V4-Pro的价格还会进一步降低。
这意味着什么?
意味着当其他公司在想怎么给高质量API涨价的时候,DeepSeek在想怎么继续降。商业逻辑完全不在一个维度上。
当然,价格极低背后也有代价。DeepSeek需要高度依赖国产芯片基础设施来控制成本,这条路走得通的前提,是华为的算力规模真的能跑起来。
这次V4发布,一个巨大的背景是华为芯片。
彭博今天(4月26日)报道,V4发布推迟了好几个月,原因是DeepSeek花时间重构了底层软件栈,目标不只是让模型在华为Ascend芯片上”能跑”,而是做到硬件级别的调优,针对华为架构专门优化内存访问、算子排布。
华为在V4发布当天官方确认,他们的AI集群可以支持V4运行。
半导体制造国际公司(SMIC)的股价当天涨了10%,因为SMIC是华为Ascend处理器的制造商之一。
这个信号的意义远超AI本身,如果DeepSeek真的能在没有Nvidia最先进芯片的情况下训出并跑通一个前沿大模型,那整条美国芯片禁运,中国AI发展受限的逻辑链就被打穿了。
当然,现在还有很多没说清楚的问题。
华为芯片在训练里到底用了多少,跟Nvidia的比例怎么分?Huawei Ascend 950PR的2.87倍H20性能宣传,实际用在大规模训练里表现怎么样?这些数据DeepSeek没有公开,从芯片消耗推算的独立验证也没有出来。
但方向是明确的,中国正在有意识地构建一套平行的AI基础设施,DeepSeek是这套基础设施的主要模型供应商。这件事,比任何benchmark数字都更重要。
值得称赞的是,DeepSeek的技术报告对V4的局限性写得相当坦诚,没有一味吹。
第一个问题,架构太复杂了。
为了控制风险,V4在CSA、HCA、mHC、Muon、FP4这些新创新上,保留了大量V3已经验证过的组件。技术报告里原话是,现在的架构相对复杂,下一代会试图把架构精简到最本质的设计。这话翻译过来就是,现在的V4有点像一辆为了装各种新功能而越来越重的改装车,还没做到优雅。
第二个问题,训练稳定性原理没完全搞懂。
他们用了两个新技术来解决训练不稳定的问题,Anticipatory Routing和SwiGLU Clamping,在实践里管用,但技术报告里承认”背后的底层原理还理解得不够充分”,称训练稳定性是”待研究的基础性问题”。工程上解决了,学术上还没解释清楚。
第三个问题,没有多模态。
这是最明显的缺口。GPT-5.4、Gemini 3.1、Claude Opus 4.6,都深度支持图像、视频等多模态输入,V4还是纯文本。
DeepSeek说在”积极开发”多模态能力,但当前版本不支持。有消息说多模态被推迟,是因为算力和资金压力,而DeepSeek在4月中旬刚刚开放了外部融资窗口,这个时间节点挺耐人寻味的。
DeepSeek之前做过大量视觉语言模型相关的研究,包括DeepSeek OCR,所以多模态技术储备不是没有,是优先级排序的问题。但这意味着,现阶段如果你的业务需要处理图片、视频,V4帮不上忙。
第四个问题,不是R1,没有新叙事。
R1在2025年1月的出圈,是它颠覆了一个认知,花极少的钱、用受限的芯片,一样能训出顶级推理能力。这个故事让整个AI行业的底层逻辑被重写,大家都傻眼了。
V4的故事是什么?更大、更便宜、上下文更长、架构更优雅。这些都是真的,但它是在一个已经被确立的认知框架里继续进化,没有打破新认知。
Morningstar的分析师Ivan Su说:市场已经把”中国AI既有竞争力又便宜”这个结论消化完了,V4的发布不会再引发类似R1的冲击。
先说开发者和企业用户,V4-Flash是目前市场上性价比最高的前沿小模型,没有之一。
13B激活参数,100万token上下文,Max模式推理能力接近Pro,输出只要$0.28/百万token。对于需要大量调用API的代码生成、文档处理、Agent工作流,Flash就是现在的首选。
V4-Pro针对Claude Code、OpenClaw等主流Agent框架做了专项优化,在Agentic Coding benchmark上是开源SOTA。如果你在搭一套重度代码Agent,把Pro替换进去是值得测试的。
再说行业竞争格局,V4让中国开源AI赛道的竞争框架发生了变化。
R1时代,DeepSeek是挑战者,对手是GPT和Claude这些闭源模型。V4时代,DeepSeek开始把阿里的Qwen、字节跳动的Seed、MiniMax、Moonshot这些国内对手列为直接竞争者——这个定位的变化,说明国内AI竞争已经进入了白热化阶段。
V4发布当天,MiniMax、Zhipu(知乎)的股价分别跌了约8%,Manycore Tech跌了9%。资本市场的反应很直接。
最后说地缘政治维度,这是一次AI主权的展示。
无论V4的技术细节怎么被解读,它有一个核心信号是不可忽视的,如果华为芯片路线走通,如果这个成本结构真的可持续,那中国就有了一套在美国出口管制之外能独立运转的前沿AI基础设施。
这比任何一个benchmark分数都更根本地改变了接下来的竞争格局。
V4是DeepSeek回归前沿的一次有分量的发布。技术扎实,架构有创新,价格继续杀价,开源生态继续维护。
但它不是颠覆者,是守擂者。
开源赛道老大的位置,这次稳住了,而且进一步巩固。但想像R1那样再次震撼整个行业,V4做不到,也没打算做到。
V4真正有趣的遗留问题,有三个。
多模态版本什么时候来,来了之后能不能在图像视频这块跟Gemini和GPT-5正面刚。
华为Ascend芯片的量产规模上来之后,训练效率和价格还能往下走多远。
国内的竞品Qwen、字节、MiniMax、智谱,Kimi面对V4这张牌,接下来会出什么招。
本文由 @王小小 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。