用户问“积分怎么用”,我们的机器人回“天气变动请注意更衣”。这不是段子,是我们上线第二周的真实名场面。原因很简单:知识库用的是关键词匹配,用户换个说法就废。后来我用了向量知识库 + 大模型检索,终于让客服不再当智障。

智能客服上线第二周,一位用户问:
“积分怎么用啊?”
我们的知识库里有标准问答:
但机器人没匹配上,因为用户说的是“怎么用”,而库里写的是“如何使用”。关键词匹配没命中,机器人走了默认回复:
“抱歉,知识库中未包含。”
用户回了一个字:“滚。”
运营小姐姐截图发群里:“这机器人是来砸场子的吧?”
我一看日志,问题很清楚:知识库检索用的是关键词匹配(TF-IDF),用户表达稍有变化就搜不到。更惨的是,我们当时只有200条标准问答,覆盖不到所有问法。
很多人做智能客服,一上来就搞大模型生成回复,结果就是胡说八道。我后来想明白了:
客服的第一要务是“把正确答案找出来”,而不是“自己编一个答案”。
用户问“积分怎么用”,他不需要你陪聊,他需要知道“100积分=1元”。所以问题的关键是:如何从知识库里,快速找到最相关的那一条。
传统关键词匹配的痛点是:
用户说人话,库里写的是“官方语言”,匹配不上。
当时我调研了三种方案:
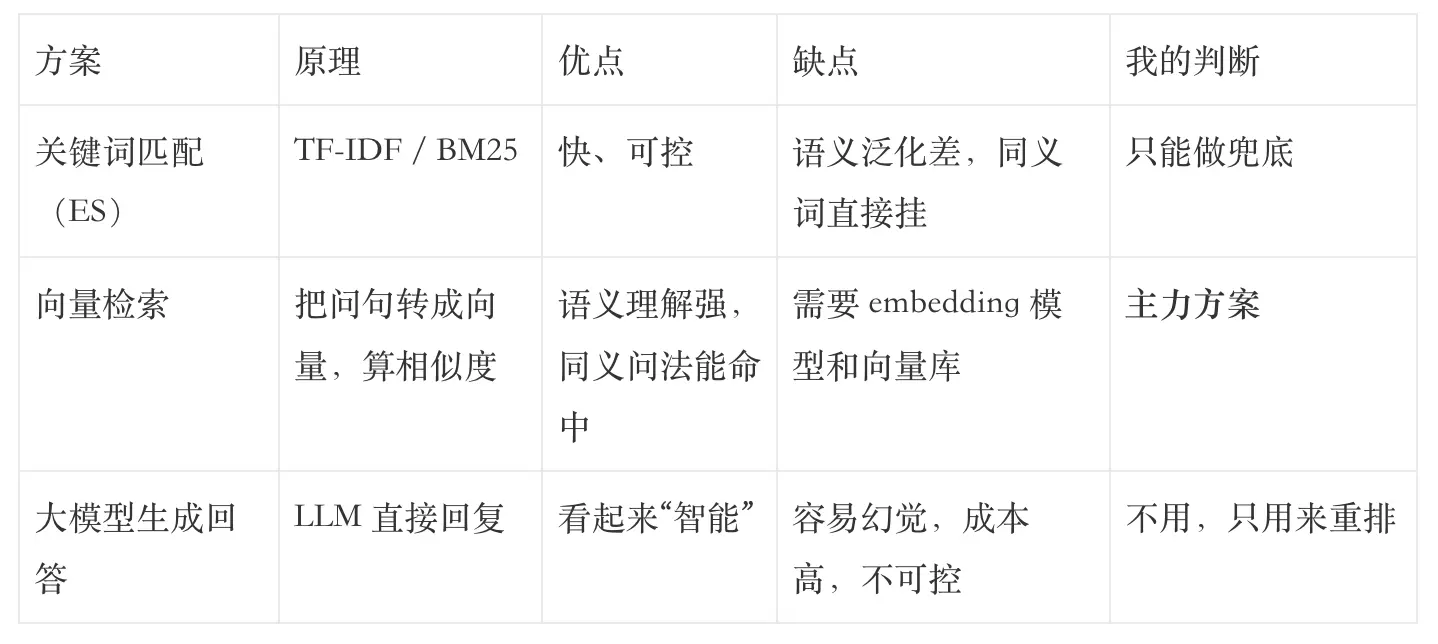
我选了向量检索为主 + 大模型重排为辅的架构:
我们原来有 2000条问答,但很多是“一条问题对应多个答案”或者“答案里带着营销话术”。
我做了三件事:
比如标准问题“积分如何使用”,同义问法:
这一步最花时间,但最值得。200 条问答,扩展后变成 600 条,召回率直接涨了一半。
我们对比了几个开源的中文 Embedding 模型,最终选了一个在公开基准上表现不错的轻量级模型(参数量 ,维度 )。选型标准:
最终模型部署在 CPU 上,足够支撑 400~500 QPS。
把所有标准问题 + 同义问法,全部转成向量,存入 Milvus。
Milvus 是我们选的向量数据库,优势是:
用户问“积分怎么用啊”:
如果大模型重排后最高分仍低于阈值(比如 0.7),说明知识库里没有相关内容,走兜底:
这样就形成了一个数据闭环:线上没命中的问题 → 人工补充 → 向量化更新 Milvus → 下次就能命中。
坑一:同义问法写太多,导致检索漂移
有一次,标准问题“退换货流程”,我们写了同义问法“不想要了怎么办”。结果用户问“衣服小了怎么办”,模型误匹配到“退换货流程”,实际上用户可能只是想换尺码。
解法:同义问法要克制,每个标准问题不超过 5 条,且必须与标准问题语义高度一致。
坑二:长文本问题检索不准
用户问“我上周买的薯片,今天收到发现碎了,怎么退款”,太长了,embedding 会稀释关键信息。
解法:先用大模型做关键信息抽取,抽成“商品=薯片,问题=碎了,动作=退款”,再用短句去检索。这一步我们后来加上了。
坑三:知识库更新不及时
运营改了答案,但 Milvus 里的向量没更新,用户还是拿到旧答案。
解法:每次知识库变更,触发增量更新(只重新向量化改动的条目),Milvus 支持按 ID 删除和插入。
做了这么多,我最大的体会是:
智能客服不要迷信大模型生成。先把知识库检索做到极致,80%的问题就能解决。
向量知识库(Embedding + Milvus)+ 大模型重排,是我目前找到的最佳平衡点:
本文由 @嘻嘻李 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。