在大模型时代,物理世界AI的竞争焦点正在从参数规模转向数据飞轮机制。本文深度解析Physical AI Data Flywheel的五大关键环节,揭秘如何通过仿真生成、数据增强、智能筛选、模型训练和缺口评估构建自进化系统,为自动驾驶与机器人行业提供可规模化的突破路径。

在大模型时代,我们习惯讨论参数规模、算力堆叠和模型架构创新。
但当 AI 真正进入物理世界——自动驾驶、机器人、智能制造——决定上限的,不再只是模型,而是数据飞轮(Data Flywheel)。
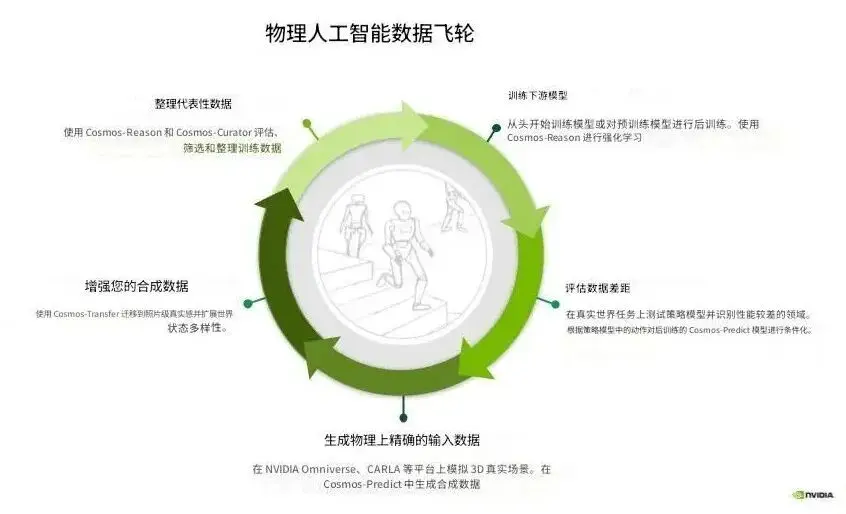
这张「Physical AI Data Flywheel」图,本质上揭示了一套面向物理世界智能的闭环增长机制。
它回答了一个关键问题:
如何让 AI 在真实世界中不断变强?
在纯软件世界里,错误成本低,环境可控,反馈快速。但在物理世界中:
因此,物理 AI 的核心不是“训练一次模型”,而是构建一个:
可持续迭代、自动发现问题、自动补齐数据、自动强化能力的系统。
这就是数据飞轮。
通过 3D 仿真平台构建高保真世界模型,例如:
在这些环境中可以:
这一步的核心价值是:
把“不可控现实”变成“可编排数据工厂”。
仅有仿真还不够。
合成数据必须解决两个问题:
通过数据迁移与增强模型,可以实现:
这是从“工程数据”走向“可训练数据”的关键桥梁。
数据不是越多越好。
在物理 AI 体系中,真正稀缺的是:
通过数据批判、过滤与筛选机制:
这一步本质上是:用 AI 参与数据治理。
当数据被筛选后,进入策略模型训练阶段:
尤其在物理世界中:
强化学习 = 用环境反馈塑造决策能力。
策略模型不只是感知模型,而是:
感知 → 预测 → 决策 → 控制的综合能力系统。
这是飞轮最关键的一环。
在真实世界或仿真闭环测试中:
然后反向驱动:
这一步形成:
失败 → 数据 → 训练 → 再失败 → 再进化
飞轮开始持续加速。
传统 AI 开发流程是:
数据采集 → 训练 → 部署 → 结束
而 Physical AI 飞轮是:
生成 → 增强 → 筛选 → 训练 → 评估 → 再生成
这意味着:
真正进入“自进化系统”阶段。

对于自动驾驶企业来说,这套体系意味着:
而是进入:
数据 × 仿真 × 模型的指数型飞轮增长
对于机器人行业,这更关键:
仿真驱动的物理数据飞轮,是唯一可规模化路径。
未来三年,Physical AI 的竞争,不再只是模型架构之争,而是:
模型会趋同,飞轮则决定上限。
大模型改变了语言世界。
但改变物理世界的,不是单次训练的模型,而是:持续旋转的数据飞轮。
谁能让飞轮转起来,谁就掌握了 Physical AI 的未来。
本文由 @OpenAIer 原创发布于人人都是产品经理。未经作者许可,禁止转载
题图来自Unsplash,基于CC0协议
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。