重磅开源!新一代最强小模型SmolLM3横空出世:30亿参数,支持128k长上下文!而且训练、对齐、架构、数据等全链路,Hugging Face这次100%开放——堪称真「Open AI」。

重磅开源!
刚刚,Hugging Face推出了目前最强的30亿参数模型SmolLM3:

基础模型: https://hf.co/HuggingFaceTB/SmolLM3-3B-Base
指令和推理模型: https://hf.co/HuggingFaceTB/SmolLM3-3B
小模型负责人Loubna Ben Allal如此评价SmolLM3:「强大、小巧的推理模型」。
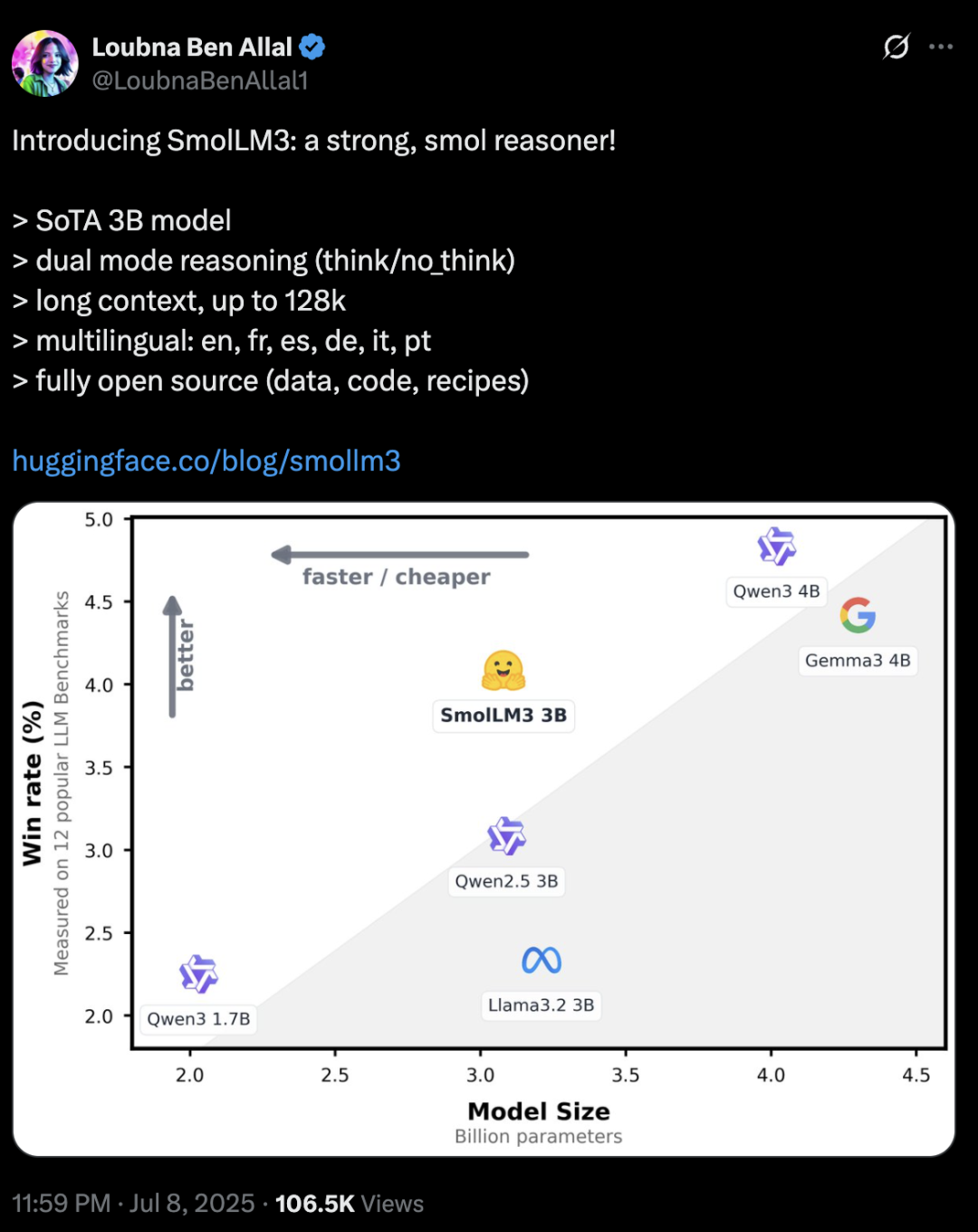
SmolLM3性能很强:
重要的是,它公开了完整的构建方法!100%开源,极大减少了反向工程的时间,为小模型开发提供了难得的参考范本。

SmolLM3不仅展示了完整的「训练-微调-对齐」开源范式,也在提醒:模型规模不是唯一答案,工程细节才是制胜关键!
在模型架构和数据混合策略方面,SmolLM3做出了显著优化。
先从架构设计与训练配置说起。
在Llama架构的基础上,SmolLM3引入多项关键改进,以提升效率和长上下文处理能力。

关键架构优化一览:
📄相关论文:

论文链接:https://arxiv.org/abs/2501.18795

论文链接:https://arxiv.org/abs/2501.00656
基于相同架构进行的消融实验,验证了上述所有改动,确保各项优化措施在提升或保持性能的同时,带来了额外优势。
训练配置如下:

分布式训练设置,见下图。
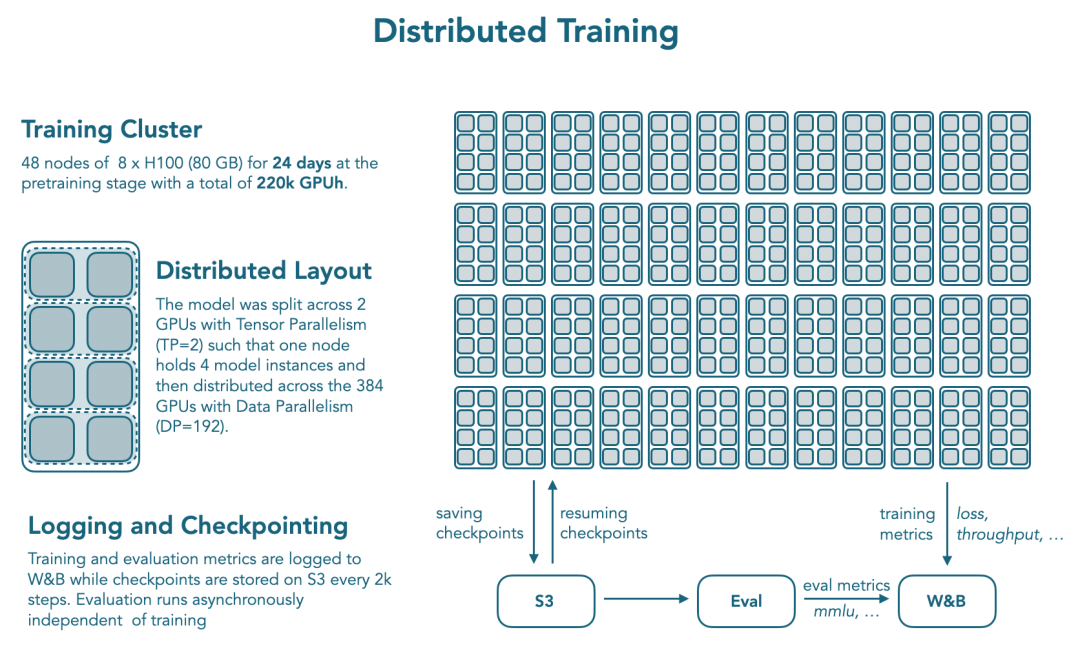
除了架构层面的改进,团队也系统性的实验与优化了训练系统。
延续SmolLM2所采用的多阶段训练方法,SmolLM3使用的训练数据总量达11.2万亿个token,训练采用三阶段策略。
团队混合了网页文本、数学内容与代码数据,还根据训练进度,调整各类数据的比例。
为了确定最优的数据构成与配比,在多个3B模型上,他们进行了大量消融实验,训练数据量涵盖从500亿到1000亿token。
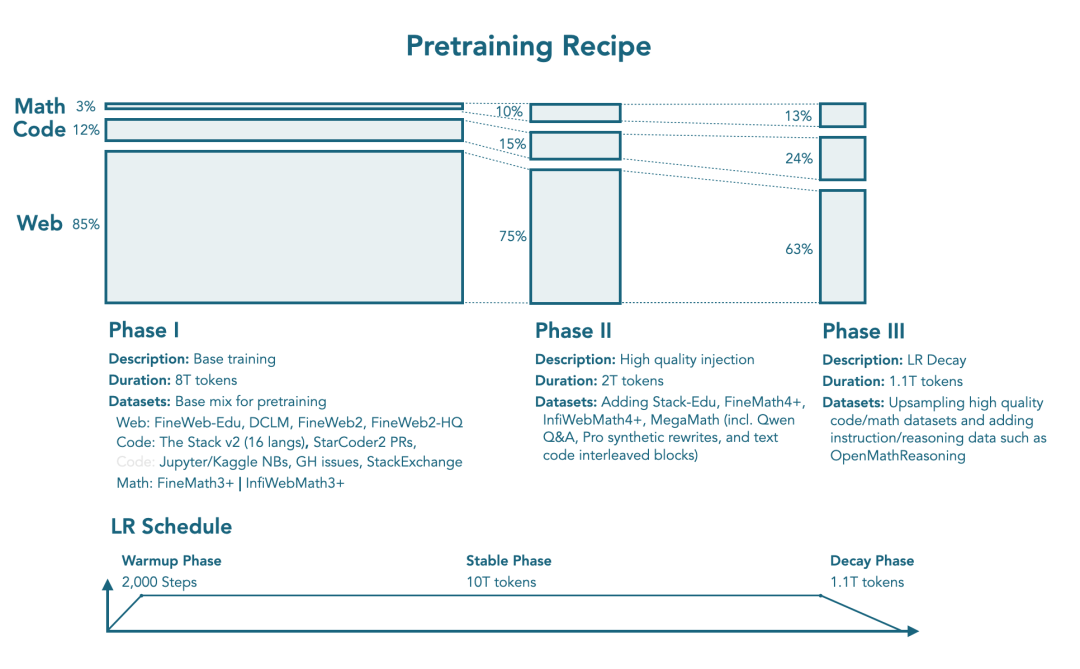
预训练包括以下三个阶段:
各阶段混合数据配比和来源,如下:
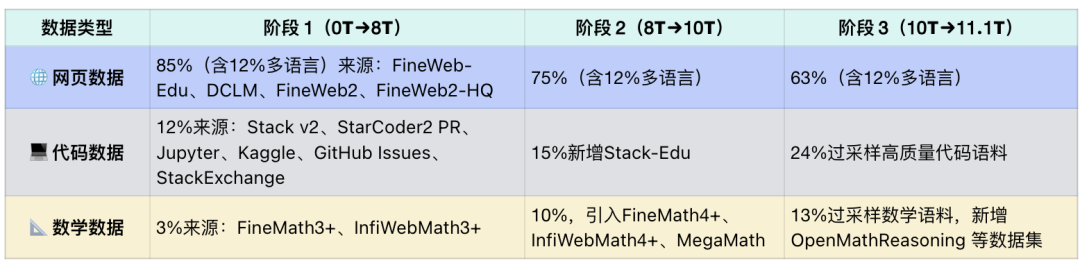
通过上述数据混合策略,在多个任务上,训练出的基础模型表现优异。
此外,在主预训练完成后,研究团队还进行了专门的中间训练阶段,以进一步增强模型在长文本处理和复杂推理任务中的表现。
长上下文适应和推理适应被称为「中期训练」。
与主预训练相比,这些训练阶段要短得多,但仍然具有通用性。
在主预训练完成后,额外训练了SmolLM3,进一步扩展模型的上下文处理能力。
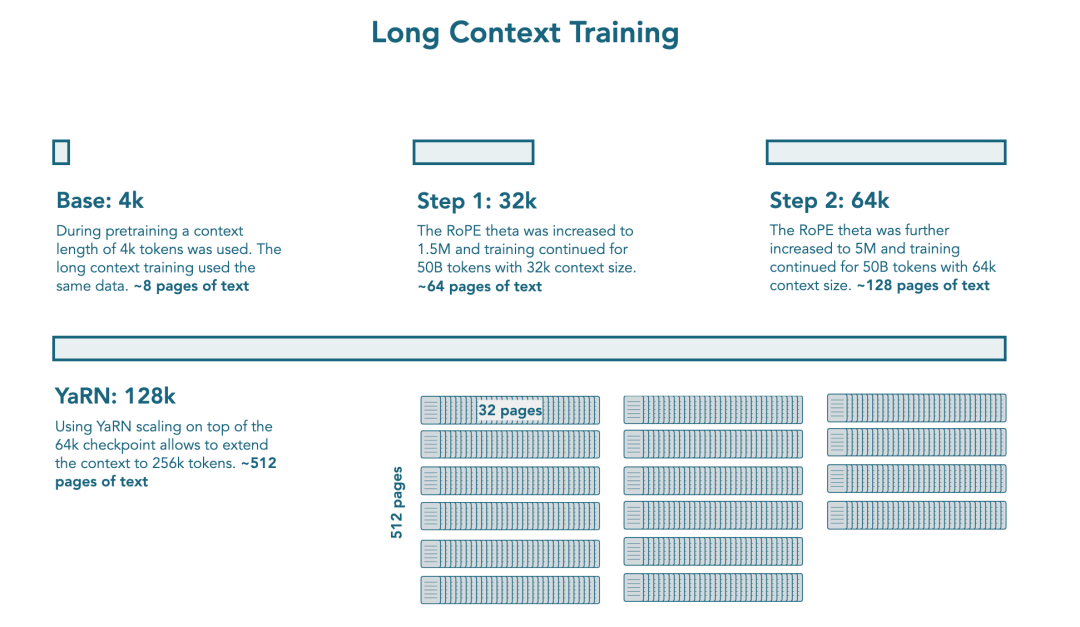
该阶段共使用了1000亿个token,分为两个阶段,各使用500亿token,改进如下表所示:

这两个阶段均过采样了数学、代码和推理相关数据,增强了模型的长文本理解与推理能力。
在RULER和HELMET等长上下文基准测试中,研究人员发现:
进一步增加特定类型的长文本数据,并不能带来额外性能提升。
这表明:在64k长度的上下文任务中,仅使用NoPE编码、更长的训练序列以及更高的RoPE的theta值,已足以让模型取得优异表现。
此外,借鉴Qwen2.5,在推理阶段,这次采用YARN技术,将上下文窗口从训练时的64k外推至128k,上下文扩展了2倍。
为了进一步注入通用推理能力,还有一项训练:推理中间训练。
与预训练和后续微调不同,这一阶段不面向任何特定领域,而是着重培养模型的通用推理能力。
此阶段使用了总计350亿个token数据,主要来自两个来源:
OpenThoughts3-1.2M,以及Llama-Nemotron-Post-Training-Dataset-v1.1数据集中的一个子集,其中包含R1标注的推理轨迹。
为了减少对模型结构的显式引导,这次采用ChatML格式的对话模板,并通过packing技术压缩了数据。
总训练量约为1400亿token。
最终模型的checkpoint将用于后续的指令微调(SFT)阶段。
随着DeepSeek R1等推理模型的推出,推理为模型带来的强大表现已获业界公认。
但至今缺乏构建双指令模型(同时支持推理与非推理模式)的完整开源方案。现有方法多依赖复杂强化学习流程与私有数据,严重阻碍研究人员复现与再开发。
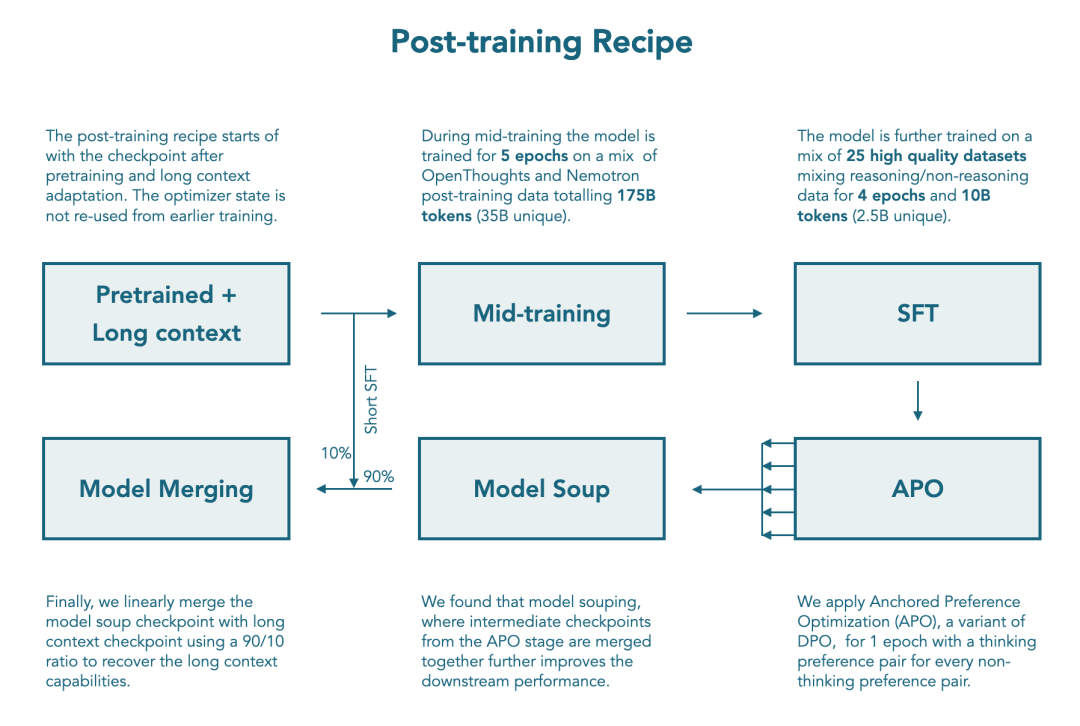
此次,HuggingFace公开了双模式指令模型的完整构建方案。
训练流程从注入通用推理能力的中间训练起步,融合合成数据监督微调(SFT),再通过基于DPO改进的Anchored Preference Optimization(APO)实现偏好对齐。
这套精心设计的多阶段流程,在推理与非推理模式间,成功达成了性能平衡。
SmolLM3双模式模型通过聊天模板与用户交互,允许用户精确控制推理模式。(和Qwen3一样)
用户可以用/think或/no_think切换推理与非推理模式。
此外,SmolLM3支持工具调用。
聊天模板还包括默认系统消息和元数据(如日期、知识截止时间、推理模式),并允许用户自定义或禁用元数据显示,灵活适配不同场景。
在完成中间训练后,团队继续对SmolLM3进行监督微调,以增强其在推理与非推理两种模式下的综合能力。
目标覆盖数学、编程、通用推理、指令跟随、多语言处理以及工具调用等任务。
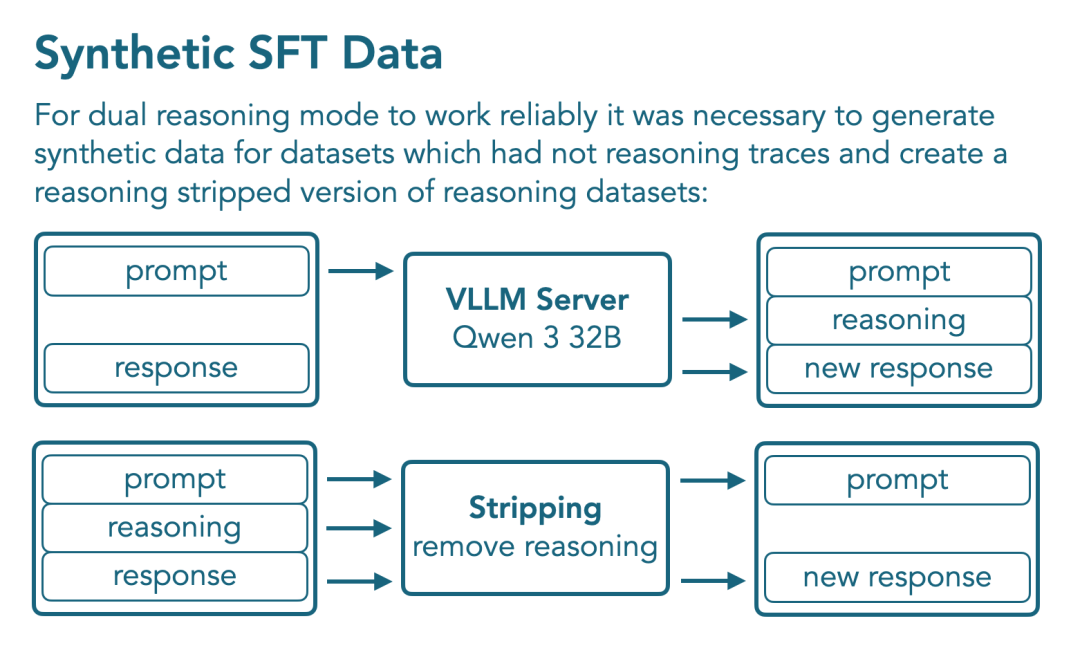
核心挑战在于:部分任务领域缺乏带有推理轨迹(reasoning traces)的标注数据。
为弥补这一空缺,他们使用Qwen3-32B以推理模式重新生成了非推理数据集的提示,从而构建出合成推理数据。
在整个监督微调过程中,还对各类数据进行细致调配,以确保模型保持稳健的性能。
在大量消融实验的基础上,最终构建的SFT数据集中共有18亿token,比例来源如下

为促进社区的研究与实践,他们将开源这套数据配比方案与完整训练脚本。
在完成监督微调后,模型进一步通过偏好学习进行了对齐训练。
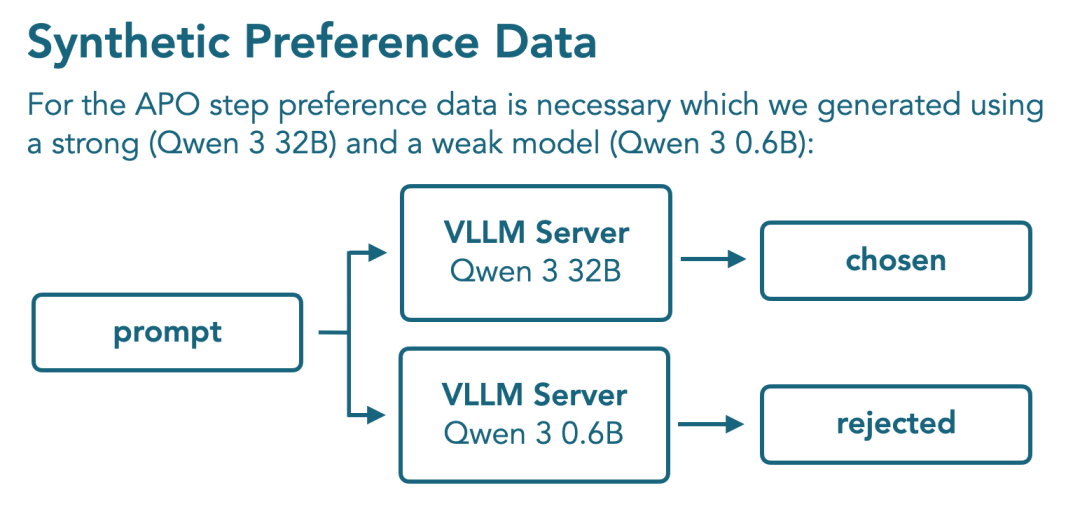
非推理模式和推理模式部分,分别采用了Tulu3的公开偏好数据集、Qwen3-32B和Qwen3-0.6B合成的一批偏好对。
在构建偏好数据时,他们选取Qwen3-32B的回答作为偏好对中的「选中答案」(chosen),而Qwen3-0.6B的回答作为「被拒绝答案」(rejected),并采用APO方法进行对齐训练。
对齐流程进一步统一了不同模式下的风格与偏好选择,为后续任务奠定了良好基础。
Anchored Preference Optimization(APO)是Direct Preference Optimization(DPO)的变体,但提供了更为稳定的优化目标。
在DPO中,在训练过程中,奖励函数rθ(x,y)衡量了模型生成序列的概率与训练初期参考模型之间的对数比值:
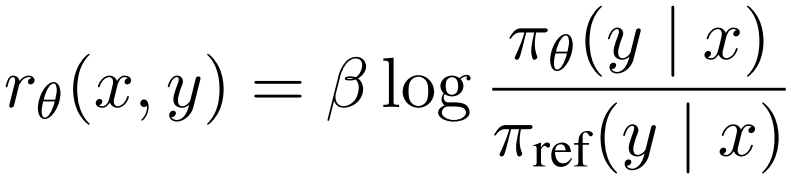
其中,β参数控制优化模型相对于参考模型的变化幅度。
DPO损失函数主要通过优化由提示x、选中回答y_w和被拒绝回答y_l组成的三元组来实现模型的改进。
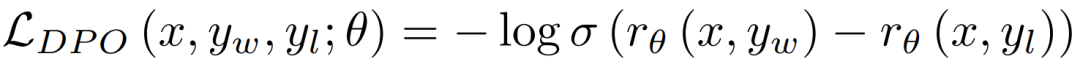
与DPO相比,APO目标在训练过程中更加稳定。
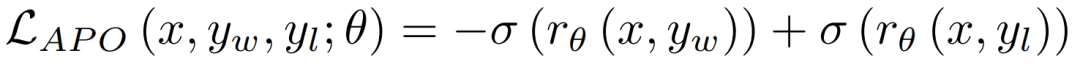
虽然在下游评估中,数学、科学、指令跟随、编程、对话和多语言任务均有显著提升,但在长上下文基准(如 RULER)上的表现却有所下降。
为此,团队追溯到推理中间训练阶段,发现模型长上下文处理能力有所损失。
此外,APO训练数据的上下文限制24k token。
为了解决这一问题并缓解性能下降,团队开始探索模型合并。
在不增加集成计算开销或无需额外训练的情况下,使用MergeKit合并APO检查点与长上下文训练checkpoint(权重0.9:0.1),兼顾推理对齐与长文本能力。
通过这种合并方法,在多个任务中,得到的模型保持了优异的表现。
接下来,请查看该模型与基础模型的评估结果。
在推理模式和非推理模式下,团队分别评估了基础模型和指令模型的表现。
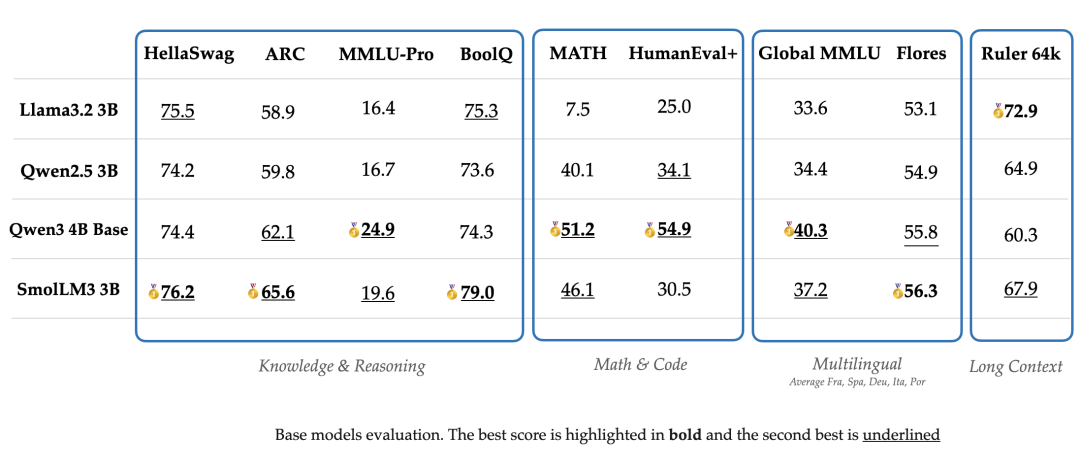
在各项任务中,SmolLM3始终优于其他3B模型,并且在与4B模型对比时也展现了强劲的竞争力。
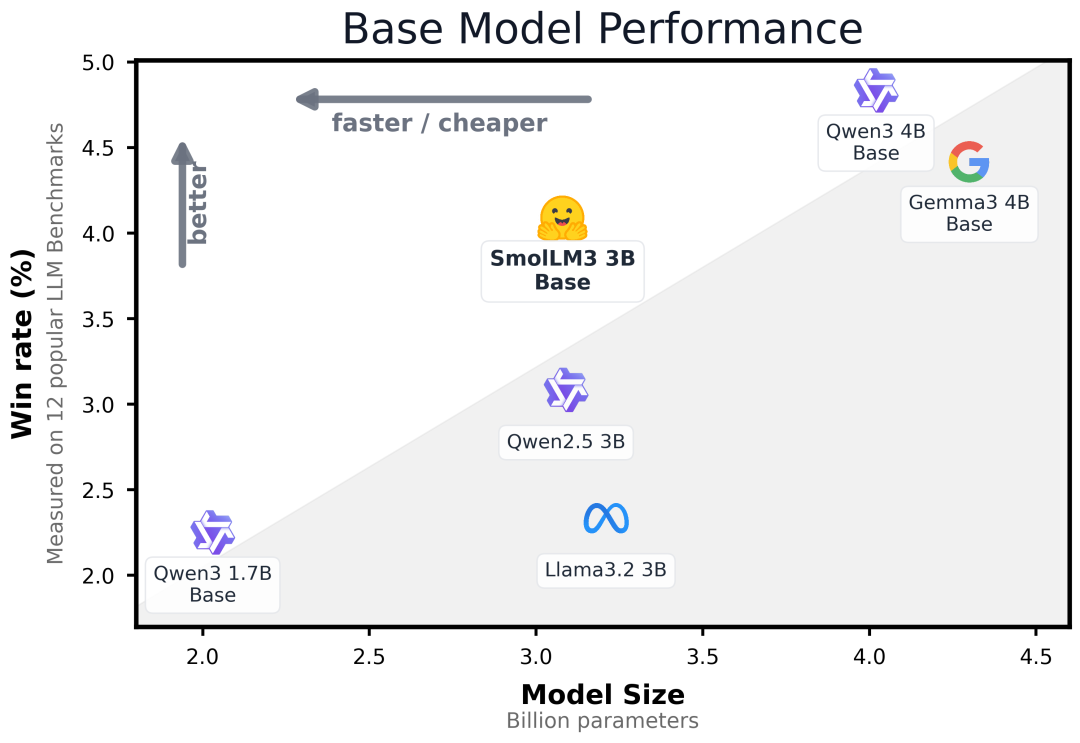
在知识和推理类基准测试中,SmolLM3取得了第一或第二名,数学和编程能力也表现不俗。
对于长上下文任务,在Ruler 64k基准测试中,SmolLM3表现突出。
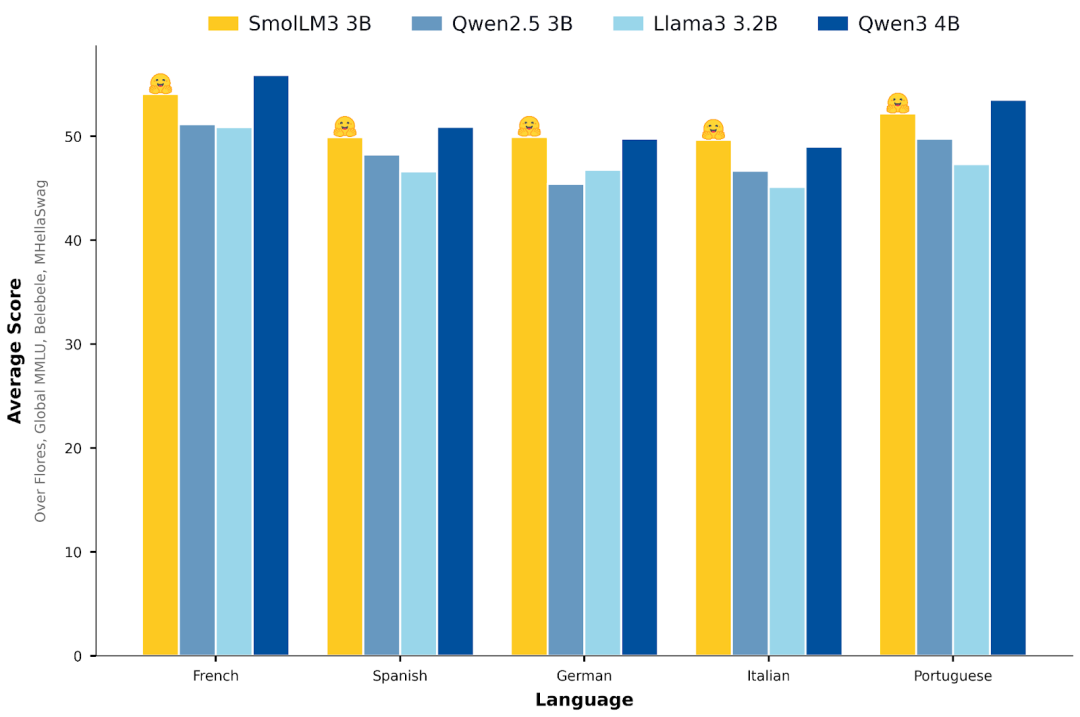
在五种主要欧洲语言的基准测试中,它也展现了强大的能力,涵盖Global MMLU、MLMM HellaSwag、Flores-200和Belebele,内容包括知识、常识推理、文本理解和翻译能力。
这表明在英语之外的语言中,SmolLM3同样保持了一致的优异表现。
总体而言,基础模型在多个领域展示了卓越的表现。接下来,让我们看看这些优势如何转化到指令模型的表现上。
SmolLM3同时支持指令模式和推理模式,需要分别评估其表现,并与具备相同能力的其他模型做比较。
非推理模式评估
SmolLM3与其他3B非推理模型进行了比较,并在多个基准测试中,与Qwen3推理模型在无推理模式下进行对比。
正如下图所示,SmolLM3在推理能力和效率之间找到了最佳平衡点。
在计算成本较低的情况下,SmolLM3显著超越Qwen3 1.7B,并接近4B模型的性能,领先于测试的其他3B非推理模型。
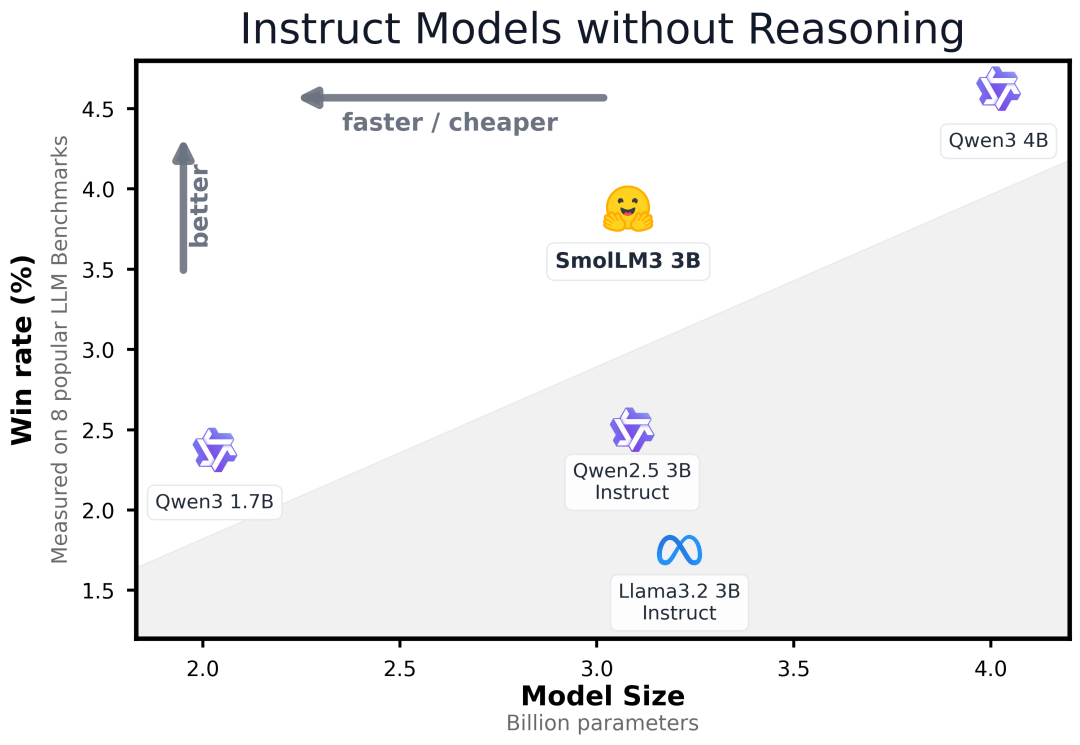
指令模型在性能和成本之间找到了最佳平衡点。扩展推理评估
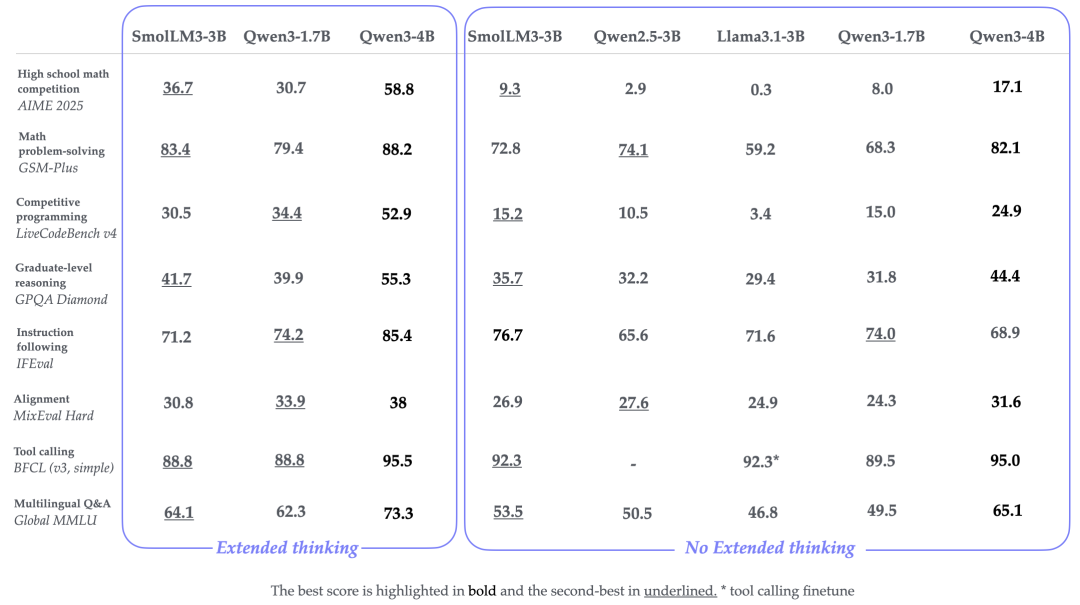
在启用扩展推理后,继续评估了SmolLM3的推理表现。
与非推理模型相比,SmolLM3在大多数基准测试中取得了显著进展。
在一些具有挑战性的任务中,研究人员观察到了显著提升,例如AIME 2025(36.7%对比9.3%)、LiveCodeBench上的竞争性编程(30.0%对比15.2%)以及GPQA Diamond上的研究生级推理(41.7%对比35.7%)。
尽管在推理和非推理模式下,Qwen3-4B通常能够获得最高分数,但SmolLM3在3B参数类中依然展现出了竞争力,特别是在数学推理和复杂问题解决任务中表现突出。
最后一个问题是:如何使用这个模型?
SmolLM3的模型代码已在transformers v4.53.0中发布,确保您已升级到该版本的transformers。
pip install -U transformers
还可以通过最新版本的vllm加载该模型,vllm使用transformers作为后端。
from transformers import AutoModelForCausalLM, AutoTokenizermodel_name = “HuggingFaceTB/SmolLM3-3B”device = “cuda” tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained( model_name,).to(device) prompt = “Give me a brief explanation of gravity in simple terms.”messages_think = [ {“role”: “user”, “content”: prompt}]text = tokenizer.apply_chat_template( messages_think, tokenize=False, add_generation_prompt=True,)model_inputs = tokenizer([text], return_tensors=”pt”).to(model.device) generated_ids = model.generate(**model_inputs, max_new_tokens=32768) output_ids = generated_ids[0][len(model_inputs.input_ids[0]) :]print(tokenizer.decode(output_ids, skip_special_tokens=True))
默认情况下,扩展推理模式已启用,因此上述示例会生成带有推理轨迹的输出。
要启用或禁用推理模式,在系统提示中使用/think或/no_think标志,如下所示。
生成带扩展推理的代码步骤相同,唯一的区别在于系统提示应为/thin而不是/no_think。
prompt = “Give me a brief explanation of gravity in simple terms.”messages = [ {“role”: “system”, “content”: “/no_think”}, {“role”: “user”, “content”: prompt}]text = tokenizer.apply_chat_template( messages, tokenize=False, add_generation_prompt=True,)
SmolLM3支持工具调用!
只需将工具列表传递到xml_tools(标准工具调用)或python_tools(调用如Python函数的工具)参数中。
from transformers import AutoModelForCausalLM, AutoTokenizercheckpoint = “HuggingFaceTB/SmolLM3-3B”tokenizer = AutoTokenizer.from_pretrained(checkpoint)model = AutoModelForCausalLM.from_pretrained(checkpoint)tools = [ { “name”: “get_weather”, “description”: “Get the weather in a city”, “parameters”: {“type”: “object”, “properties”: {“city”: {“type”: “string”, “description”: “The city to get the weather for”}}}}]messages = [ { “role”: “user”, “content”: “Hello! How is the weather today in Copenhagen?” }]inputs = tokenizer.apply_chat_template( messages, enable_thinking=False, # True works as well, your choice! xml_tools=tools, add_generation_prompt=True, tokenize=True, return_tensors=”pt”)outputs = model.generate(inputs)print(tokenizer.decode(outputs[0]))参考资料:https://x.com/LoubnaBenAllal1/status/1942614508549333211https://HuggingFace.co/blog/smollm3
本文由人人都是产品经理作者【新智元】,微信公众号:【新智元】,原创/授权 发布于人人都是产品经理,未经许可,禁止转载。
题图来自Unsplash,基于 CC0 协议。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。