掌握AI模型的核心特性是產品經理打造優質AI產品的關鍵。本文深度解析GPT-Image2生圖模型的應用技巧,從提示詞設計到性能優化,揭秘3000+次調用實戰經驗。你將學習如何規避常見尺寸錯誤、提升生成穩定性,以及通過中轉站策略將成功率提升至96%的實戰方法論。

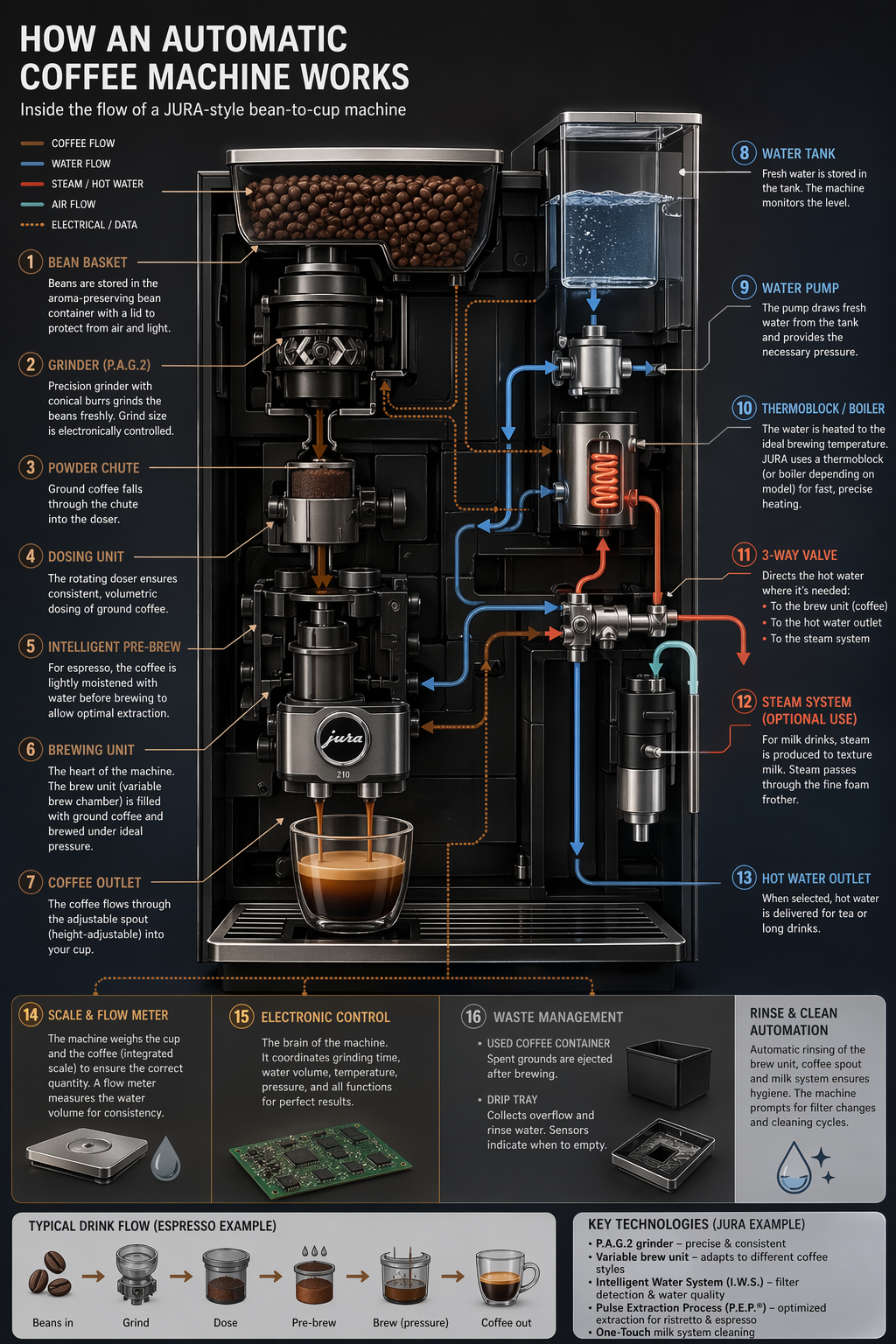
「一個出色的AI產品經理或者氛圍編碼者(vibe coder),一定是充分的了解並深度的使用模型的人!」這是我一直以來的觀點,因為產品經理和普通使用AI的用戶不同,產品經理是要運用模型締造產品的,所以你對模型的理解和使用的上限,決定了你做出來的產品能力上限。
所以不管是對我自己,或者是對身邊想要學習轉型AI產品的同學,我都有一個建議,必須深入的去看官方對於模型的說明文檔和技術文檔,並且在使用模型的過程中摸清楚模型的脾氣和特點。
至今為止,目前有2個模型是我在自己開發的產品中高頻的調用,一個是gemini 3.1 Pro,另一個是生圖模型GPT-Image2,每個模型的個人調用生成的次數,應該累計不低於3000次,今天這篇打算深度的復盤一下自己這段時間對GPT-image2這個模型的理解和使用經驗,這也是我在開發點讚AI這個圖文筆記創作AI工具的這段時間解決了不少技術問題的過程中積累下來的經驗,它有兩個作用:
以下內容總結來自兩部分來源:
https://developers.openai.com/cookbook/examples/multimodal/image-gen-models-prompting-guide

在開發點讚AI這個產品的過程中,我有一個實現場景,要將一段3000字以上的文本,一次性批量生成8~10張小紅書封面卡片,在這個過程中,我高頻的遇到如下幾個生成異常的問題:
1.image2的生圖尺寸是有特定要求的

這點可能很多人都不知道,比如可能就有人在生成圖片的時候要求輸出4000×4000這種尺寸的圖片,外行人看不出問題,內行人一看就知道有問題。根據OpenAI中關於image2的官方說明,image2的輸出尺寸有特定要求,相關要求如下:
另外官方還分享了一個經驗,一旦尺寸超過 2560×1440(≈3,686,400 像素,也就是”2K”)生成結果就容易不穩定,因此生成尺寸限定在 ≤2K(≈3.69M 像素)就是一個比較”可靠區間”,一旦結果設置為2K~4K ,生成結果則”能出但容易飄”。
基於以上這幾點,就可以理解前面自己遇到的問題的原因,比如生成的尺寸不是3:4,很可能是因為自己除了限定了比例,也限定了具體的尺寸,比如1500×2000(問題:尺寸不是16的倍數);以及生成結果質量不穩定,有可能是因為輸入的文字內容太長,導致展示的內容尺寸被迫撐大超過2K,超過2K的時候,就容易不穩定。
因此,在設計提示詞的時候,輸出尺寸必須要遵循以上規則,否則就容易出現這那的問題;
2.提示詞結構建議:
3.在提示詞中註明預期的用途
比如生成圖片是用於廣告、UI模型、信息圖,會有利於提高生成結果準確性;
4.在提示詞中標明quality的level值
包括低、中、高,這三個會影響畫質,當然也影響生成速度,對於文字密集、資訊比較多的場景,可能用中、高更好;
5.多圖輸入情況下:通過索引和描述引用每個輸入(“圖像 1:產品照片……圖像 2:樣式參考……”),並描述它們如何交互(“將圖像 2 的樣式應用於圖像 1”),比如前面我提到的多個墊圖情況下模型容易混淆的問題,通過這個方式就可以解決;
6.善用n參數,控制生成方案數量;
7.不要把判定規則寫到提示詞中,盡量減少生圖模型裡面的推理負擔
舉個例子,比如我之前有一版生圖的提示詞,要求模型根據生成宮格的數量(四宮格或九宮格等)判斷輸出尺寸,不同的宮格輸出不同的尺寸,我一開始的做法是把整個規則表放到提示詞裡面讓模型自己判斷應該輸出什麼尺寸。
但是這種方式導致的結果就是生成尺寸經常出問題。後來我換了一個方式,改成通過程式自己先確定輸出的宮格數量和尺寸,然後直接透過參數的方式,將宮格數量和生成的尺寸直接透傳插入到提示詞裡面,這個方式的生成結果相比之前的方式穩定了很多。
8.一個通用小技巧:優化提示詞最簡單直接的方式就是,把如下這段官方要求發給模型,讓模型根據這個要求,幫你修改你的提示詞。
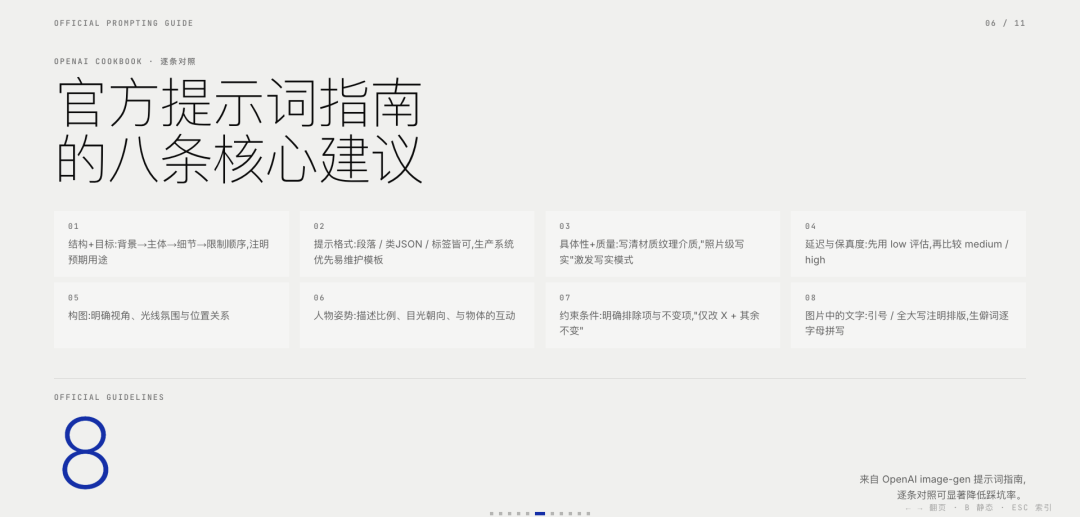
以下為image2的官方提示詞建議:
結構+目標:提示語應按一致順序編寫(背景/場景 → 主體/目標→關鍵細節→限制條件),並註明預期用途(廣告、UI模型、資訊圖),以確定「模式」和潤色程度。對於複雜的需求,請使用簡短的帶標籤的段落或換行符,而不是一個長段落。
提示格式:使用最易於維護的格式。只要意圖和限制清晰,簡潔的提示、描述性的段落、類似JSON的結構、指令式的提示以及基於標籤的提示都可以很好地發揮作用。對於生產系統,應優先考慮易於瀏覽的模板,而不是複雜的提示語法。
具體性+質量提示:明確描述材質、形狀、紋理和視覺媒介(照片、水彩、3D渲染),僅在必要時添加針對性的「品質控制點」(例如,膠片顆粒、紋理筆觸、微距細節)。對於照片級寫實效果,直接在提示中包含「照片級寫實」一詞,以強烈激發模型的寫實模式。類似「真實照片」、「使用真實相機拍攝」、「專業攝影」或「iPhone照片」等短語也有幫助,但詳細的相機規格可能會被隨意解讀,因此主要用於營造整體視覺效果和構圖,而非精確的物理模擬。
延遲與保真度:對於對延遲敏感或高容量的應用場景,請先使用 quality="low" 評估其是否滿足您的視覺需求。在許多情況下,它能夠在顯著提高生成速度的同時提供足夠的保真度。對於小字或密集文字、精細的資訊圖表、特寫肖像、涉及身分資訊的編輯以及高解析度輸出,請先使用 medium 再與 high 比較,再決定是否發貨。
構圖:
明確構圖和視角(特寫、廣角、俯視)、透視/角度(平視、低角度)以及光線/氛圍(柔和漫射光、黃金時段、高對比度)以控制拍攝效果。如果佈局至關重要,請註明位置(例如,「標誌位於右上角」、「主體居中,左側留白」)。
對於廣角、電影感、弱光、雨景或霓虹燈場景,請添加關於比例、氛圍和色彩的額外細節,以免模型為了追求表面真實感而犧牲氛圍。人物、姿勢和動作:對於場景中的人物,請描述其比例、身體構圖、目光以及與物體的互動。例如:「全身可見,包括雙腳」、「相對於桌子來說像個孩子」、「低頭看著打開的書,而不是看著鏡頭」,或者「雙手自然地握住車把」。這些細節有助於展現人物的身體比例、動作幾何以及目光方向。
約束條件(哪些需要更改,哪些需要保留):明確說明排除項和不變項(例如,「無水印」、「無額外文字」、「無徽標/商標」、「保留標識/幾何/佈局/品牌元素」)。
對於編輯操作,請使用「僅更改X」+「保持其他所有內容不變」的規則,並在每次迭代中重複保留列表以減少偏差。如果編輯需要精確到極致,還應說明不要更改飽和度、對比度、佈局、箭頭、標籤、相機角度或周圍對象。
圖片中的文字:
將文字用引號括起來或全部大寫,並指定排版細節(字體樣式、大小、顏色、位置)作為約束條件。
對於難以辨認的詞語(品牌名稱、不常用拼寫),逐個字母拼寫出來以提高字符準確性。
對於小字、資訊密集的面板和多字體佈局,請使用高亮顯示 medium 或高質量顯示。
high 多圖輸入:通過索引和描述引用每個輸入(「圖像1:產品照片……圖像2:樣式參考……」),並描述它們如何交互(「將圖像2的樣式應用於圖像1」)。合成時,明確指出哪些元素移動到哪裡(「將圖像1中的鳥放到圖像2中的大象身上」)。
疊代而非重複:冗長的提示固然有效,但從一個簡潔的基礎提示開始,然後透過小的、每次只做一項修改的後續提示(例如「讓光線更暖」、「移除多餘的樹」、「恢復原始背景」)進行細化,會更容易除錯。使用「與之前相同的風格」或「主題」之類的參考資訊來利用上下文,但如果提示開始偏離主題,則需要重新指定關鍵細節。
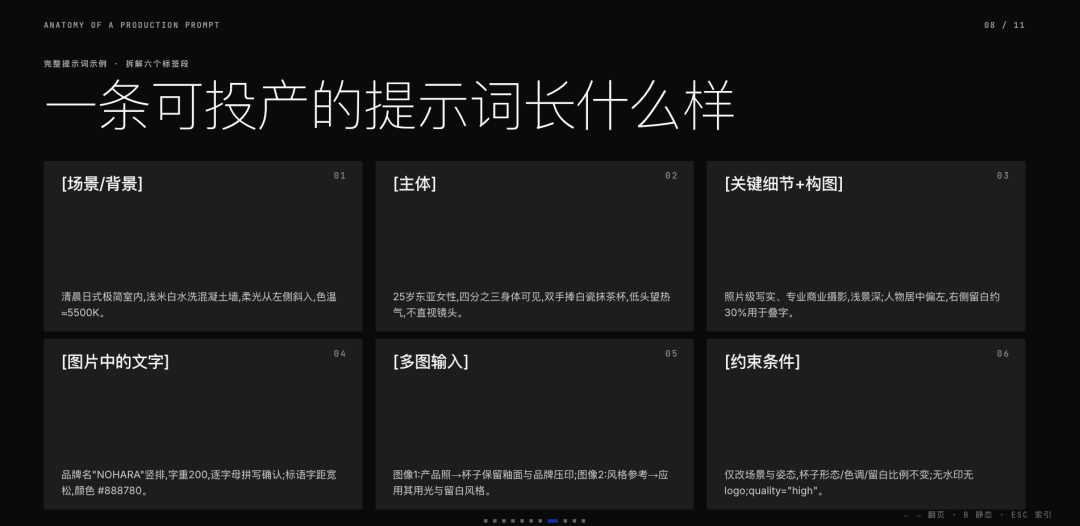
綜合以上的這些要求,寫一個如下提示詞作為範例,該範例基本彙總了以上需要關注的提示詞設計注意事項:
用途:社交媒體品牌廣告圖,尺寸1080×1600px[場景/背景]清晨的日式極簡室內空間,淺米白色水洗混凝土牆面,柔和漫射自然光從畫面左側斜入,無強硬陰影,整體色調偏暖(約5500K)。
[主體]一位25歲左右的東亞女性,四分之三身體可見(含雙手與手腕),雙手自然捧住一隻白色啞光陶瓷抹茶杯,低頭望向杯中冒出的熱氣,不直視鏡頭。身穿寬鬆米白色麻質上衣,髮型簡單束起。
[關鍵細節]
-視覺媒介:照片級寫實,使用真實相機拍攝,專業商業攝影
-材質與紋理:陶瓷杯表面細膩啞光釉面,杯口有少量抹茶粉末殘留;女性手部皮膚自然,可見毛孔細節,無過度修飾
-景深:淺景深虛化背景,對焦點落在杯口與女性下半面部
[構圖]平視角度,人物居中偏左,右側留出約30%畫面寬度的乾淨留白用於文字疊加;畫面下方留出約10%底部邊距。
[圖片中的文字]
-品牌名:「NOHARA」置於右側留白區上方,豎向排列,細線無襯線字體(字重200),字號約為畫面高度6%,顏色 #2C2C2A 拼寫逐字確認:N-O-H-A-R-A,共6個字母-標語:「EVERYSIP, A STILLNESS」置於品牌名正下方,字號更小,字間距寬鬆,顏色 #888780
[多圖輸入]
-圖片1:NOHARA 產品官方照(白色陶瓷杯正面) → 將此杯作為女性手中所持的杯子,保留杯子的型態、釉面質感和杯身品牌壓印
-圖片2:風格參考圖(日本 MUJI 系列廣告大片) → 將圖片2的用光方式、低飽和暖色調和構圖留白風格應用到本次生成 → 保持圖片1的產品可辨識性完全不變
[約束條件]
-僅改變場景環境和人物姿態——保持圖片1杯子的型態、品牌壓印、釉面顏色完全不變
-保持圖片2的色調、飽和度和用光邏輯不變-無浮水印、無額外文字、無商標 logo、無道具擺拍感
-不改變構圖留白比例,不改變人物面部朝向(始終低頭不直視鏡頭)
人物面部自然真實,無過度美顏,無濾鏡感品質="高"
生成時間、流暢度、失敗率的問題,也是我在開發點讚AI的過程中經常遇到,而且很頭痛的問題,比如我經常會遇到圖片生成了十幾分鐘都沒有生成出來的問題,以及生圖失敗率比較高的問題。
這幾點困擾了我很久,直到最近特意花了點時間研究了一下,總算能很好的解決這個問題,平均一批圖片生成的時間從5~10分鐘,提升到2分鐘以內,生圖成功率從80%提升到96%,總結經驗如下:
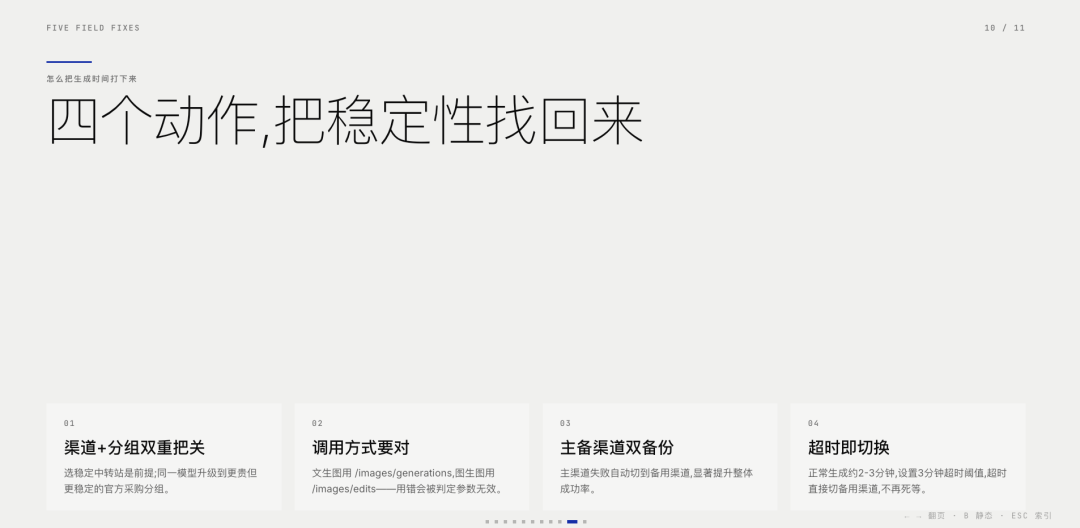
挑選穩定和可靠的中轉站:這個是前提,有些中轉站本來就不穩定,生成的失敗率容易很高,並且速度也比較差,所以挑選好的渠道中轉站是第一件事,關於中轉站的挑選相關的問題,後面我會單獨寫一篇,這裡先不細細展開;
採用合適的生圖模型調用方式:比如之前有一段時間,我的生圖產品的失敗率非常高,出現了高頻的失敗情況,生成速度也很慢,後來細查原因才發現是模型的調用方式不對導致的,這個也是官方調用方式的一些限制要求,目前image2的官方調用方式有兩種:
方式一:採用/images/generations的調用方式,該方式是適合文生圖模式;
方式二:採用/images/edits,該方式適合圖生圖模式;
我之前出現的問題就是,圖生圖的模式,使用了/images/generations的調用方式,所以中轉站那邊高頻的反饋無效參數問題;
模型使用更加穩定的分組資源:熟悉中轉站的同學一定比較了解分組這個東西,簡單講,中轉站的每一個模型,都有指定的分組,不同的分組可以理解為模型資源的來源,有些資源是渠道透過官方渠道薅羊毛的,比較便宜,有些資源是走官方渠道正經採購的,會貴一些,但是比較穩定;所以在模型分組上添加更貴的分組,可以一定程度上解決以上問題。
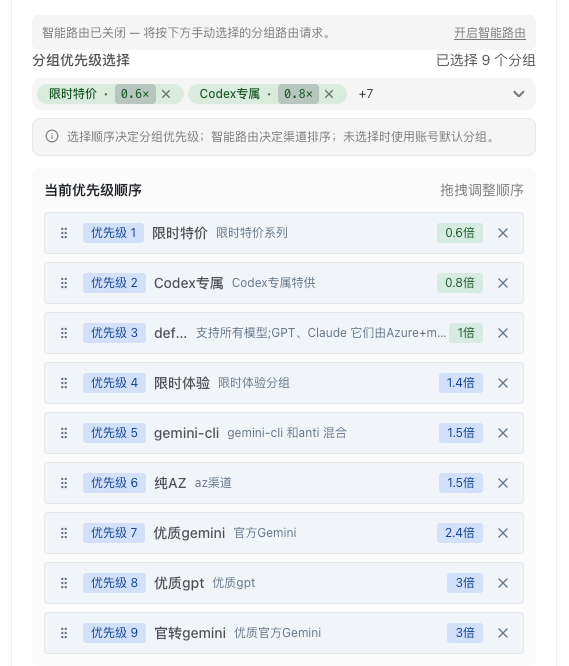
採用多個中轉站渠道備案的方式:因為中轉站渠道經常容易出現限流而不穩定的情況,因此備用多幾個中轉站渠道就很有必要,而且在渠道的調用機制上,可以設置主渠道和備用渠道,一旦主渠道調用失敗,就切備用渠道,由此可以提升生成結果的穩定性和成功率;
設置超時切換備用渠道的調度方式:前面提到了主渠道和備用渠道的邏輯,但是什麼時候切換備用渠道,這裡也有一些講究,正常模型如果生成成功或者失敗,渠道是會有response信息響應的,但是很多時候,渠道出現了問題,該響應一直處於loading狀態,渠道沒有返回響應信息,就會導致一直處於生成中狀態無限loading;
這時候可以設置一個超時的邏輯,一旦超過指定時間,即使沒有response信息,也直接切換備用渠道。根據個人經驗,目前穩定的渠道image2的生成時間通常是2~3分鐘左右,超過3分鐘,一般就是調用失敗,所以超時時間可以設置3分鐘。
這個也是你在只用image2的時候必須知道的事情,而且必須看官方公開的生成演示案例,說白了,模型是人家提供的,能生成什麼,官方說的最有代表性,相應的,沒有哪一個模型是萬能的,通過這些信息,也能知道模型的能力邊界情況。
根據官方公開的資料顯示,image2可以適合如下應用場景的生成。
1.將高信息密度的文本內容生成可視化圖表
比如如果是官方示例的生成效果:
2.圖片翻譯:該場景很適合PPT翻譯的場景,用戶的需求是保持PPT原本的設計,然後將文字進行翻譯
其關鍵效果在於可以保留除文本以外的所有內容,包括保持字體樣式、位置、間距和層級的一致性——同時逐字逐句地準確翻譯,不添加任何多餘的詞語,除非必要,否則不進行重排,並且不會對徽標、圖標或圖像進行任何意外的修改,除了PPT翻譯的場景,還可以用於將現有設計(廣告、用戶界面截圖、包裝、信息圖表)本地化為另一種語言,而無需從頭開始重建布局。
3.生成帶真實的相機拍攝參數的實拍效果圖
image2支援你提供使用攝影術語中的鏡頭、光線、構圖等相關的描述,你甚至可以把攝影中的參數(包括光圈、K值、快門等)告訴模型,模型幫你渲染出效果圖,同時還可以明確要求展現真實的紋理(毛孔、皺紋、衣物磨損、瑕疵)等。

4.需要世界知識的生成場景
GPT圖像生成模型能夠將強大的推理能力與世界知識相結合,也就是說,有很多東西,你可能不需要告訴模型背景,它自己也能知道,比如你讓它生成特朗普的形象,它知道特蘭普是誰,也知道他長什麼樣子;
5.故事漫畫集、視頻畫板、視頻切片
image2具備很強的一致性能力,所以可以用它生成故事畫集,視頻的切片和分鏡等;

6.邏輯圖:將文本信息,通過邏輯圖、流程圖的方式展現出來
7.單頁PPT生成
除了生圖,image2也是一個很不錯的PPT生成模型,除了編輯不太方便,現在image2生成的PPT效果一點都不比那些專業的PPT生成工具差;
8.風格復刻和遷移的功能
參考某一張圖片的風格,生成相似風格的卡片,這個已經是我非常高頻在使用的一個能力。
9.虛擬服裝試穿
比如你可以提供商品圖和模特,然後生成試穿效果;

10.圖像消除/去背:image2還支援傳統的圖像編輯能力,包括去背和消除功能;

OK, 以上便是這段時間總結的關於image相關的知識和經驗,其實有很多資訊,OpenAI的官網都已經公開了,並且我其實也已經是第三次複習這個官網的內容。
前面兩次因為只是了解為主,沒有代入實際的使用經驗,所以沒有太大的共鳴,隨著使用的次數越來越多,以及經歷的問題越來越多,才發現,官方公開的這些經驗資訊,就是最好的學習素材,外面那些所謂的AI高手們,基本分享內容也不會超過這個框架,所以總結起來:官方解讀+應用實操,就是最好的學習方式。
我打算在第三次學習之後,接下來深度的使用這些掌握的經驗,除了解決目前我開發的產品的問題,也希望能增加更多的能力到產品中。
作者:三白有話說,公眾號:三白有話說
本文由 @三白有話說 原創發布於人人都是產品經理。未經作者許可,禁止轉載。
題圖來自Unsplash,基於CC0協議
此內容由慣性聚合(RSS閱讀器)自動聚合整理,僅供閱讀參考。 原文來自 — 版權歸原作者所有。