當AI遇上神經科學論文,萬字解讀的自動化革命正在上演。本文揭秘了一個名為Loop(Loop)的智能協議系統如何透過五步流程、獨立評審機制和客觀評價標準,將52篇論文的深度解讀工作量從104小時壓縮至近乎自動化完成。更關鍵的是,作者用實戰案例揭示了哪些任務適合AI自動化,哪些仍需人類創意的不可替代性——這是每個試圖用AI重塑工作流的產品人都必須掌握的邊界判斷。

我手上有 52 篇神經科學經典論文的 PDF。我想把每一篇變成一篇中文深度解讀文章——不是摘要,是萬字級別的、帶概念工具箱、帶數據引用、帶獨立判斷的完整解讀,輸出為自包含的 HTML 檔案。
手動做?第一篇花了我 2 小時,第二篇還是 2 小時。52 篇就是 104 小時,不現實。
讓 AI 做?一個 prompt 搞不定。這個任務有五步:讀 PDF 全文、規劃文章結構、撰寫內容、組裝 HTML、檢查品質。每一步都依賴前一步的結果,而且「檢查品質」這件事不能跳過——AI 寫的東西品質波動很大,你不檢查就不知道它漏了什麼。
所以我寫了一個協定(Protocol):告訴 AI 對每篇論文執行這五步,做完一篇檢查一篇,不過關就修改,改完再檢查,過了就下一篇。
這就是 Loop——不是跑一次祈禱結果好,而是跑完就檢查、不行就重來。
Loop 的核心不是「循環」這個動作,而是退出條件:什麼情況下算”夠好了,可以下一篇”?沒有退出條件的循環只是死循環。(當然不是說死循環沒有價值,現在死循環有死循環的價值
跑了三個 Loop 之後(兩個成功,一個失敗),我發現一個能跑起來的 Loop 由五個部分組成:
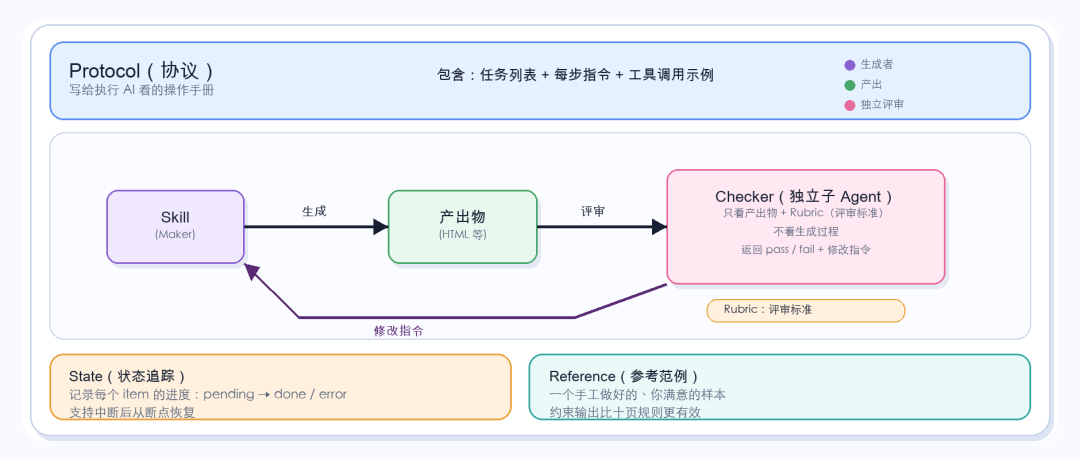
Protocol是寫給”沒見過這個項目的 AI”看的操作手冊。不是給你自己的備忘錄——路徑要寫絕對路徑,工具調用要給示例代碼,恢復邏輯要顯式寫明。判斷標準:如果你把這個文件發給一個完全不了解項目背景的朋友,他能不能照著跑起來?
這五個部分裡,最重要的是評審標準(Rubric)。
協議(Protocol)怎麼寫、狀態(State)用什麼格式、檢查器(Checker)怎麼調用——這些都是工程問題,花點時間就能搞定。但評審標準(Rubric)不一樣:它決定了「什麼算好」。評審標準(Rubric)清晰,循環(Loop)就順利;評審標準(Rubric)模糊,循環(Loop)就是在原地打轉。
我的論文解讀循環(Loop)之所以94%首輪通過,不是因為協議(Protocol)寫得多細,而是因為8條評審標準(Rubric)每一條都可以客觀判定——「術語有沒有中文翻譯」不需要主觀判斷,「HTML結構是不是.page > .layout > .main-content」看一眼 DOM 就知道。而我的微世界 Loop(循環)失敗,本質上是因為寫不出好的 Rubric(評量規準)——「這個預測問題是否能觸發認知衝突」無法客觀判定。
所以設計 Loop 的第一步不是寫 Protocol(協議),而是寫 Rubric。如果你能列出 5-10 條可以被一個陌生人(或陌生 AI)客觀判定 pass/fail 的標準,這個任務就適合 Loop。如果你列不出來,先別急著搭 Loop——先搞清楚你到底要什麼。
接下來三件事,就是我在圍繞 Rubric 搭建這個結構時踩過的坑。
設計 Loop 的第一個決定是:誰來檢查?
最直覺的做法是讓做事的 AI 自己檢查自己的輸出。很多教程也是這麼教的:在 prompt 裡加一句「現在忘掉你剛寫的內容,以一個嚴格評審員的身份重新審查這篇文章」。
我最初就是這麼做的。結果發現一個問題:它幾乎從不給自己打 fail。
原因很簡單——它知道自己的意圖。當它看到一個段落寫得含糊時,它能「腦補」出自己想說什麼,然後判定「雖然寫得不夠清楚,但意思到了」。它不是在評審一篇陌生的文章,它是在回憶自己幾秒鐘前的思考過程。
這就像讓一個學生批改自己的考卷——他知道自己想寫什麼,所以總覺得自己寫對了。
修復方法:用一個全新的、獨立的 AI 實例來做 Checker(檢查器)。在 Claude 裡,這意味著用 Agent(智能體)工具生成一個子 Agent(智能體)——它有自己獨立的上下文,完全沒見過主 Agent(智能體)的生成過程。給它的只有兩樣東西:
1. 生成好的 HTML 檔案
2. 八條評審標準(能不能獨立理解、數據是否精確、術語是否有中文翻譯、HTML 結構是否正確……)
它不知道這篇文章是怎麼寫出來的,不知道作者「想表達什麼」,它只看到成品。這才是真正的評審。
獨立上下文不是最佳化,是正確性要求。告訴同一個 Agent(智能體)「假裝忘記」不等於它真的忘了——上下文還在那裡,它的判斷必然受污染。這個錯誤在幾乎所有 Loop(迴圈)教程裡都存在,但很少有人點破。
協議寫好,跑起來。52篇論文全部完成後,我回頭看數據:
被打回的3篇分別是什麼問題?
三個全是同一類問題:特定專業術語沒有解釋全。
這說明什麼?
第一,Maker(生成器)本身已經夠好了。94% 的首輪通過率意味著論文解讀的技能(Skill)寫得足夠詳細,AI 不需要反覆修改就能產出合格的文章。如果你的檢查器(Checker)每次都攔住大量問題,說明你的製造器(Maker)需要重寫——不是多跑幾輪能解決的。
第二,檢查器(Checker)的真正價值是抓系統性遺漏。這三次 fail 都不是「文章寫得爛」,而是在某個具體知識點上有盲區。這種盲區靠主代理(Agent)自檢是發現不了的——因為它如果知道 CaMKII 需要解釋,當初就會寫進去。只有一個「不知道作者意圖」的獨立檢查器(Checker),才會客觀地發現「這裡出現了一個沒解釋的縮寫」。
第三,檢查器(Checker)的成本是可控的。3/52 = 5.8% 的重審率代表 Checker 子 Agent 平均每 17 篇才需要多花一輪的 token。這比「不檢查直接發布然後人工返工」便宜得多。
同一批 52 篇論文,我還嘗試過另一個 Loop:給每篇論文生成一個「互動式微世界」——不是讓讀者讀文章,而是讓讀者親自體驗論文的論證過程。比如 FFA 論文,做成一個淘汰賽遊戲:給你看臉和物體的 fMRI 資料,讓你預測結果,逐步排除替代假說。
我設計了完整的協定:5 種互動模式(淘汰賽、雙重分離、證據累積、模擬體驗、概念建構)、7 條 Checker 標準、詳細的 HTML 元件規範。從協定設計的角度看,它比論文解讀的 Loop 還完善。
AI 跑出了第一個產出。我看了一眼,直接否掉了整個 Loop。
不是因為產出有 bug,而是因為它不是我想要的東西。交互體驗的設計空間太大了——同一篇論文可以做成 100 種完全不同的交互方式,每一種都”符合協議”,但大多數都不是好的學習體驗。協議能約束格式(必須有預測點、必須有計分板、必須有自測題),但約束不住創意(什麼樣的預測問題能真正觸發認知衝突?什麼樣的交互節奏能讓人”啊哈”?)。
這就是 Loop 的適用邊界:Loop 能工作的前提是,輸出空間小到 Checker 能覆蓋。
論文解讀的輸出空間很大,但被技能(Skill)的10個固定章節 + 8條檢查器(Checker)標準壓縮到了可管理的範圍。代碼的輸出空間更大,但被測試用例壓縮到了「通過/不通過」。而「設計一個學習體驗」的輸出空間幾乎是無限的——你可以檢查它是否有預測點,但你無法檢查這個預測點是否「問得好」。
如果你的檢查器(Checker)只能檢查格式不能檢查內容質量,那這個任務可能不適合循環(Loop)。先手工做一個滿意的範例,確認你能說清楚「好」長什麼樣,再決定是否循環化(Loop化)。
循環(Loop)不難,難的是知道什麼時候該用、什麼時候不該用。
52 篇論文解讀告訴我:如果任務結構清晰、退出條件可檢查、有參考範例,Loop 的效果出奇的好——94% 首輪通過,剩下 6% 也在第二輪解決。總耗時從預估的 104 小時變成了"寫協議 2 小時 + 跑完等結果"。
但互動式微世界告訴我:如果任務本質上是創意性的,輸出好壞取決於品味而非標準,那再完善的協議也救不了你。這時候正確的做法不是設計更複雜的 Loop,而是承認這個任務需要人來做。
回過頭看,Loop 其實不是什麼 AI 時代的新發明。寫 Protocol 就是寫 SOP(標準作業程序),寫 Rubric 就是寫驗收標準,Checker 就是質檢,State 就是工單系統——這些東西在製造業和軟體工程裡存在了幾十年。變的只是執行者從人換成了 AI,以及因此帶來的一個新問題:怎麼讓一個沒有常識兜底的執行者在無人值守的情況下保持品質。所有關於 Loop 的技巧,歸根到底都在回答這一個問題。
知道邊界在哪,比知道怎麼寫 Loop 更重要。
本文由 @yan 原創發佈於人人都是產品經理。未經作者許可,禁止轉載
題圖來自 Unsplash,基於 CC0 協議
該文觀點僅代表作者本人,人人都是產品經理平台僅提供資訊存儲空間服務
此內容由慣性聚合(RSS閱讀器)自動聚合整理,僅供閱讀參考。 原文來自 — 版權歸原作者所有。