美國AI三巨頭OpenAI、Anthropic和Google正圍繞Context(上下文)展開激烈爭奪,這場競爭已從最初的長文本視窗擴展至Memory(記憶)、瀏覽器滲透等全新維度。本文深度剖析Context邊界的三次關鍵躍遷,揭示三家公司如何透過差異化路徑重構AI時代的護城河,從單純的模型能力較量轉向用戶資產沉澱與任務入口爭奪。

今年以來,美國 AI 三巨頭紛紛給自家模型產品貼上了一些「科幻」標籤。
OpenAI 說,ChatGPT 學會了「做夢」;Anthropic 要給 Claude 配一個內置的「個人 Wiki」;Google 則宣稱,讓 Gemini「原生自帶你十年的記憶」。
三種說法,看上去關係不大,其實是在競爭同一樣東西——Context(上下文)。
早期,Context 只是個不起眼的技術參數,衡量模型一次能讀進多少字元。如今,Context 的含義正在拓寬:它是用戶資產,是工具權限,也是任務進行到哪一步的即時狀態,更是AI 究竟有多了解你。
據統計,今年以來,OpenAI、Anthropic、Google 圍繞 Context 已發布 40 餘項重要產品和功能更新——平均每三四天,就有一項新能力被推向市場。
從長上下文視窗,到跨會話記憶,再到瀏覽器、桌面和 GUI 操作能力,過去兩年 AI 產品最重要的變化,幾乎都圍繞 Context 展開。
一場關於「Context」的戰爭已經打響,這也在悄然重構 AI 時代的護城河。
上下文最早的競爭,發生在「文本長度」上。
聊天機器人時代,上下文主要意味著模型一次能讀進多少資訊。視窗越長,模型越能處理論文、程式碼庫,甚至完整專案文件。於是,OpenAI、Anthropic、Google 掀起了一場上下文視窗的軍備競賽。
2023 年 5 月,Anthropic 率先把 Claude 的上下文視窗從 9K 拉到 100K,約等於 7.5 萬字,首次讓「上傳一整本書」成為現實。2023 年 11 月,OpenAI 用 GPT-4 Turbo 的 128K 跟進。三個月後,Google 又用 Gemini 1.5 Pro 把視窗推到百萬級。
不到一年,上下文從十萬級躍遷到百萬級。
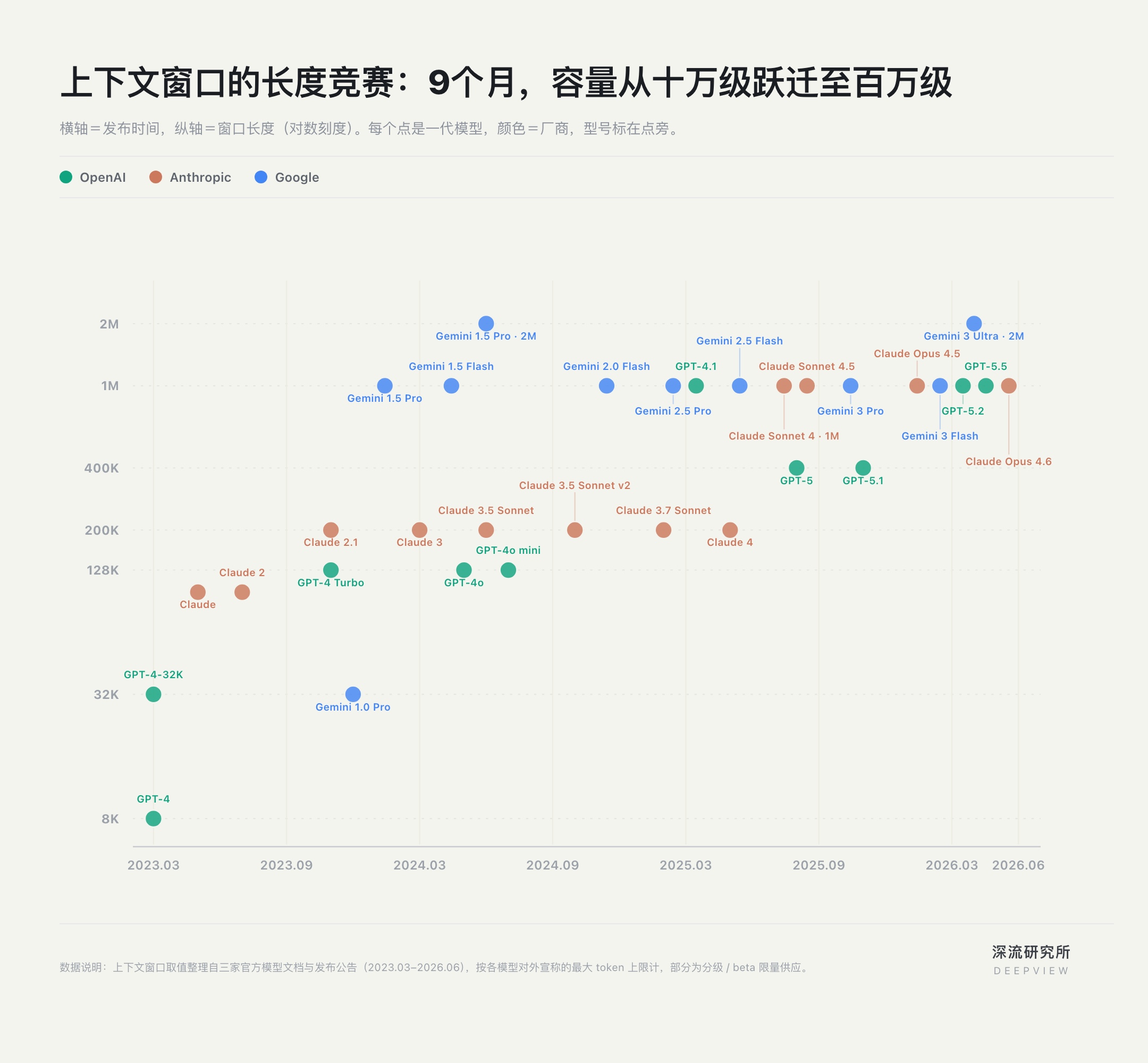
長視窗解決了 AI 的「吞吐量」問題,但這場競賽很快暴露出局限:模型能看到更多資訊,並不意味著它就能更好地理解任務。
尤其當 AI 產品從 Chatbot 走向 Agent,Context 的邊界開始變化。它不再只是一次對話裡的輸入文本,而是任務循環中持續積累、動態更新的狀態流。
競爭焦點也隨之轉移:從模型「一次能知道多少」,轉向模型「長期能記住什麼」。Memory 成為這一階段典型的產品形態。
2024 年初,OpenAI 率先為 ChatGPT 引入跨會話記憶,讓模型記住用戶的偏好、背景與長期需求。隨後,Anthropic 與 Google 也相繼補齊 Claude、Gemini 的記憶能力。
Context 開始擁有時間維度。AI 不再只處理當前輸入,也開始嘗試在用戶今天、上週、上個月的互動之間建立連續性。只有具備長期 Context 的 AI,才可能把離散的互動串成持續關係。
然而,Memory 回答的是「過去發生了什麼」,還沒有觸及另一個更關鍵的問題:現在正在發生什麼?
真正的分水嶺出現在 2025 年下半年。
這一年 8 月開始,三家公司幾乎同時把 Context 的戰線推向瀏覽器:Anthropic 發布 Claude for Chrome,Google 將 Gemini 嵌入 Chrome,OpenAI 則推出獨立 AI 瀏覽器 ChatGPT Atlas。
瀏覽器是天然的 Context 富礦。網頁內容、搜尋意圖、登入狀態、表單、歷史記錄、標籤頁,以及使用者正在執行的任務,都沉澱在瀏覽器裡。更重要的是,這裡的Context更即時、更連續,也更接近真實任務現場。
之前,AI獲取Context的方式,本質上仍然是等待使用者把材料送進來:上傳檔案、輸入指令、授權記憶、連接資料源。
進入瀏覽器之後,邏輯變了。AI開始進入使用者的工作環境,觀察頁面狀態,理解任務進度,捕捉操作意圖,並在真實介面中執行下一步。
這是Context邊界的第三次躍遷:它從模型側輸入的靜態資料,變成了Agent在GUI、網頁和系統環境中捕捉到的動態狀態。
長視窗決定模型一次能裝進多少資訊;Memory決定模型能否跨時間理解使用者;瀏覽器、桌面產品和GUI能力,則決定模型能否進入真實任務現場。
三者連在一起,構成了過去兩年 AI 產品競爭的主線:Context 不再只是模型能力問題,而逐漸變成產品入口問題、用戶關係問題,以及資產沉澱問題。
當 Context 從模型參數變成用戶資產,競爭的核心就變成了:誰能更穩定地獲得、組織和調用 Context。
圍繞這一點,OpenAI、Anthropic、Google 走出了三條差異化路徑。

ChatGPT 是 OpenAI 最核心的 Context 來源。
用戶在一次又一次對話中留下的記憶、偏好、歷史任務和工具調用記錄,逐漸沉澱到同一個 ChatGPT 帳戶之下。
這個帳戶不同於傳統網際網路帳戶。傳統帳戶記錄的是登錄狀態、訂閱關係和支付資訊;ChatGPT 帳戶記錄的,則是用戶「被 AI 理解過的歷史」。
這是一種 AI 原生的用戶資產。它的價值不只體現在回答更個人化,也體現在降低冷啟動成本、延續任務狀態,並在不同產品場景中復用同一套用戶理解。
對 OpenAI 來說,由於缺少 Google 那樣的原生數據生態,它必須讓用戶在 ChatGPT 體系內持續生成新的 Context。
因此,OpenAI 過去兩年的產品動作,一直在不斷擴大 ChatGPT 帳戶能夠覆蓋的任務半徑——Apps SDK 讓第三方應用進入 ChatGPT,Atlas 把瀏覽器納入 ChatGPT,最新融合的 Codex 則把編程任務帶入同一個工作流。
OpenAI 的特殊路徑在於,它不是先掌握入口,再把 AI 接進去;而是以 ChatGPT 為原點,反向把應用、瀏覽器、程式設計等場景拉回同一個帳戶體系。
ChatGPT 因此不再只是對話入口,而是一個匯聚、調用、更新上下文(Context)的中樞。
相比之下,Anthropic 既缺少 C 端入口,也沒有大規模存量用戶數據。
它的路徑,是切入 Coding、Agent 這類高價值垂直場景,並在這些場景中強化 Claude 主動獲取上下文(Context)的能力。
對 Claude 來說,上下文(Context)不是用戶輸入的一段文字,而是任務現場裡動態變化的環境:程式碼庫、檔案系統、終端輸出、瀏覽器頁面、資料庫、專案文件,以及每一步執行後的回饋。
因此,Anthropic 更強調上下文(Context)獲取的主動性。模型不應只等待用戶輸入,也應該在任務執行過程中主動進入環境、讀取狀態、獲得反饋。
2024 年 10 月,Anthropic 推出 Computer Use,讓 Claude 可以根據螢幕截圖移動滑鼠、點擊按鈕、輸入文字。
按照官方說法,Claude 3.5 Sonnet 是首個公開提供電腦使用能力的前沿 AI 模型。
這意味著,當 Context 存在於網頁、表單、後台系統和本地軟體介面中,而不是結構化 API 裡時,Claude 也可以透過 GUI 進入環境、觀察狀態並執行操作。
一個月後,Anthropic 發佈 MCP。這個連接 AI 助手與外部工具、資料源的開放協議,官方定義是把 AI 助手連接到「數據所在的系統」,包括內容庫、業務工具和開發環境。
它的價值在於,讓 Claude 不再依賴用戶複製貼上,而是可以透過標準方式接入外部工具和資料來源。
這兩類能力,對應的是 Anthropic 獲取 Context 的兩條路徑:
computer Use 透過 GUI 進入介面,MCP 透過協定連接系統。一個進入任務現場,一個打通外部工具,共同讓 Claude 獲得動態 Context。
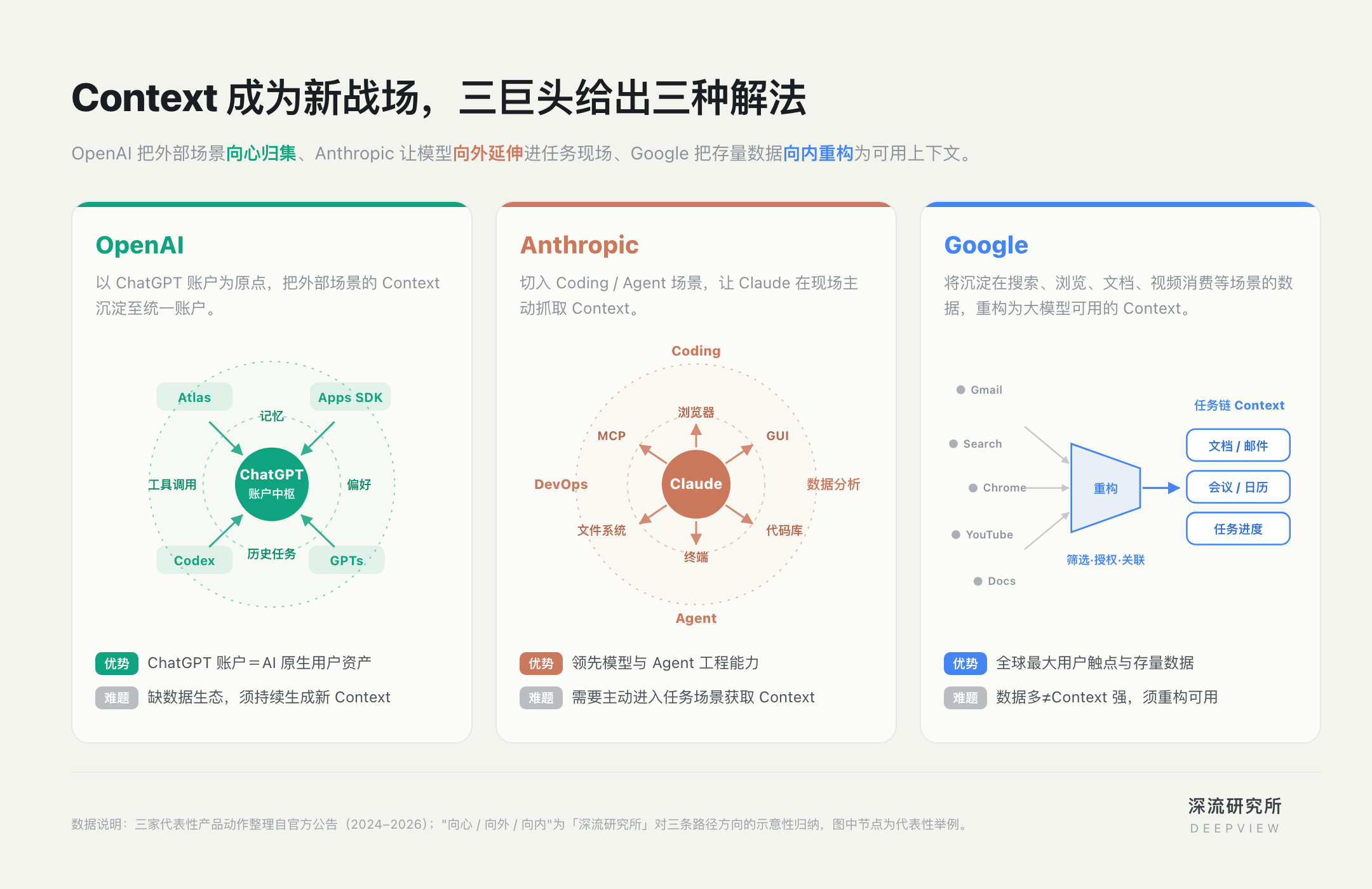
再看 Google。外界常說,Google 是擁有 Context 最多的公司之一。它不缺入口,也不缺資料。Chrome、Gmail、YouTube、Search 等產品,構成了全球範圍內最大的用戶接觸點之一。
但從 AI 的視角看,資料多並不等於 Context 強。
Google 過去累積的是搜尋、瀏覽、郵件、文件、位置、影片消費等數據,主要服務於搜尋排序、廣告投放、內容推薦和辦公協作。它們本質上是系統運作所需的行為訊號。
而 Agent 需要的是可被模型理解、推理和調用的任務背景。
只有當模型能判斷哪些資訊與當前任務有關、哪些已經過時、哪些可以被調用,以及這些資訊之間如何關聯,數據才真正變成 Context。
Google 面臨的不是簡單「接入數據」,而是一場數據重構。它需要把分散在不同產品、服務於不同系統目標的舊數據,重新篩選、關聯、授權,並轉化為 Gemini(gemini) 可用的個人上下文。
這個工程的難度,並不比 OpenAI 重新沉澱 Context、Anthropic 進入任務現場更低。
過去兩年,Google 的產品動作不是另起爐灶,而是沿著既有陣地向內改造。這條路徑的核心,是把碎片化數據組織成任務鏈。
2024 年 5 月,Gemini 1.5 Pro 進入 Workspace 側邊欄,讓模型先在 Gmail、Docs、Drive 等工作場景中調用當前上下文。
2025 年 7 月,Gemini app 開始連接 Gmail、Drive、Calendar 等工具,把 Context 從單個應用擴展到跨應用任務。
2026 年 1 月,個人智慧(Personal Intelligence)推出測試版,進一步把 Gmail、Photos 等個人數據納入 Gemini 的個性化背景。
Google 的 Context 戰略並不是「數據多,所以天然領先」。
它真正要完成的,是一場數據可用化工程:將過往沉澱的、服務於搜索、廣告和推薦等系統目標的行為數據,轉化為 AI 時代可理解、可授權、可行動的上下文。
過去兩年,OpenAI、Anthropic、Google 都在加速沉澱和挖掘上下文,並圍繞它構建獲取、組織和調用能力,試圖形成新的競爭壁壘。
但一個看似矛盾的變化也在同步發生:今年以來,三家公司不約而同地讓記憶變得透明、可解釋,甚至可遷移。
2026 年 3 月,Anthropic 與 Google 先後推出記憶導入,支持使用者在 ChatGPT、Gemini、Claude 之間遷移記憶。
隨後,OpenAI 透過 Memory Sources,讓用戶看到一條個人化回答背後呼叫了哪些記憶、歷史聊天或外部資料源。
如果 Context 是 AI 時代最重要的資產,為什麼平台反而開始開放它的權限?
答案在於,Memory Import 真正開放的,只是表層 Context:用戶偏好、歷史記憶摘要、對話歷史的壓縮版本。
這些資訊高度結構化,也容易被自然語言描述。遷移它們,技術門檻並不高。
真正難以遷移的,是另一類 Context:任務狀態、工具權限、企業系統接入、執行現場的即時回饋。
這些 Context 深度嵌在產品和系統環境之中,無法靠一段提示詞完整搬走。
這也說明,AI 時代的競爭邏輯,正不同於網際網路時代。
互聯網的基本形態是網路。它把人、內容、商品、服務和資訊連接成節點。節點越多、連接越密,產品越有價值。因此,互聯網時代最強的護城河是網路效應,價值來自更多人在用。
AI 的基本形態,更接近一種新的電腦,或者說新的資訊處理系統。
它的第一性價值不是連接更多人,而是理解資訊、處理任務、呼叫工具並完成動作。一個 AI 即使只服務一個用戶,也可能創造巨大價值。
因此,AI 時代的護城河,正在「網路規模」的基礎上轉向「個體縱深」。這種「個體縱深」的壁壘,主要來自三個層面:
第一,是上下文(Context)的複利。AI 每完成一次任務,都會更了解用戶的表達習慣、判斷標準、資料來源和工作流程。下一次執行時,冷啟動成本就會更低。
第二,是權限與工具鏈的嵌入。當用戶把郵箱、文檔、代碼庫等授權給 AI,AI 就不再只是一個可替換的問答工具,而是進入了真實的任務現場。
第三,是信任關係的形成。越複雜、越高價值的任務,用戶越不會輕易交給一個陌生 AI。只有長期理解自己、知道邊界、能延續上下文的 AI,才可能被允許執行下一步。
如果說網際網路產品爭奪的是注意力入口,那麼 AI 產品爭奪的就是任務入口。
一旦一個 AI 持續進入用戶工作流、積累上下文並獲得執行權限,遷移成本就不只是換一個應用,而是重新建立一套被理解、被授權、被信任的任務關係。
國內產品的變化,也可以放在這個邏輯下理解。
以騰訊為例,它在網際網路時代積累了關係鏈、內容、服務生態和高頻入口;到了 AI 時代,這些資產的價值,正在於能否被重新組織為代理可理解、可調用、可執行的上下文。
無論是 WorkBuddy 接入文檔、會議、企業微信等工作場景,還是微信「小微」嘗試在微信生態調用小程序和服務,本質上都是把原本服務於人的內容、關係和流程,轉化為 AI 可以進入的任務環境。
正如騰訊首席 AI 科學家姚順雨所判斷:上下文看似是數據資產,本質上卻是產品能力、工程能力和組織協同能力的綜合體現。
網際網路時代,護城河看的是規模。AI 時代,護城河更應該看轉化效率:
誰能把存量生態更快轉化為 AI 的工作環境,誰能讓 AI 在一次次任務中積累更深的用戶理解,誰就更可能建立新的壁壘。
這也是 Context 之戰真正值得關注的地方。
文 / 絳楓 公眾號:深流研究所
本文由 @深流研究所 原創發布於人人都是產品經理。未經作者許可,禁止轉載
題圖來自Unsplash,基於CC0協議
此內容由慣性聚合(RSS閱讀器)自動聚合整理,僅供閱讀參考。 原文來自 — 版權歸原作者所有。