在RAG產品的競品分析中,單純的功能清單對比已遠遠不夠。本文深度解析如何通過DDD子域劃分和Kano模型,重新定義RAG產品的分析框架。以百度千帆AppBuilder和Lyzr AI為案例,揭示RAG功能背後的產品邏輯和戰略考量,幫助產品經理在資源投入和功能分層上做出更精準的決策。

在分析 RAG 產品時,我們很容易陷入一種慣性:
這樣看似全面,但本質上仍然是在做功能清單對比。
它能回答“誰有這個功能”,卻很難回答:
這些功能為什麼會出現?
哪些功能是這類產品必備的基礎功能?哪個功能該作為重點開發的對象?
為什麼有些產品重點做知識解析,有些產品把重心放在檢索策略,又有些是強化效果評測?
就導致看了很多競品,但是到頭來還是一頭霧水。本文就來拆解該問題。
下面將以:
國內:百度千帆 AppBuilder
國外:Lyzr AI
作為分析對象,這二者都不是單純的面向技術型人員的的底層 RAG 引擎,而是面向 AI 應用 / Agent 搭建場景的產品平臺。它們的知識庫能力,分別體現了 RAG 在國內大模型應用平臺與海外 Agent 搭建平臺中的產品化方式。
RAG 架構通常與Agent智能體產品的中的知識庫功能密不可分,現在大多Agent產品中都採用該數據架構來幫助用戶將私有數據,快速轉化為Agent處理用戶問題的知識來源。
產品中RAG的處理流程可以總結為:沿著“知識進入系統—知識被處理—知識被檢索—知識被組織為回答上下文—答案被生成—效果被評估與優化”的處理流程逐步產品化的結果。
為了更好地解釋這件事,本文嘗試引入兩種方法:
最終形成一套分析框架:
從瞭解RAG架構中數據處理環節出發,再使用DDD 子域劃分和Kano模型二者結合的方式來分析現有的產品中的具體運用。DDD的子域劃分可以幫助我們識別:RAG 產品中哪些能力最值得成為資源投入重點,成為我們產品的差異化。Kano 模型幫助我們判斷:這些能力中的具體功能,哪些是行業門檻,哪些是提升滿意度的競爭點,哪些是差異化創新機會。
DDD,即領域驅動設計,最早用於複雜業務系統建模。對於產品分析來說,我們不需要把 DDD 中所有技術概念都展開,比如實體、聚合、倉儲、領域服務等。
本文就借用 DDD 的戰略設計視角:
微軟 Azure 架構文檔中也將領域分析、限界上下文等作為 DDD 建模微服務的重要步驟。對於我們進行產品分析而言,最有價值的是這兩層:先理解業務領域,再識別業務邊界與子域。
在本文中,可以簡單理解為:
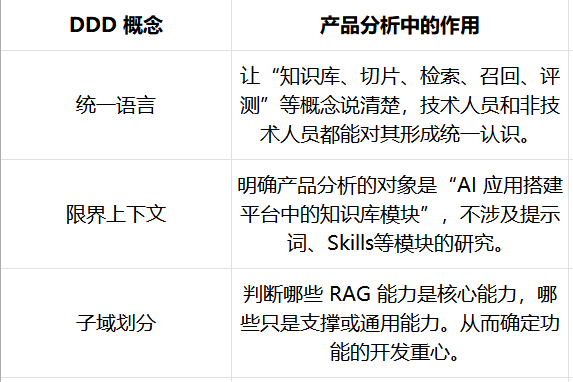
一句話總結,從產品視角看,DDD 主要幫助我們回答:資源應該重點投入在哪裡?

微軟與 AWS 的架構資料都強調,DDD 的戰略價值就在於:讓系統設計圍繞真正的業務能力,而不是圍繞技術模塊機械拆分。(Microsoft Learn)
Kano 模型它通常將需求分成五類:
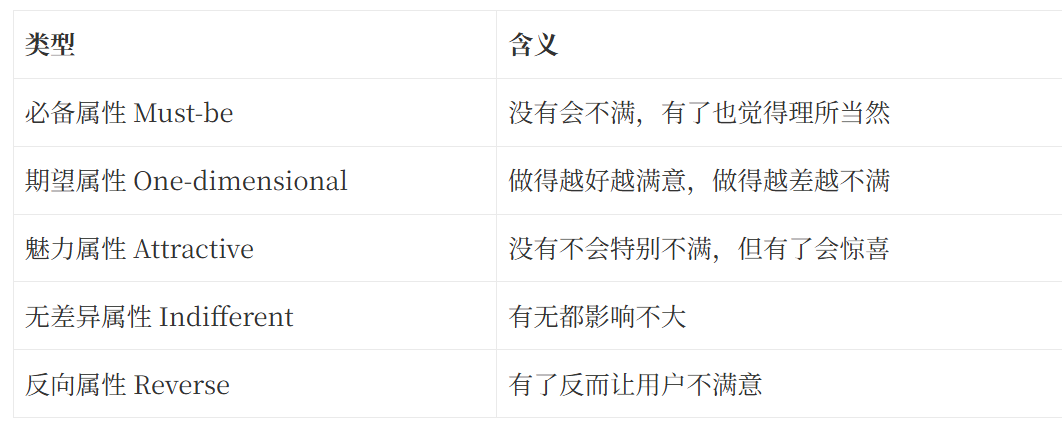
Kano 的價值在於,它不只是告訴我們“用戶想要什麼”,而是幫助我們判斷:
一個功能對用戶滿意度的影響方式是什麼。(asq.org)
ASQ 對 Kano 模型的解釋中,也將其用於理解產品或服務功能完成程度與用戶滿意度之間的關係。
放到知識庫產品功能中:
具體而言,這些功能屬於什麼類型的屬性,就需要通過Kano的執行方式,從用戶的反饋中做出判斷,從而進一步得出功能的屬性特徵。
Kano 主要幫助我們回答:功能應該如何分層設計,幫助我們做出正確的判斷。
很多產品分析只做 Kano,容易出現一個問題:
用戶最興奮的功能,不一定是企業最應該優先投入的能力。
例如,一個很炫的“AI 自動生成問答助手”可能是魅力功能;
但如果底層知識解析和檢索質量不好,這個功能就只是“看起來智能”,但是給用戶的體驗不好,該功能就無法形成穩定競爭力,反而會影響用戶對產品的滿意度。
反過來,只做 DDD 的子域劃分也不夠。
因為你可能能判斷檢索能力很重要,但如果不瞭解用戶對不同檢索功能的感知差異,也無法判斷:
因此:
DDD 是業務價值視角,Kano 是用戶價值視角。
二者結合,就是用“業務價值 + 用戶價值”來決定功能設計和優先級。
RAG 的核心思想是:
在大模型生成答案之前,先從外部知識源中檢索相關信息,再基於這些信息生成回答。
它實際上是一條完整的處理鏈路:(插入圖示)
相應的每一個環節都會自然催生一類產品功能。
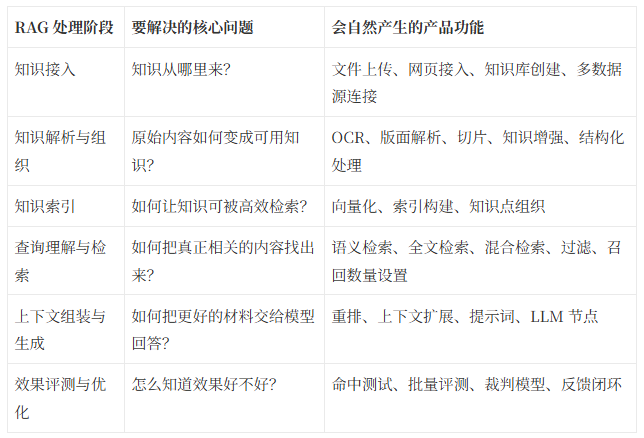
這張功能映射表中我們可以看出,其實RAG 產品功能不是菜單式堆疊,而是 RAG 處理鏈路在產品層面的逐步顯性化,是為了實現流程處理的完整性。
如果把 RAG 產品放入“面向非技術用戶的 AI 應用 / 工作流搭建平臺”中分析,我認為可以拆出以下能力域。
RAG流程中的環節:
知識接入 –> 文檔解析 –> 切片 –> 知識增強 –>索引準備
該流程對應的典型功能包括:
將這部分作為知識庫功能的核心,與其在RAG流程密切相關。如果前面的知識處理環節做不好,後面的檢索與生成都會被拖累。比如錯誤切片、解析不完整、知識組織混亂,會直接導致召回失敗或回答不準。
在 RAG 流程中的:
查詢理解 → 檢索召回 → 結果排序 → 上下文篩選
這個環節中解決的問題是,用戶提問後,能否又快有準的查找到相關內容。這個模塊內容映射到具體的產品中的功能是:
將這部分也作為核心域的原因,與RAG 架構本身的“增強”這概念相關,其本質就在檢索。如果找不準,即使大模型再強,最後也是基於錯誤上下文內容中生成答案,仍然解決不了大模型環節的問題。
在實際的產品中通常對應以下這些功能模塊:
在Agent智能體搭建的平臺中,可以說知識庫功能是將 RAG 能力包裝成可被業務使用的應用組件或工作流環節。其對應在Agent平臺中的典型功能是:
這裡有一個非常重要的區分:
例如:
這些能力非常重要,會影響用戶的使用體驗,但它們並不是 RAG 本體能力的來源。所以在本文中,它們就不作為重點展開。
本文選擇這兩個產品,是因為它們都不是“純技術型 RAG 引擎”,而是:面向不同技術水平用戶的 AI 應用 / 工作流搭建平臺。
百度千帆 AppBuilder 的知識庫能力直接面向 RAG 場景。其知識庫簡介中提到,知識庫是 RAG 的數據基礎,並提供知識增強、混合檢索、全文檢索、語義檢索與重排序等能力。
千帆更適合觀察:
國內大模型應用平臺如何把 RAG 做成較完整的知識庫工程化能力。
Lyzr AI 官方的 Classic Knowledge Base 文檔明確指出過,它可以創建 no-code RAG pipeline,用於從文件、URL、純文本等來源構建可搜索的文檔理解能力。
Lyzr 更適合我們去觀察:
海外 Agent 搭建平臺如何把 RAG 封裝成非技術用戶可配置、可測試、可連接 Agent 的知識庫能力。
因此,這兩個產品放在一起分析,並不是為了判斷誰更強,而是為了觀察:
同一條 RAG 流程,在不同 AI 應用 / Agent 搭建平臺中,被產品化成怎樣的知識庫功能。
在千帆的知識庫創建頁面中並不只是“上傳文檔”。
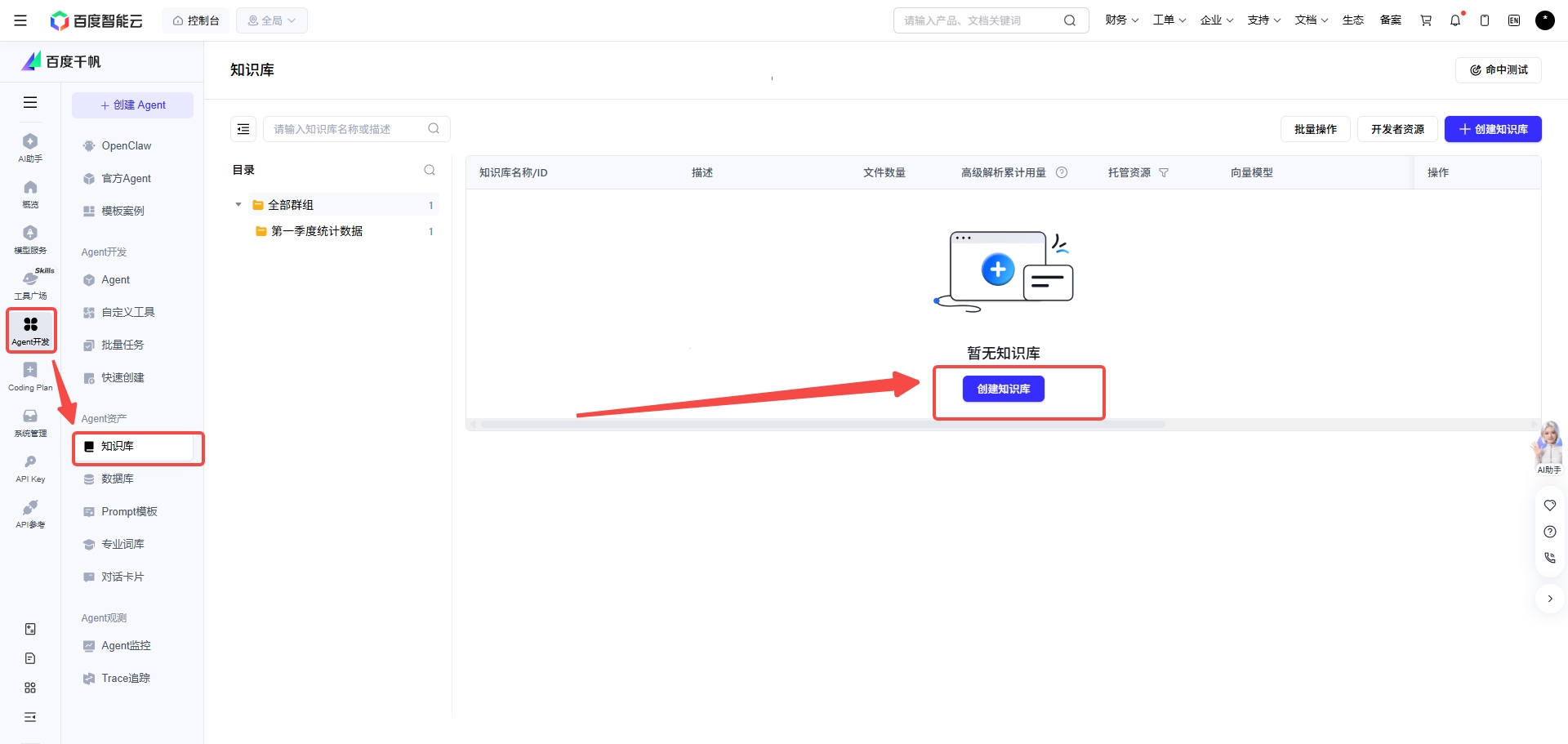
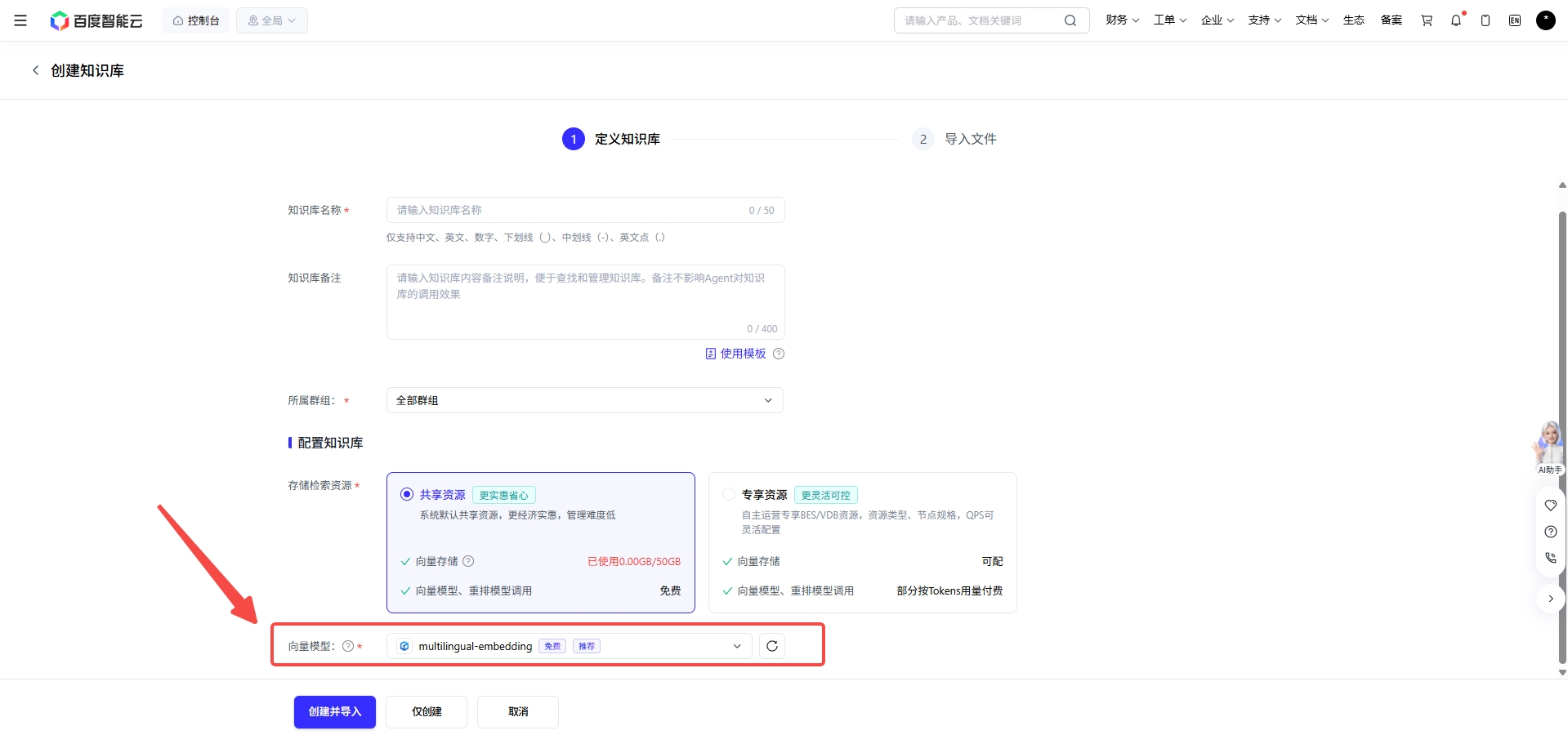
它會進一步提供(上圖中可以直觀的看到),其實千帆這個創建知識庫的功能表單中,字段的命名很講究,與RAG流程中的處理步驟和細節名稱是十分相關,甚至是相同的。以下我總結了其中的操作名稱,並且將其與RAG中的模塊進行映射對齊。
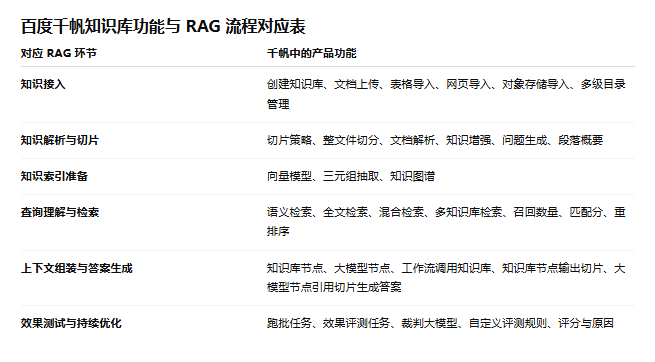
這些能力本質上都在回答同一個問題:
怎樣把一份原始資料,轉化成更容易被後續檢索命中的知識結構?
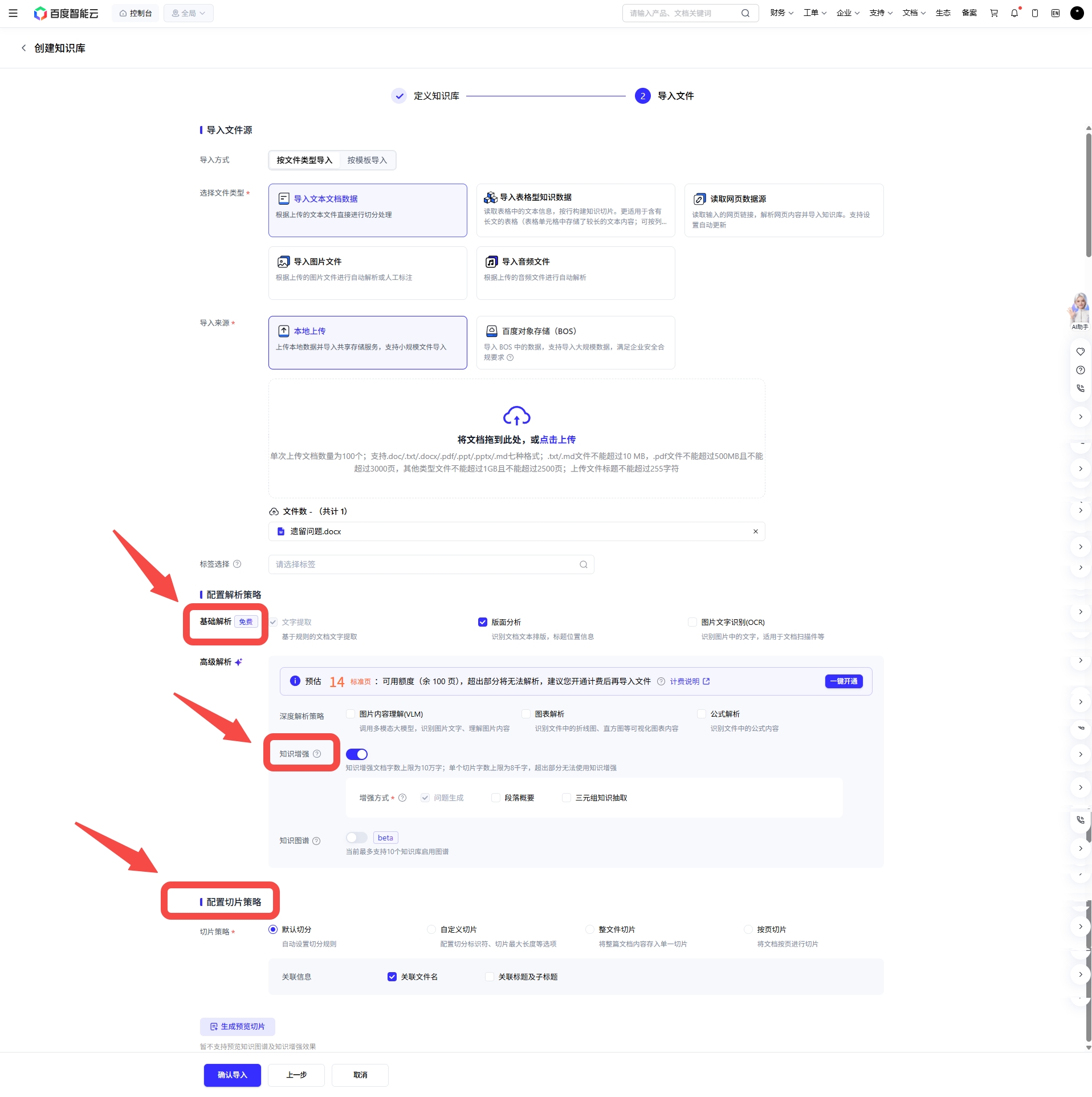
以及在上圖的千帆的“知識增強”按鈕開啟狀態下,可選擇知識增強的方式(可選增加切門片內容摘要和三元組知識抽取兩種知識增強方式),使用該輔助功能會調用大模型生成額外知識點,用於提升切片召回率。這說明它不是把知識庫當成靜態文件倉庫,而是在主動優化知識可召回性。
此外,千帆還在多模態 RAG 與圖譜增強 RAG 上做了產品化探索,分別對應圖文聯合檢索、多實體多關係知識組織等複雜場景,但本文中不對該內容展開說明,感興趣的話可以去千帆平臺上試試。
總體來說,百度千帆的知識庫能力更像是一套企業級 RAG 知識工程體系。它在知識接入、切片、知識增強、檢索策略、工作流調用和效果評測上都有較完整的產品化表達。
Lyzr AI 同樣支持知識庫,但產品策略不同。在Lyzr AI中 ,創建知識庫功能首先就分為了三種類別(知識庫、知識圖譜、語義數據模型)。其中針對於RAG流程的是知識庫搭建這個功能模塊,所以接下來我們聚焦於該功能路徑,探討其中功能與RAG的流程間的映射。
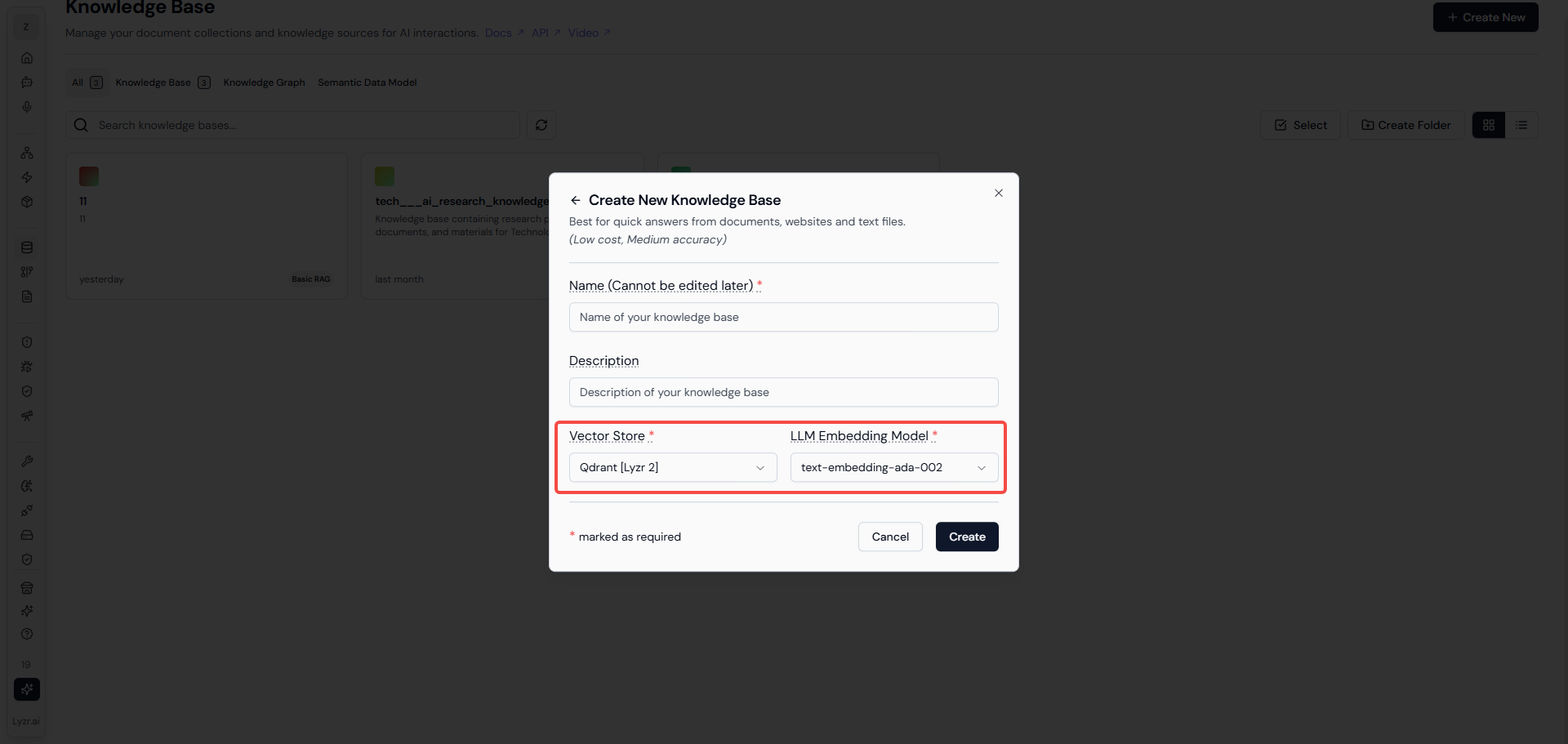
上圖是Lyzr AI 進行“知識庫”創建的頁面,向量化模型和向量庫是必填字段,進入下一頁後能夠自由選擇數據導入方式。與本文中闡述的RAG流程相關的是“導入文件”的方式。選擇 add file 選擇問文件即可(該平臺現在僅支持上傳PDF、DOCX、TXT文件),就會在頁面中左側列表中顯示所上傳的文件。
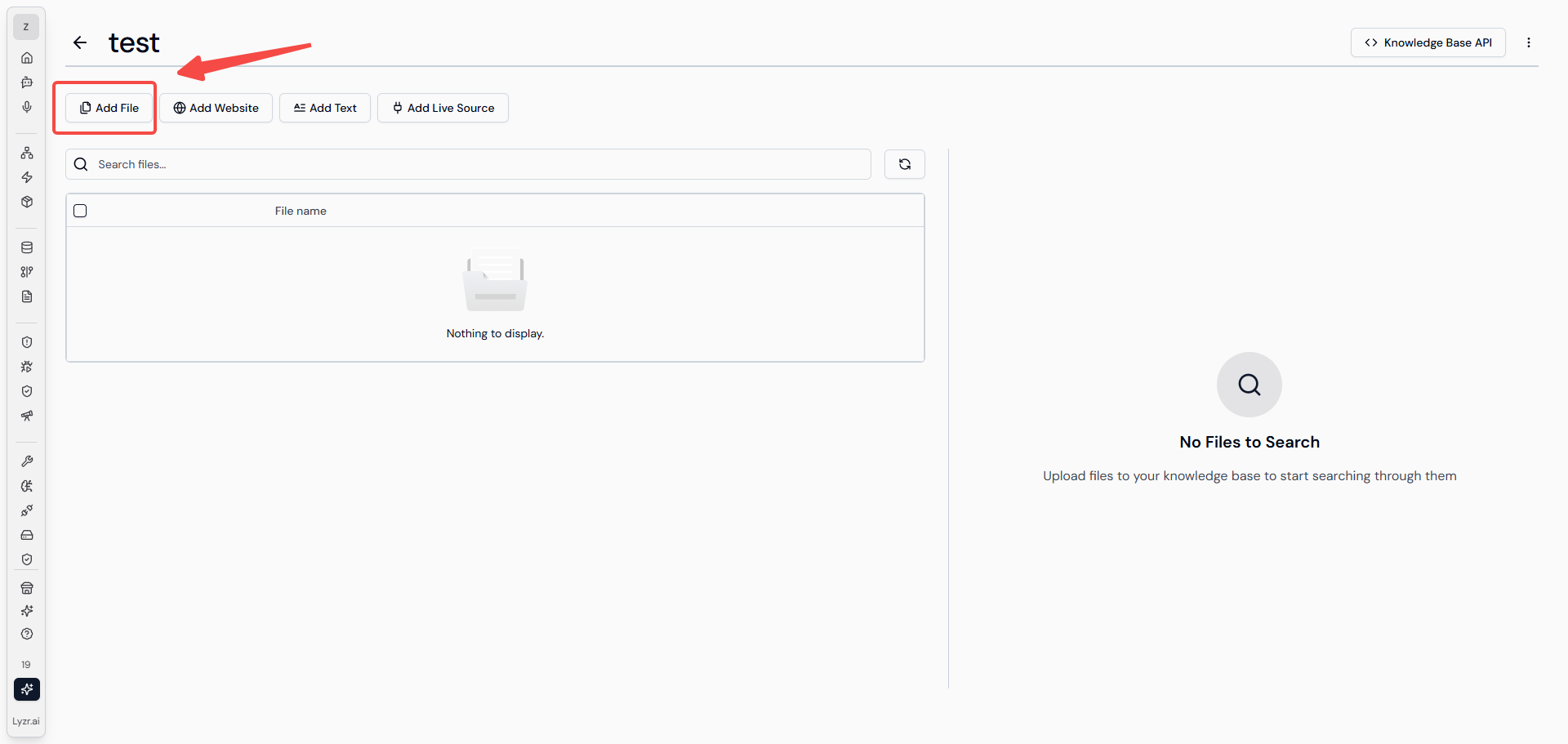
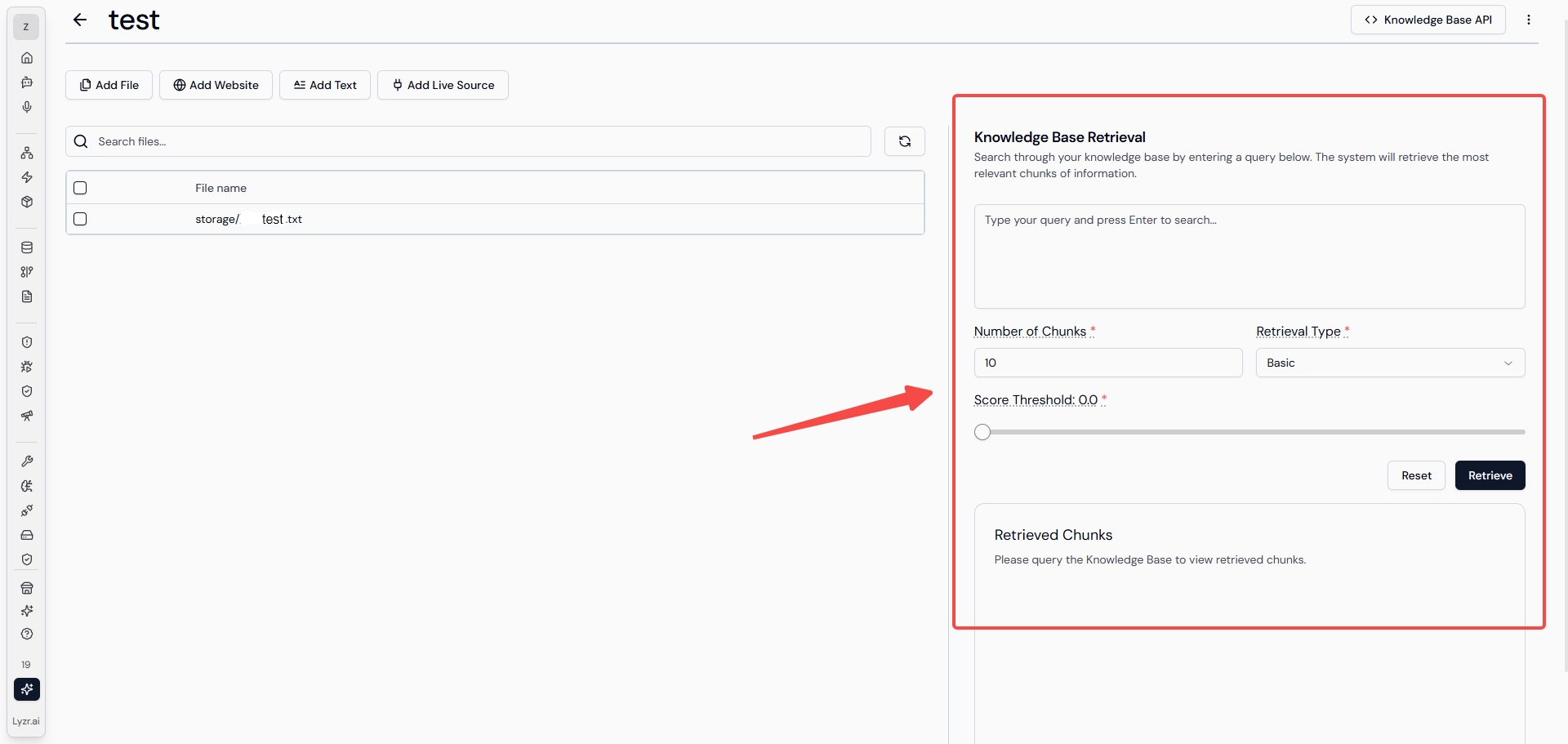
然後才會在界面中呈現出用戶可以進行設置的知識庫檢索選項(上圖紅框中的內容),Lyzr 在這部分的設計 ,個人認為優於百度千帆的設計,百度千帆中對於知識庫的分段配置、檢索方式、配置策略等等字段較為複雜,對於新手入門的用戶並不友好,而Lyzr AI 這種設計降低了非技術用戶的理解成本,只給用戶提供最必要的配置字段,既讓用戶有參與感也不會讓用戶感覺難操作。
用戶不一定需要先理解複雜的知識增強邏輯,只要知道:
我把組織資料放進 Knowledge Base,之後在 Workflow 裡接一個 Knowledge Base 節點,就能讓 Agent 基於這些資料回答。
Lyzr AI 的知識庫更像是面向 Agent 的 no-code RAG pipeline。它把知識接入、切片、向量索引、檢索策略、Prompt 組裝、引用輸出和模擬測試封裝到 Knowledge Base 與 Agent 的連接過程中,整體的知識庫配置會更加輕量化,更適合新人著手搭建。
在知識構建域:
千帆更強調知識工程化處理
Lyzr AI更強調知識庫使用門檻降低
兩者處理的仍然是同一個 RAG 問題:知識如何從原始材料變成可檢索資產。
這裡需要特別說明:
嚴格意義上的 Kano 分類,應通過用戶問卷調研得到。
下面這張表並不是正式調研結論,而是基於個人對於當前產品成熟度與功能普及程度,做出的產品分析式初判,僅供大家參考。
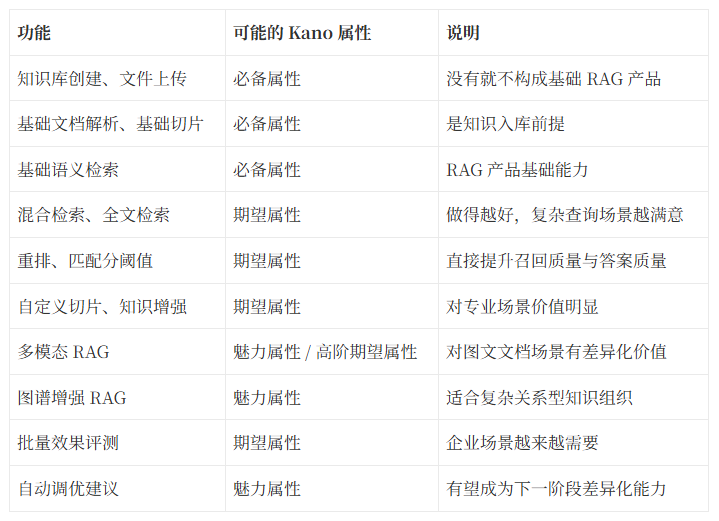
這張表的意義是:
不是所有功能都值得同等投入。而且我們仍然可能對這個kano的判斷結果有所懷疑,因此需要進一步確定對功能的屬性判斷結果是可信的。
下面我們將其和 DDD 子域劃分結合,就會得到更清晰的優先級判斷。
可以形成如下矩陣:
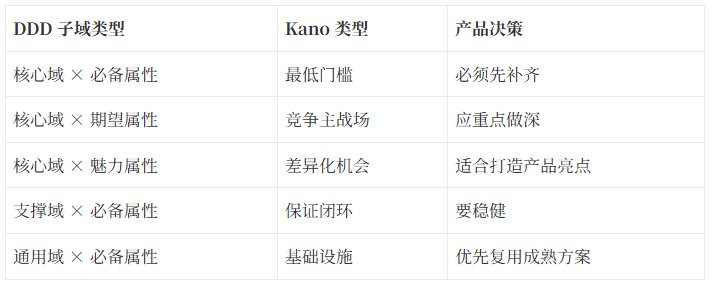
套到 RAG 產品裡,可以得到幾個很直接的判斷。
如果產品只做到“創建知識庫 + 上傳文件”,那隻能算門檻。
真正值得投入的是:
因為這些能力決定了後續檢索質量。
未來 RAG 產品的差異,絕不只是“有沒有知識庫”,而是:
這一點,千帆與 Lyzr AI 都已經通過不同方式體現出來。
當 RAG 從 Demo 走向正式業務,產品就必須回答:
所以,評測與優化不應長期被當作“後臺工具”,而應逐漸成為核心能力的一部分。千帆當前對效果評測任務的產品化,就是這一趨勢的體現。
這點非常重要。
很多產品一提“面向非技術用戶”,就想把所有複雜度都藏掉。
但 RAG 產品不能完全這樣做。
真正好的設計不是:什麼都不讓用戶知道。
而是:
把必須理解的關鍵流程顯性化,把不必要的底層複雜度收起來。
從這個角度看:
這兩種路線都有合理性,千帆的用戶群體更偏向於技術性人員,而Lyzr AI則對新手用戶更為友好。
本文試圖說明一件事:
RAG 產品中的功能,不是孤立的功能點,而是從一條知識處理流程中自然生成的產品模塊。
而 DDD 與 Kano 的結合,為我們提供了一個更完整的產品分析方法:
如果後續要設計一款面向非技術用戶的 RAG 產品,先問:
DDD的領域劃分,幫助更快速敲定產品的核心域業務。
這說明這些能力很可能是當前賽道的 核心競爭區。
所以說RAG 產品中的功能,其實並不是產品人員憑空想出來的,而是正是因為他們懂得RAG的數據處理邏輯、明白其價值所在,並圍繞 RAG 處理流程逐步產品化的結果。
本文由 @:) 原創發佈於人人都是產品經理。未經作者許可,禁止轉載
題圖來自Unsplash,基於CC0協議
該文觀點僅代表作者本人,人人都是產品經理平臺僅提供信息存儲空間服務
此內容由慣性聚合(RSS閱讀器)自動聚合整理,僅供閱讀參考。 原文來自 — 版權歸原作者所有。