模型版本更新比產品迭代還快,但大多數對選型的討論仍停留在「誰的分數高」。
跑分高不等於用起來好,用起來好不等於能落地——這三件事,分別對應三套完全不同的評估邏輯:基準測試(Benchmark)看能力邊界,競技場(Arena)看用戶真實偏好,開放路由(OpenRouter)看生產環境裡的實際使用情況。
本文不推薦具體模型,只做一件事:把這三個資訊源拆清楚,說明它們各自在回答什麼問題、有什麼盲區,以及怎麼組合使用才不容易踩坑。

大模型慢慢變成了產品裡的標配,但「選哪個模型」這件事,老實說一直沒有特別清晰明確的方法。不是模型太少了,而是評估資訊太分散。有人拿基準測試(benchmark)說話,有人靠競技場(Arena)排名,還有人看誰的呼叫量高——每一種說法都有道理,但放在一起又互相衝突。
問題不在於資訊不夠多,而在於這三類資訊根本不是在回答同一個問題。搞清楚它們各自在說什麼,才能知道什麼時候該看哪個。
基準測試(Benchmark) 是最傳統的一類模型評估方式,核心是透過標準化測試集來衡量模型在特定任務上的能力,例如數學推理、知識問答、程式碼生成等。從產品視角看,它回答的是一個基礎問題:模型是否具備完成某類任務的能力上限。
這類方法的優勢在於結構清晰、結果可量化,並且便於橫向對比不同模型版本。例如同一任務下,模型A與模型B在準確率上的差異,可以較直觀地反映能力差距。

但它的問題也同樣明顯:首先是「考試化偏差」。Benchmark 本質上是固定題庫,而大模型訓練數據的覆蓋範圍極廣,很難排除數據污染的可能性。模型在某些 benchmark 上表現優異,並不必然意味著它具備真實泛化能力。
其次是與真實任務的脫節。產品中的任務往往是開放式的、多輪的、包含上下文和工具調用的,而 benchmark 更接近「單點答題」,很難反映複雜系統能力。
因此,從產品決策角度,Benchmark 更適合作為「能力上限參考」,而不是選型依據。
第二類信息來源是以 Arena AI 平台為代表的人類偏好評估體系。這類方法的核心機制是盲測:用戶在不知道模型來源的情況下,對不同模型輸出進行比較,並基於主觀體驗投票。
與 benchmark 不同,這一類評估更接近真實使用體驗,因此它在產品選型中具有獨特價值。從結構上看,這類評估已經不再局限於「聊天能力」,而是拆分為多個任務維度,包括:
這意味著它本質上是在評估一個更複雜的問題:模型在不同任務類型下的主觀表現品質。

它的優勢在於:首先,它反映的是人類真實偏好,而不是抽象指標。這使得它在「寫作品質」「表達自然度」「指令遵循程度」等方面具有較強參考意義。其次,盲測機制在一定程度上減少了品牌偏見,使不同模型可以在相對公平的條件下比較。
它的局限同樣明顯:一方面,評估任務本身分布並不等同於真實生產環境。複雜的企業級任務,例如長鏈路 agent 執行、多輪工具調用穩定性、或高約束 RAG 系統,在這類評測中往往覆蓋不足。另一方面,評審機制本質上仍然是主觀的,容易受到回答長度、表達風格等因素影響,而這些因素並不一定等價於真實任務品質。
因此,Arena 更適合用來判斷「使用者體驗層面的表現」,而不是系統能力結論。
第三類資訊來源是基於 API 呼叫與真實應用行為的數據統計,例如 OpenRouter 所展示的模型使用情況、呼叫量、延遲表現以及工具呼叫能力等。
與前兩者不同,這一類數據更接近生產環境本身,它關注的不再是「模型理論能力」或「使用者主觀偏好」,而是一個更現實的問題:模型在真實產品中是否被採用,以及使用成本與穩定性如何。
常見指標包括:
從產品角度看,這類數據的價值在於它提供了「真實選擇結果」。用戶和開發者在實際業務中如何使用模型,往往比評測分數更能反映綜合權衡。
但它也存在明顯限制。首先是「分發偏差」。某些模型使用量高,並不一定意味著能力最強,而可能是因為價格更低、接入更容易,或被設為默認選項。其次是「生態影響」。模型在平台中的可見度、推廣策略、以及集成成本,都會影響使用量數據,使其不完全等價於能力排名。
因此,生產數據更適合用來判斷模型的「工程落地能力」,而不是純技術能力排序。
如果從產品決策的角度來看,這三類資訊其實對應的是三個不同層面的問題:
它們之間並不是替代關係,而是互補關係。單獨依賴任何一種資訊,都容易在選型中產生偏差:只看基準測試容易高估實驗室能力,只看體驗評估容易忽略工程約束,只看生產數據又可能被生態分發和價格策略影響。
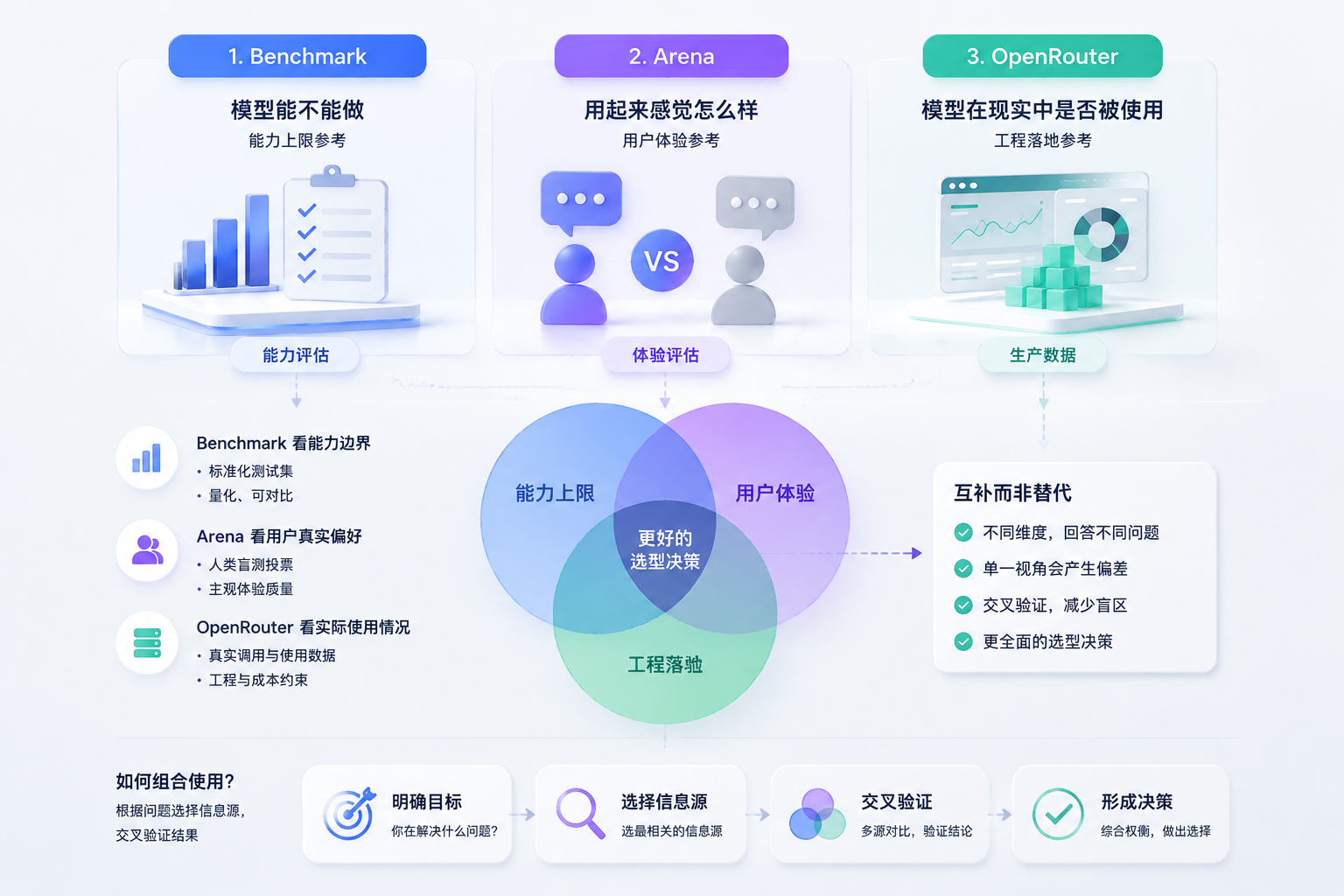
更關鍵的一點是,這三類資訊並不是必須同時使用的,而是可以根據具體的調研目標進行選擇。不同階段、不同問題,應該選用不同的資訊來源來支撐判斷。例如,當你關注的是「模型是否具備某種能力邊界」時,benchmark 是更直接的參考;當你評估的是「用戶實際體驗是否更好」時,Arena AI 類評測更有意義;而當你在做「是否可以在生產環境落地以及成本是否可控」的決策時,生產數據與工程指標會更接近真實約束。
換句話說,這三類資訊更像是三種不同的觀察工具,而不是必須同時開啟的儀表板。在實際工作中,關鍵不在於「收集更多資訊」,而在於「選擇正確的資訊來源來回答當前的問題」。
在具體的產品決策過程中,更合理的方式是:根據問題類型選擇資訊源,再在多個資訊源之間交叉驗證結果,而不是用單一指標去解釋所有問題。
大模型選型從來都不是一道有標準答案的題目。
基準測試會被刷,Arena會受風格偏好影響,生產數據會被價格和生態扭曲。每一種資訊來源都有盲區,這不是缺陷,而是現實。
真正的問題從來不是「哪個模型最好」,而是「對我的業務來說,什麼是好」。
這三類資訊源的價值,不在於給你一個答案,而在於幫你把模糊的直覺,變成可以被拆解、被驗證、被質疑的判斷。
能力上限、用戶體驗、工程落地——把這三件事搞清楚,選型就不再是拍腦袋,而是一個可以被推導的過程。
本文由 @WB 原創發佈於人人都是產品經理。未經作者許可,禁止轉載
題圖來自作者提供
此內容由慣性聚合(RSS閱讀器)自動聚合整理,僅供閱讀參考。 原文來自 — 版權歸原作者所有。