裸差、A/B測試盲區、因果推斷方法——產品復盤中的三大陷阱與破解之道。本文將深入剖析為何簡單的數據對比會誤導決策,揭示A/B測試在網絡效應場景下的局限性,並手把手教你用傾向評分匹配(PSM)與雙重差分(DiD)方法在歷史數據中還原真相。當AI讓數據分析門檻降低時,這些底層思維框架比算法更重要。

在做產品復盤時,你一定這麼幹過:一個功能上線兩週,留存漲了三個百分點。你把這三個點寫進PPT,標題是《XX功能成效復盤》。
沒人會質疑這個數字,它真實存在。
但它衡量的是:效果 = 上線後 − 上線前。這個減法背後藏著一個幾乎沒人挑明的假設,這兩週裡,世界上唯一變了的,只有你的功能。
大盤沒動,沒有大促,沒有新一輪投放,進來的用戶和上個月還是同一批人。
上述任何一條不成立,那三個百分點裡就混進了本不屬於你的功勞。
這個沒扣掉任何外部變化的差值,本文稱之為裸差。
復盤裡最貴的錯誤,就是把裸差當作效果。
接下來,我想講清楚三件事:裸差為什麼騙人,A/B測試為什麼也不總能救你,以及當你只有歷史數據時,怎麼用因果推斷逼近真相,同時避免被一個看起來很科學的結論誤導。
先把公式拆開看。
效果 = 上線後 − 上線前。
它成立的前提是:這段時間內唯一的變量就是你的功能。可現實中的產品環境,從來不是一間真空實驗室,而是一條同時被幾十隻手推動的河。
留存上漲的那兩週,也許恰好是行業旺季。也許市場部剛啟動了一輪投放,進來一批天然更精準的用戶。也許上個版本修復了一個嚴重崩潰,整體用戶體驗本就抬了一截。也許什麼都沒發生,只是上上週的數字偶然偏低,這週回到了正常水位。
這些變化都與你的功能無關,但它們全都湧入了「上線後」那個數字。
裸差的危險,不在於減法算錯了,減法本身沒錯。危險在於,它把一段時間內所有正面變化,都默記在了你這個功能頭上。大盤、季節、投放、用戶畫像漂移,這些本該被剔除的因素,全被打包成了功能的成績單。
這就是偽因果。兩件事先後發生,看起來像前者導致了後者,可「先後」從來不等於「因果」。
公雞打鳴在日出之前,但沒人說是公雞叫醒了太陽。可一旦換成產品指標,這個錯誤就變得無比隱蔽,因為數字是真的,圖表是漲的,故事是順的。
一個真實、能寫進PPT、卻完全站不住腳的結論,比一個明顯的錯誤危險得多。
所以復盤的第一步,不是急著算「漲了多少」,而是先問:這段時間裡,除了我的功能,還有什麼是動的?
問出這個問題,你才算從裸差裡走出來了一步。
裸差只是偽因果最粗糙的一種,它錯在時間維度:把上線前後的差,當成功能的差。下面這類更隱蔽,錯在人群維度,相關性本身就長著一張因果的臉。
這裡有三種最常見的偽裝,每一種都能讓一份看似嚴謹的復盤,得出恰恰相反的結論。
指有第三個因素,同時影響著你所關注的兩端。
一個經典例子:你上線了一個新功能,發現用過它的用戶,留存明顯高於沒用過的。結論呼之欲出:功能提升了留存。
但先停一下。誰會主動去用新功能?大概率是那些本來就高頻、本來就活躍、本來就離不開你產品的人。高活躍用戶天生留存就高,跟這個功能沒關係。「活躍度」才是躲在背後的第三隻手,它同時推高了「使用新功能的概率」和「留存」。
你看到的不是功能在起作用,而是高活躍用戶的自我篩選。功能只是搭了個順風車。
它更反直覺:分組看和合併看,結論可以完全相反。
設想一次改版,你想評估它對轉化率的影響。合併所有用戶看,新版轉化率更低,於是你判定改版失敗。
可一旦把用戶拆成新客和老客分別看,新版在新客中轉化更高,在老客中也更高。兩個分組都贏了,合在一起卻輸了。
為什麼?因為新版上線後,用戶結構變了:這批用戶裡新客比例大幅上升,而新客的轉化天然低於老客。是用戶畫像構成的變化拉低了整體數字,而非改版本身變差了。
辛普森悖論的殺傷力在於,合併與分組這兩個口徑,單獨看都「沒錯」,但指向截然相反的行動。你是該回滾還是該加碼,取決於你有沒有把人羣拆開來看。
指的是你手上的樣本,已經經過了某種篩選。
我們就栽過一次。做一個新功能時,用戶天天在羣裏罵「太難用了」,我們當真了,連夜加班改互動。上線後日活跌了20%。復盤才發現:在羣裏罵的人只佔1%,剩下99%的沉默用戶,早就用熟了舊版的路徑,新版反而讓他們集體懵了。我們聽見的是最吵的那1%,照着他們改,結果把沉默的99%推走了。
這就是倖存者偏差最常見的形態:會發聲的樣本,從來不等於全部樣本。反過來也一樣,好評同樣會騙你。你翻遍評論區、問卷、客服記錄,發現對新版的評價整體偏正面,於是鬆了口氣。可那些用了一次就卸載、默默流失的用戶,已經不會再給你任何反饋了。留下來說話的,本就是相對認可你的那批人。
倖存者偏差不會篡改你看到的數據,它只是悄悄拿走了一部分本應出現的數據。不管拿走的是沉默的不滿,還是沉默的流失,你以為自己在看全貌,其實只看到了發聲者的面孔。
這三種誤判有一個共同點:數據都是真的,邏輯鏈條看起來也通,但結論是反的。它們之所以危險,恰恰是因為它們足夠真實、足夠順滑、足夠說服一屋子人。
說到這裡,懂行的人會講:這些問題,A/B測試不就解決了麼。
很大程度上,對。
A/B測試的厲害之處,在於它用隨機分組,把上述混淆變數、畫像差異、自我篩選,一次性、平均地分配到實驗組和對照組兩邊。
兩組用戶除了「是否用到新功能」這一個差別,其餘在統計上基本一致。這時兩組的指標差,才乾淨地等於功能的效果。隨機化,是迄今為止人類對付偽因果最強的手段。
但A/B有一個前提,平時藏得很深,叫SUTVA——穩定單元處理值假設(SUTVA)。
翻譯成人話,核心只有一句:每個用戶受到的影響,只取決於他自己被分到哪一組,跟別人被分到哪一組無關。實驗組與對照組之間,必須彼此獨立,互不干擾。
大多數時候這個假設成立。我看不看到一個新的按鈕顏色,不影響你看不看到。
可一旦你的產品涉及網路效應、雙邊市場或社交傳播,這個假設就會被悄悄打破。
打車App是最清晰的例子。
你給實驗組的乘客上線了一個新的派單策略,讓他們更容易叫到車。聽起來是個標準A/B。但乘客和司機共享的是同一個運力池。實驗組乘客多搶走了幾輛車,對照組乘客能叫到的車就變少了。你的實驗非但沒讓兩組獨立,反而讓實驗組直接踩著對照組得分。這時你測出的差值是被放大的、虛高的,因為對照組的體驗是被你的實驗親手拉低的。
在IM產品裡更隱蔽。
你給實驗組上線了一個新的互動玩法,實驗組用戶興高采烈,跑去跟好友互動。而那些好友,有一半在對照組裡。對照組明明沒拿到新功能,卻因為收到實驗組發來的訊息,活躍度也跟著漲了。兩組的差值被抹平,你的功能看起來「沒效果」,但它的效果其實透過社交關係泄漏到了對照組。
網路效應、雙邊市場、社交傳播。這三個詞只要出現在你的產品裡,A/B的獨立性前提就值得你停下來仔細檢查。SUTVA一旦被打破,隨機化這把好刀,也會切出一個錯誤的數字。
A/B不是萬能的。它是一把好刀,但有自己的鋒利不到的地方。
A/B還有一個更樸素的局限:它要求你提前設計。
你必須在功能上線之前,就劃分好實驗組和對照組,定好指標,留好放量節奏。
可現實中有太多場景沒有這個「提前量」:功能已經全量上線,你沒留對照組;這是一次公司級的大改版,無法只給一半人;或者你要復盤的是三個月前的某個決定,當時壓根沒人想到要做實驗。
這時候你手裡只剩一樣東西:歷史數據。
A/B適合提前設計實驗,驗證未來。因果推斷,適合利用已發生的歷史數據,做事後歸因。前者管「接下來該不該做」,後者管「上次那件事到底有沒有用」。兩者填補的是不同的盲區。
事後歸因中,有兩個最常用、也最值得先掌握的方法。
它的思路極其樸素:既然沒法隨機分組,那我就在歷史數據裡,人工找出條件盡量相似的兩組人。
用了新功能的用戶中,挑一個活躍度中等、註冊三個月、城市在二線的。
我就到沒用過新功能的用戶裡,去找一個活躍度、註冊時長、城市都盡量一致的人,把他們配成一對。一對一對地配下去,配出兩組在各項特徵上高度接近的人群。兩組的唯一系統性差別,回到只剩「用沒用新功能」。這時再比留存,就接近於在比「同一類人,用與不用的差」。
傾向得分匹配(PSM)是在歷史數據裡,盡力把A/B的隨機分組「補」出來。它應對的,正是第二節提到的混淆變數。
但PSM有個命門:它只能匹配你**觀測得到**的變量。活躍度、註冊時長、城市,這些表裡有的,它能配平;可那些沒進表的暗變量,比如用戶的真實意圖、被競品影響的程度,它一個都夠不著。兩個各項特徵都配成一對,卻可能在某個你沒記錄的維度上天差地別。PSM補的是你看得見的那部分偏差;看不見的那部分,它無能為力。
它要解決的是裸差中最核心的問題:怎麼把大盤趨勢扣掉。
DiD的做法是找一個對照組,一群沒受到你這次改動影響、但跟你的目標用戶走在同一條大盤趨勢上的人。然後做兩次相減。第一次,算你的目標用戶上線前後的變化。第二次,算對照組在同一段時間裡的變化。最後,用前者減去後者。
對照組那段變化,代表的是「就算什麼都不做,大盤自己也會走出來的趨勢」。用它去扣除,剩下的才是真正歸因於你這次改動的淨效果。裸差只做了第一次相減,雙重差分(DiD)多減了一次,把混在裡面的大盤趨勢剔除掉了。
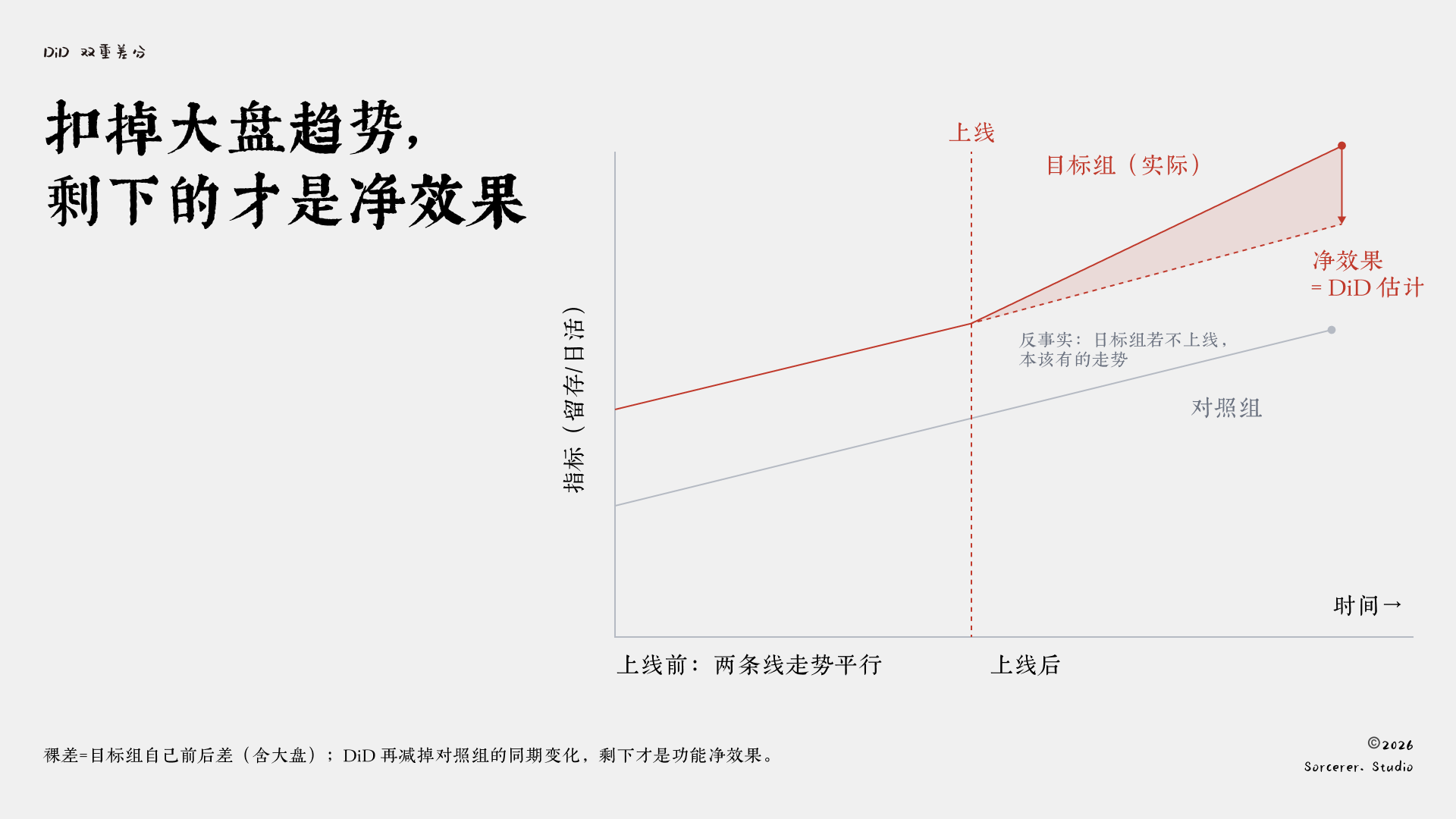
上線後目標組的真實走勢,減去它「沒上線本該走的」那條反事實虛線(即沿對照組趨勢平移),中間那道缺口才是淨效果。裸差錯把整段抬升都算成功勞的功勞。
但雙重差分(DiD)有一個關鍵前提,平時最容易被默認成立,叫平行趨勢。
它要求:在你上線之前,目標組和對照組的指標趨勢必須是平行的——兩條線可以高低不同,但走勢得一致。只有這樣,你才能假設「要是沒上線,它倆之後也會繼續平行」,從而用對照組去代表目標組本該有的走勢。
這個前提不能拍腦袋默認。你必須把上線前足夠長一段時間的兩條曲線拉出來,親眼確認它們確實平行。如果上線前兩條線就在收斂或發散,那DiD的整個地基就是歪的,算出來的淨效果照樣是假的。
你可能會說:現實裡兩條線幾乎不可能完美平行,那DiD是不是基本沒用?不是。
平行趨勢不是一個「是或否」的開關,而是一個程度問題。上線前貼得越緊、越長一段時間同向,結論就越可信;偏離越明顯,你就越該給淨效果打個折,標上「僅供參考」。
它給你的本就不是真值,只是一個比裸差靠譜得多的估計。把「無法做到完美」直接當成「乾脆不做」,是另一種偷懶。
PSM補的是「人群不可比」,DiD補的是「大盤沒扣掉」。
兩者還有一層高下:PSM只能控住你觀測到的變數,DiD靠「相減」這個動作,連那些你沒觀測到、卻不隨時間變的差異,也一併扣掉了。這也是後面那條決策鏈裡,DiD排在PSM前面的原因。它們都不如A/B乾淨,但當你只剩歷史數據時,它們是你離真相最近的兩條路。
看到這裡,有人會想:這些方法聽著就麻煩,PSM、DiD、平行趨勢檢驗,還不如把數據丟給AI,讓它幫我跑。
AI確實能跑。今天你把一張表丟給它,它能幫你做匹配、算雙重差分、畫出趨勢圖、給出一個帶信賴區間的精美結論。建模的門檻,確實被實實在在地拉低了。
問題是,AI能替你跑模型,但它替不了你做判斷。
它判斷不了,你這張表裡哪些變量是混淆變量。
混淆變數是業務概念,不是數據特徵。你得知道「高活躍的人本來就愛用新功能」,才會想到把活躍度放進匹配;AI看到的只是一列數字,它不知道這列數字在你的業務語境裡意味著什麼。
哪些假設其實站不住。
平行趨勢成不成立,SUTVA破沒破,這些要靠你對產品的理解去質疑。AI預設你給的前提都對,它只負責在你的前提上往下算。
它更判斷不了,那些根本沒進入數據的業務暗變量。
那次留存上漲,也許是因為同期一個競品出了大故障,用戶回流到了你這兒。這件事不在任何一張表裡,AI永遠不會知道,但它恰恰是真正的原因。
於是AI時代最危險的復盤,不是拍腦袋。拍腦袋至少所有人都知道那是拍腦袋,會本能地存一份懷疑。
最危險的,是用一組錯誤的假設,跑出了一個看起來無比科學的結論。它有模型,有p值,有置信區間,有一張嚴謹的圖表。它把「我猜的」包裝成了「數據證明的」。
一屋子人看著那張圖點頭,沒有人再去問那個最該問的問題:這些假設,到底成不成立?
工具越強,那個被跳過的判斷,代價就越大。
AI沒有降低做因果歸因的難度,它只是把難的部分從「算」挪到了「想」。而「想」這部分,至今沒有任何工具能替你完成。
講完這些方法,最後我想把它壓成一條可以隨身帶走的原則。
回頭看這一路:裸差不可信,是因為變數太多。
三類誤判會騙人,是因為有看不見的變數在攪局。A/B之所以強,是因為它用隨機化,把變數這件事一次性摁住了。PSM和DiD之所以要費那麼大的力氣,是因為它們在歷史數據裡,亡羊補牢地去控制那些當初沒能控住的變數。
所有方法都在幹同一件事:讓變化的東西盡可能少。
少變一點,優先於多算一點。
我們做歸因時的本能,是想算得更複雜、更全面、更高級,上更花俏的模型。
但歸因可信度的真正來源,從來不是演算法多精巧,而是除了你關心的那個變數,別的東西變得有多少。能在源頭上少變一個變數,勝過事後用十個模型去補救。
把這條原則展開,就是一條清晰的決策鏈:
第一步,能做隨機A/B,就做A/B。這是控制變數最乾淨的方式,沒有之一。只要場景允許、傷害可控、又不存在SUTVA那種相互干擾,優先使用隨機化把變數掐死在源頭。
第二步,A/B做不了,但你有一個乾淨的對照組,就用DiD。全量上線了、改版沒法切一半、要覆盤的是過去的事,這些時候,找一個走在同一條大盤趨勢上的對照組,用雙重差分把趨勢扣掉。前提是先確認平行趨勢,別預設。
第三步,連乾淨的對照組都沒有,只能在歷史數據中匹配,就考慮PSM。人工配出條件盡量相似的兩組人,逼近「同一種人用與不用」的對比。它最不穩,但有時是你唯一的路。
第四步,如果連匹配的假設都站不住,就承認這次無法歸因。
最後這一步最難,也最值錢。承認「我無法判斷這個功能到底有沒有用」,遠比硬編一個三個百分點的成績單要誠實,也要安全。
一個誠實的「不知道」,不會把你引向錯誤的下一步決策;一個偽造的「有效」,會。
有人會立刻反駁:老闆就是要一個數,我說「無法歸因」,挨罵的是我。
這話沒錯。但「無法歸因」不等於「兩手一攤」,你可以給一個帶條件的答案:在平行趨勢大致成立的前提下,淨效果大概落在某個區間;這幾個假設一旦鬆動,結論就不作數。
把假設和不確定性一起交出去,比單遞一個乾淨卻虛假的數字,既更誠實,也更經得起追問。真正會讓你挨罵的,是那個你拍著胸脯保證、半年後被證偽的「3個點」。
產品復盤的目的,從來不是給一個功能頒獎,而是為下一個決定找準方向。而找準方向的前提,是你算的那個效果,得是真的。
下次再寫復盤PPT,落筆那個「效果」數字之前,先問自己一句:這段時間裡,除了我的功能,還有什麼也變了?
把這個問題追問到底,就已經躲開了產品復盤裡最貴的那個錯覺。
本文由 @巫師 Sorcerer 原創發佈於人人都是產品經理。未經作者許可,禁止轉載
題圖來自 Unsplash,基於 CC0 協議
此內容由慣性聚合(RSS閱讀器)自動聚合整理,僅供閱讀參考。 原文來自 — 版權歸原作者所有。