1. 什么是 RDMA
RDMA(Remote Direct Memory Access,远程直接内存访问)是一种为了解决网络传输中服务器端数据处理延迟而产生的技术。
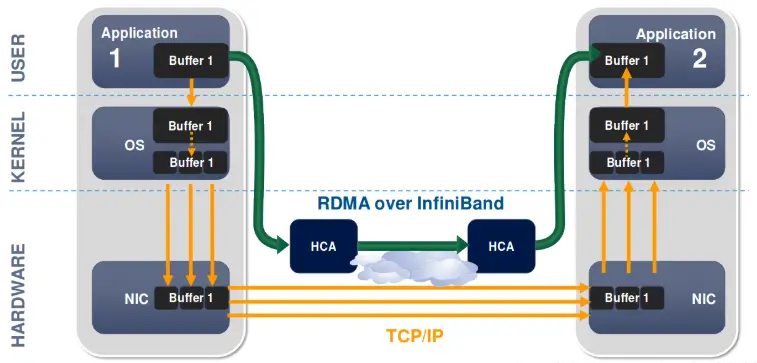
TCP/IP 传输时,数据经过网络堆栈,再经过网卡发送,接收端接收后,按照序列号组装数据。
DMA 传输时,可以直接在设备和内存之间传输数据,不需要经过网络堆栈。
RDMA 传输时,可以实现跨节点的 DMA 数据传输。
三者之间的对比如下:
| 特性 | TCP | DMA | RDMA |
|---|---|---|---|
| CPU 占用 | 较高(通常 10-40% 以上) | 较低(<10%,依赖于实现) | 极低(通常在 1% 以下) |
| 延迟 | 10-100 微秒 | 数微秒(内存传输) | 亚微秒到单微秒级 |
| 带宽效率 | 1-10 Gbps(视网络条件而定) | 最高可达 100 Gbps(与总线速率相关) | 100-400 Gbps(依赖于 RDMA 网卡型号,如 RoCE、InfiniBand) |
| 适用场景 | 通用网络传输 | 本地内存或设备间数据传输 | 高性能网络传输 |
| 硬件要求 | 无 | 需要 DMA 控制器 | 需要 RDMA 网卡(如 InfiniBand 或 RoCE) |
2. RDMA 通信过程
RDMA 使用队列的机制进行数据通信,其基本通信单位是 QP(Queue Pairs,队列对)。一个 QP 由一个 SQ(Send Queue,发送队列)和一个 RQ(Receive Queue,接收队列)构成。
大致的通信过程如下
- HOST 提交工作请求 WR(Work Request,工作请求),将 WR 放到工作队列 WQ(Work Queue,工作队列)
- RDMA 硬件消费 WQE 中的 WR,进行数据传输
- RDMA 硬件消费完成后,产生 CQE(Completion Queue Entry,完成队列条目),将 CQE 放入 CQ (Completion Queue,完成队列)队列中,等待 HOST 消费
- HOST 从 CQ 中消费 WC (Work Completion,工作完成)
3. RDMA 技术实现
3.1 InfiniBand
由 InfiniBand Trade Association(IBTA)在 1999 年提出,旨在为高性能计算(HPC)和大规模数据中心提供高带宽、低延迟的连接,主要由英特尔、NVIDIA、Mellanox(现为英伟达子公司)、IBM 等推动,广泛应用于超级计算机和企业级存储解决方案。
InfiniBand 已成为数据中心和 HPC 的标准之一,支持多种协议(如 RDMA 和 NVMe over Fabrics),并逐渐向 AI 和机器学习领域扩展。
InfiniBand 具有高带宽(可达 400Gbps)、低延迟(微秒级)、支持大规模扩展、具备先进的流量管理和质量服务(QoS)特性。
3.2. iWARP
由 IETF 的 RDMA Working Group 在 2000 年提出,旨在通过现有的 TCP/IP 网络实现 RDMA,主要由英特尔、Cisco、Broadcom 等公司推动,尤其在云计算和虚拟化环境中应用广泛。
iWARP 在企业网络中得到一定应用,尤其是在传统以太网架构下的 RDMA 需求,逐渐被市场认可,但竞争力相对较弱。
iWARP 兼容性强(可在现有以太网基础设施上运行)、支持 TCP/IP 协议,降低了 RDMA 的部署门槛,适用于中小型数据中心。
3.3. RoCE (RDMA over Converged Ethernet)
由 IBM 和其他公司在 2008 年提出,旨在将 RDMA 整合到以太网环境中,通过 DCB 技术实现高效的数据传输,主要由 Mellanox(现为英伟达)、Cisco、Intel 等公司推动,逐渐在数据中心和云计算环境中普及。
RoCE 有两个版本 RoCE v1 协议是一个以太网链路层协议,RoCEv2 协议构筑于 UDP/IPv4 或 UDP/IPv6 协议之上,能组建更大的网络。
相较于 InfiniBand,RoCE 的优势在于可以在现有以太网基础设施上运行,能够降低部分的硬件成本,但也很难达到 InfiniBand 成本的 50% 一下。
4. Ascend 下的 RDMA
Atlas 800 的 RDMA 依赖于 RoCE 网卡,如下图:
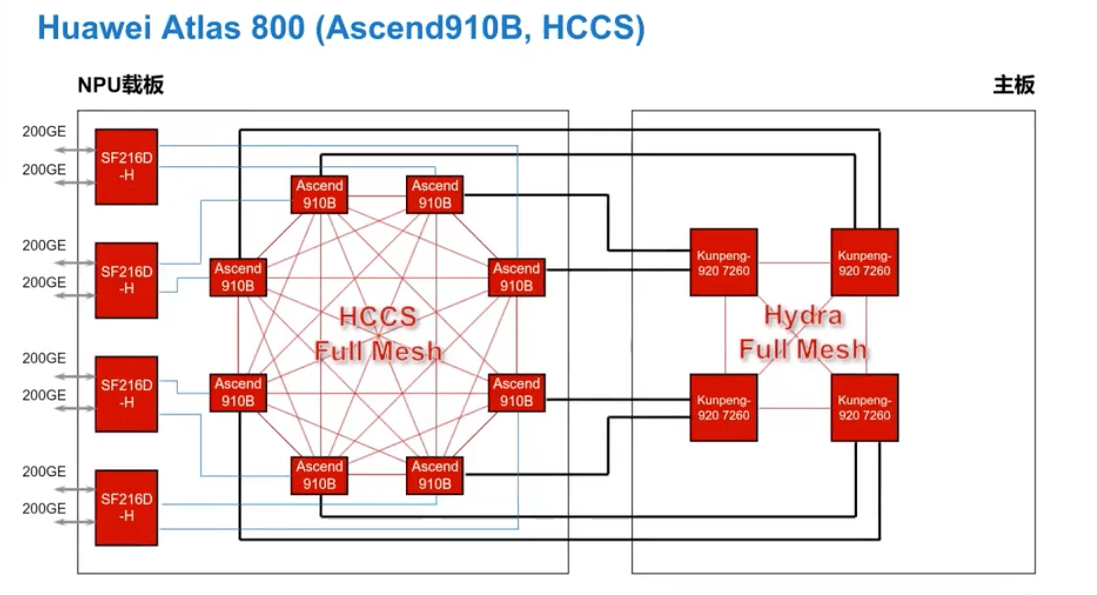
一个 Board 上四个 SF216D-H 网卡,每个 SF216D-H 有两个 200GE 网卡。每个网卡连接一张 NPU 卡,用于组网。
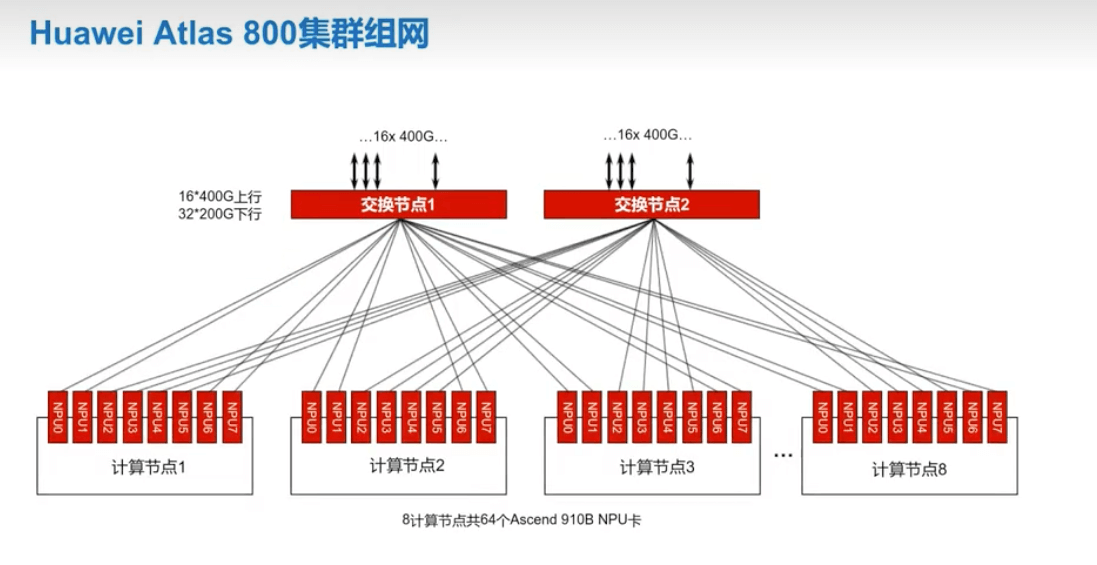
华为 Altas 800 集群组网时,通过一个外部交换机将各个 NPU 卡连接起来,组成一个参数面的网络。由于每个交换机的网卡是有限的,如果需要更大的网络就需要借助 Spine-Leaf 网络拓扑。
4.1 常用配置命令
- 设置 IP 地址和掩码
| |
-i 指定卡的编号。
- 设置 Roce 网卡默认网关
| |
- 设置网络检测对象
| |
这个 IP 主要用来设置检测网络状态,一般设置为网段内的网关地址。
- 使能 TLS
| |
4.2 常用检测命令
- 查看组网 IP
或者
| |
- 检查单节点内网卡 IP 的连通性
| |
- 查看通信端口连接状态
| |
- 卡健康状态
| |
- ECC
| |
- pci
4.3 常用组网命令
- 查看光模块状态
| |
- 查询 tls 状态
| |
- 测试连通性
| |
- 两节点全连接测试
| |
获取 ADDRESSES 变量设置在另外一台主机。
| |
4.4 测试跨机带宽
- 获取接收端卡的 IP
| |
- 接收端
| |
- 发送端
| |