mysql> explain select * from test_table where a = 0 and b = 0 limit 1; + | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | + | 1 | SIMPLE | test_table | NULL | ref | a_index,b_a_index | a_index | 4 | const | 997354 | 8.08 | Using where | +
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
mysql> show profiles; +----------+------------+-------------------------------------------------------------------------------+ | Query_ID | Duration | Query | +----------+------------+-------------------------------------------------------------------------------+ | 49 | 0.44619325 | select * from test_table where a = 0 and b = 0 limit 1 | | 50 | 0.466321 | select * from test_table where a = 0 and b = 0 limit 1 | | 51 | 0.45312325 | select * from test_table where a = 0 and b = 0 limit 1 | | 52 | 0.4334895 | select * from test_table where a = 0 and b = 0 limit 1 | | 53 | 0.48915875 | select * from test_table where a = 0 and b = 0 limit 1 | | 54 | 0.000488 | select * from test_table force index(b_a_index) where a = 0 and b = 0 limit 1 | | 55 | 0.0005185 | select * from test_table force index(b_a_index) where a = 0 and b = 0 limit 1 | | 56 | 0.0006425 | select * from test_table force index(b_a_index) where a = 0 and b = 0 limit 1 | | 57 | 0.00053575 | select * from test_table force index(b_a_index) where a = 0 and b = 0 limit 1 | | 58 | 0.00069475 | select * from test_table force index(b_a_index) where a = 0 and b = 0 limit 1 | +----------+------------+-------------------------------------------------------------------------------+
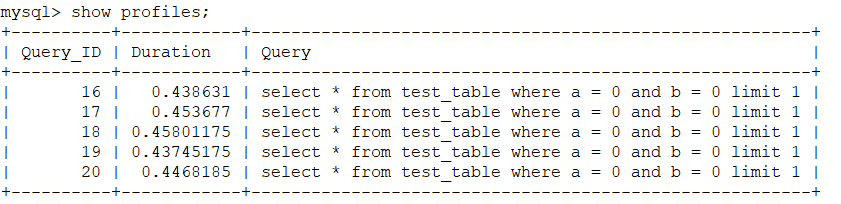
对于a_index索引,由于索引字段只有a,不能满足查询条件的a和b两个查询条件使用覆盖索引条件,因此该索引需要在where查询时就需要对数据进行回表操作。见下图数据分布,where a = 0 and b = 0的查询条件下,由于前30万条数据都是b=1,因此前30万条记录均不符合查询条件而导致30万条记录的回表操作,产生了30万次的回表性能浪费。
而对于b_a_index索引,该索引字段有a和b,对于where a = 0 and b = 0的查询条件下不需要做回表操作,直接通过innodb的B+Tree索引结构快速获取到一个符合查询条件的记录ID后,仅对该一条记录做回表操作即完成sql执行。因此性能消耗远远低于a_index索引。
之所以mysql的执行计划估算两个索引的执行成本相同,是因为mysql在评估执行成本时不考虑limit条件,即参与执行计划计算的sql是select * from test_table where a = 0 and b = 0。对于select * from test_table where a = 0 and b = 0的sql执行,a_index和b_a_index两个的索引的执行成本相同。虽然不知道innodb引擎在设计时为什么在执行计划过程中会不考虑limit条件,但这一现象,确实导致了当前场景下的索引失效问题。
解决
强制索引
拆分查询,将原sql拆成如下的右连接查询
1 2 3
select * from test_table where a = 0and b = 0limit1; select * from test_table forceindex(b_a_index) where a = 0and b = 0limit1 select * from test_table t1 rightjoin (selectidfrom test_table where a = 0and b = 0limit1) t2 on t1.id = t2.id;
1 2 3 4 5 6
mysql> explain select * from test_table where a = 0 and b = 0 limit 1; + | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | + | 1 | SIMPLE | test_table | NULL | ref | a_index,b_a_index | a_index | 4 | const | 997354 | 8.08 | Using where | +
1 2 3 4 5 6 7 8
mysql> explain select t1.* from test_table t1 right join (select id from test_table where a = 0 and b = 0 limit 1) t2 on t1.id = t2.id; + | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | + | 1 | PRIMARY | <derived2> | NULL | system | NULL | NULL | NULL | NULL | 1 | 100 | NULL | | 1 | PRIMARY | t1 | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100 | NULL | | 2 | DERIVED | test_table | NULL | ref | a_index,b_a_index | b_a_index | 8 | const,const | 997354 | 100 | Using index | +