![]()
Trust middleware for LLM agents: deterministic tool policy, HITL approvals, and tamper-evident audit traces. Alpha - read the implementation status before customer-facing pilots.
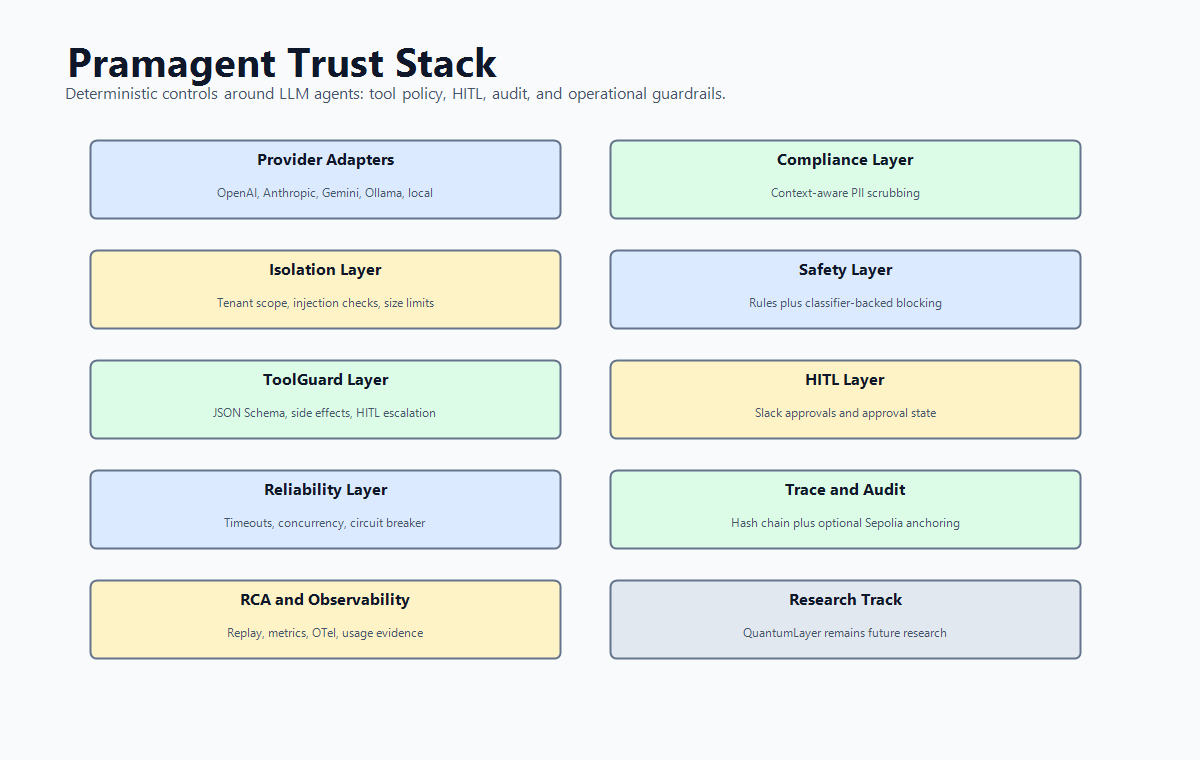
Pramagent wraps OpenAI, Anthropic, Gemini, Ollama, local, and OpenAI-compatible providers with guardrails that run outside the model. The most differentiated layer is ToolGuard: deterministic tool validation with JSON Schema, tenant/action allow-lists, side-effect taxonomy, dangerous-chain detection, output scanning, and HITL escalation. The current package also ships curated safety rule corpora, persistent HITL queues, thin adapters for popular agent frameworks, and compliance evidence generation.
Alpha Maturity Notice
Pramagent is published as Alpha software. It has live smoke-test evidence for Sepolia anchoring, S3 cold archive, local load testing, real OpenAI/Ollama provider calls, and bundled red-team runs, but it has not passed an external penetration test, SOC 2 audit, HIPAA assessment, or regulated-production certification.
Do not treat Pramagent as bank-grade or healthcare-grade security infrastructure. Do not claim prompt-injection immunity, production compliance, or third-party-validated safety from the bundled benchmarks alone. Read Implementation status, Live test results, and Hardening guide before using it in a customer-facing pilot. The June 11 active security prompt results are tracked in Security test results.
Bare Install Quickstart
This works with the base package only. No Docker, API server, or provider key is required.
import asyncio from pramagent import Pramagent async def main(): resp = await Pramagent().run("Summarize this request", tenant_id="demo", session_id="s1") print(resp.output) print(resp.trace.this_hash) asyncio.run(main())
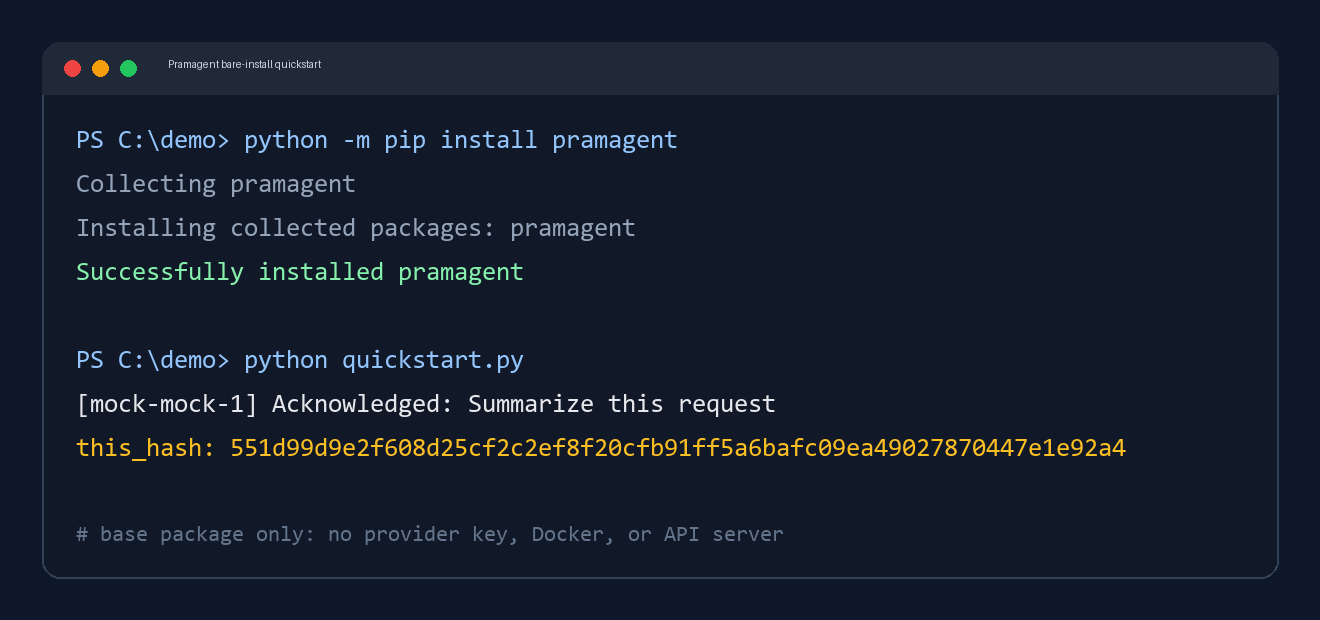
That creates a tamper-evident trace using the deterministic mock provider.
Swap to a real OpenAI model by setting OPENAI_API_KEY:
from pramagent import Pramagent from pramagent.providers import OpenAIProvider armor = Pramagent(provider=OpenAIProvider(model="gpt-4o-mini"))
Run against NVIDIA NIM with an nvapi-* key:
from pramagent import Pramagent from pramagent.providers import NvidiaProvider armor = Pramagent(provider=NvidiaProvider(model="meta/llama-3.3-70b-instruct"))
Frequently Asked Questions
How do I add safety guardrails to an LLM agent?
Install Pramagent and wrap your agent call with the trust stack. Pramagent
enforces deterministic policy outside the model, so the LLM cannot override the
tool policy, HITL gate, or audit chain by changing its own text output.
How do I audit AI agent decisions in production?
Every Pramagent call produces a hash-chained TraceEvent with layer decisions,
verdicts, provider metadata, PII redactions, HITL status, and this_hash /
prev_hash. The local chain can be verified and optionally anchored externally.
How do I prevent prompt injection in a Python LLM agent?
IsolationLayer scans inputs before the model sees them. It covers known
instruction overrides, chat-template wrapper attacks, authority framing,
base64/hex/unicode-escape encoded payloads, and targeted multilingual override
phrases. v0.8.0 adds structured classifier verdicts, held-out PINT/TensorTrust
style fixtures, provenance-aware stricter scanning for tool output and
retrieved content, and optional pramagent[ml] embedding/DeBERTa layers. This
is defense-in-depth, not proof of prompt-injection immunity.
How do I stop unsafe model output from reaching users?
OutputJudgeLayer runs an LLM-as-judge on every output before it returns — the
"is the OUTPUT safe?" check that regex cannot give. It catches semantic failures
deterministic rules miss (working malware, bypass walkthroughs, confirmed
destructive actions, leaked internals). On by default in the public demo, opt-in
for /v1/run (PRAMAGENT_OUTPUT_JUDGE=1). It is fail-closed, but it is itself a
model — strong defense-in-depth, not a guarantee.
How do I stop unsafe tool calls from an AI agent?
Use ToolGuardLayer with ToolPolicy. Pramagent validates JSON Schema,
tenant/action allow-lists, side-effect class, call frequency, argument
injection, and dangerous chains before any side effect can execute.
How do I add human approval to AI agent actions?
Use HITLLayer or a ToolGuard policy with Verdict.ESCALATE. Silence is never
consent: if approval does not arrive, the action remains unexecuted.
Does Pramagent work with OpenAI, Anthropic, Gemini, Ollama, and local models?
Yes. Pramagent ships provider adapters for OpenAI, Anthropic, Gemini, Ollama,
NVIDIA NIM, and OpenAI-compatible local endpoints, plus a deterministic mock
provider for tests.
Is Pramagent compliant with SOC 2, HIPAA, or the EU AI Act?
No. Pramagent includes compliance evidence mapping and tamper-evident logging
features that can support an assessment, but it has not passed SOC 2, HIPAA, EU
AI Act conformity assessment, or an external penetration test.
API And Dashboard Install
pip install "pramagent[api,dashboard,redis,postgres]"From source:
git clone git@github.com:sriram7737/pramagent.git cd Pramagent pip install -e ".[dev,api,redis,postgres,dashboard]"
CLI And Docker Quickstart
pramagent init pramagent validate
Run the local stack:
cp .env.example .env docker compose up -d
Open:
- API docs:
http://localhost:8080/docs - Dashboard:
http://localhost:8501
Public Live Demo
The API can serve a single-page NVIDIA NIM demo at /demo. It is disabled by
default and is meant for public evaluation, not production traffic.
PRAMAGENT_DEMO_ENABLED=true PRAMAGENT_DEMO_RATE_LIMIT=60 PRAMAGENT_ALLOW_MEMORY_STORE=1 uvicorn pramagent.api.app:app --host 0.0.0.0 --port 8080
The demo asks the visitor for their own nvapi-* key on each run. Pramagent
uses that key only for the current provider call; it is not written to traces,
logs, stores, usage records, or the hash-chain payload. Each demo run uses an
isolated in-memory trace store and returns the output, trust-layer events,
redactions, HITL state, latency, this_hash, prev_hash, and local chain
verification.
The public throttle is keyed by client IP plus a short in-memory SHA-256 hash
of the visitor's nvapi-* key. If a visitor switches to a different NVIDIA
key, they get a fresh demo bucket without Pramagent storing the plaintext key.
A DEGRADED demo result means the upstream model call failed and Pramagent
returned its safe default with a trace; try another listed NIM model or verify
that the key has access to the selected endpoint.
Run the release sanity checks:
python -m pytest -q --tb=no python -m pramagent.cli redteam --json --attacks 100 python -m pramagent.cli redteam --json --dynamic --attacks 200 --seed 999
Current local result: 640 passed, 2 skipped. The latest targeted prompt
suite also passed with 0 failures across emergency override, output override,
margin/liquidation, IBAN/SWIFT, ambiguous escalation, PHI, false-positive,
base64, hex, unicode-escape, multilingual override-token, and
chat-template-wrapper cases.
ToolGuard Example
import asyncio from pramagent import Pramagent, Verdict from pramagent.layers import ToolGuardLayer, ToolPolicy from pramagent.layers.tool_guard import SideEffect guard = ToolGuardLayer(policies=[ ToolPolicy( name="send_payment", side_effect=SideEffect.PAYMENT, action=Verdict.ESCALATE, allowed_tenants={"finance_team"}, schema={ "type": "object", "required": ["amount_usd", "destination"], "properties": { "amount_usd": {"type": "number", "minimum": 0.01, "maximum": 5000}, "destination": {"type": "string", "pattern": r"acct-\d{6,}"}, }, "additionalProperties": False, }, ) ]) armor = Pramagent(tool_guard=guard) async def main(): decision = armor.validate_tool( "send_payment", {"amount_usd": 250.00, "destination": "acct-123456"}, tenant_id="finance_team", session_id="demo", ) print(decision.verdict) # ESCALATE too_large = armor.validate_tool( "send_payment", {"amount_usd": 9000.00, "destination": "acct-123456"}, tenant_id="finance_team", session_id="demo", ) print(too_large.verdict, too_large.reason) # BLOCK: schema violation wrong_tenant = armor.validate_tool( "send_payment", {"amount_usd": 250.00, "destination": "acct-123456"}, tenant_id="marketing_team", session_id="demo", ) print(wrong_tenant.verdict, wrong_tenant.reason) # BLOCK: tenant mismatch response = await armor.run( "Summarize this payment request", tenant_id="finance_team", session_id="demo", action="send_payment", ) print(response.hitl) print(response.trace.this_hash) asyncio.run(main())
Built-In Rule Corpora
Pramagent now includes deterministic, importable rule bundles. They are plain
Python Rule objects, so a reviewer can inspect exactly what is enforced.
from pramagent import Pramagent from pramagent.layers import SafetyLayer from pramagent.rules import ALL_RULES, JAILBREAK_PATTERNS, OWASP_LLM_TOP10 armor = Pramagent( safety=SafetyLayer(rules=[*JAILBREAK_PATTERNS, *OWASP_LLM_TOP10]) ) strict_armor = Pramagent(safety=SafetyLayer(rules=ALL_RULES))
Included corpora:
JAILBREAK_PATTERNSOWASP_LLM_TOP10INJECTION_CORPUSFICTIONAL_WRAPPERPHI_PATTERNSFINANCIAL_PII
Escalation Policy
Verdict.ESCALATE means "suspicious, but not certain enough to block." What
the pipeline does with it is configurable per stage — pre (the input pass,
before the model runs) and post (the output pass, after) — with one of
"log" (record and continue), "hitl" (route to the human-in-the-loop gate,
idle-on-silence), or "block" (hard stop). The default is "log" so adding an
ESCALATE rule never silently starts gating traffic; the ESCALATE verdict is
always recorded in the trace either way.
# Healthcare / finance — maximum caution Pramagent(safety=SafetyLayer(rules=[...]), escalate_policy={"pre": "hitl", "post": "block"}) # Developer tool — minimal interruption (default) Pramagent(safety=SafetyLayer(rules=[...]), escalate_policy="log") # Internal enterprise — gate suspicious input, log suspicious output Pramagent(safety=SafetyLayer(rules=[...]), escalate_policy={"pre": "hitl", "post": "log"})
A string applies to both stages; a dict sets them independently. Invalid values raise at construction, not at request time.
Persistent HITL Queue
For approval flows that must survive process restarts, use the persistent queue backends:
from pramagent.layers import HITLLayer from pramagent.queue import SQLiteHITLQueue hitl = HITLLayer( require_approval_for=["send_email", "wire_transfer"], store=SQLiteHITLQueue("hitl.db"), timeout_s=None, # wait until another process approves or denies )
InMemoryHITLQueue, SQLiteHITLQueue, and PostgresHITLQueue are available
under pramagent.queue.
Framework Adapters
Pramagent is meant to sit under existing agent frameworks, not replace them.
from pramagent.adapters import PramagentNode, PramagentHook, PramagentGuard # LangGraph guard_node = PramagentNode(armor=armor) # AutoGen PramagentHook(armor=armor).attach(agent) # CrewAI safe_tool = PramagentGuard(armor=armor).wrap_tool(send_email)
Generic helpers are also available:
from pramagent.adapters import protect, protect_tool
Compliance Evidence
ComplianceReporter.generate() can produce point-in-time evidence packages
from Pramagent traces and mappings:
from pramagent.compliance import ComplianceReporter ComplianceReporter(store=store, audit=audit).generate( framework="SOC2", period_start="2026-01-01", period_end="2026-06-30", tenant_id="demo", output="evidence.json", )
Supported mapping targets include SOC2, HIPAA, GDPR, NIST AI RMF, EU AI Act, and PCI DSS. This is engineering evidence, not a certification.
When To Use Pramagent
- You are wrapping LLM calls or agent workflows and need audit trails, policy checks, HITL approvals, PII scrubbing, and provider fallback in one place.
- You want deterministic tool policy outside the model, especially for actions like payments, data export, account changes, or admin operations.
- You are building an internal tool or pilot where honest safety evidence matters more than marketing claims.
- You need tamper-evident traces with optional Sepolia anchoring and encrypted S3 cold archive support.
- You already use LangGraph, AutoGen, CrewAI, or a custom loop and want a thin trust layer around prompts, tool calls, and approvals.
When Not To Use Pramagent Yet
- You need certified bank-grade, healthcare-grade, or SOC2-audited production infrastructure today.
- You need proven jailbreak resistance against a serious red team; the bundled benchmark is only a deterministic smoke test, not third-party assurance.
- You need mature enterprise dashboard auth such as SSO/OIDC/RBAC. Optional generated dashboard keys and SQL users exist, but this is not an enterprise IAM plane yet.
- You need production-grade scale evidence, chaos engineering, or SLA-backed capacity numbers beyond the published local Docker Compose load run.
- You need billing-grade Stripe/Chargebee metering rather than the local usage ledger and event hooks.
What Works Today
| Capability | Status | Notes |
|---|---|---|
| Provider adapters | Implemented | Mock, OpenAI, Anthropic, Gemini, Ollama, OpenAI-compatible/local |
| Rule corpora | MVP | 129 deterministic rules across jailbreaks, OWASP LLM risks, injection, fictional-wrapper bypasses, PHI, and financial PII |
| ToolGuard | Strong MVP | Draft 2020-12 JSON Schema, allow-lists, side-effect taxonomy, output scanning, Redis-backed chain state |
| HITL | Beta | Slack callbacks, persistent SQLite/Postgres queues, quorum/escalation primitives, ServiceNow/PagerDuty/email/webhook notifiers |
| Audit trail | Strong MVP | SHA-256 hash chain; optional real Sepolia anchoring |
| PII redaction | Strong MVP | Context-aware patterns for common regulated data; bounded email scrubbing avoids long-input regex DoS |
| Auth/rate limits/quotas | Beta | JWT/API keys, token buckets, per-tenant quotas |
| Framework adapters | MVP | LangGraph node, AutoGen hook, CrewAI guard, generic protect/protect_tool helpers |
| Dashboard | Prototype | Shared-key fallback, optional SQL users with generated keys, tenant scoping, traces, approvals, metrics, usage page, CSRF |
| Redis/Postgres backends | Beta | Wired and tested locally; needs scale/load testing |
| OpenTelemetry | Partial | Per-layer spans exist; dashboards and alerting need hardening |
| Red-team benchmark | MVP | Static and dynamic mutation modes; includes base64, translation-wrapper, and authority-framing regressions |
| Billing hooks | MVP | In-memory hash-chain usage ledger plus fail-open webhook; no Stripe/Chargebee provider yet |
| S3 cold archive | MVP | Gzip + encrypted trace archive wrapper; metadata sink hook |
| Compliance evidence | MVP | ComplianceReporter.generate() for JSON/text/PDF-style evidence packages |
Integration Safety Contract
Pramagent should not replace human workflows that already work. Treat it as a policy and evidence layer around risky agent actions, not as a mandate to put AI into every decision path.
Before integrating a new feature or agent workflow, require three gates:
- Isolation contract: declare which trust layers the feature touches. HITL features need a negative test proving the action cannot proceed without an authenticated approval. Isolation features need tenant/session boundary tests.
- Regression baseline: run the full suite plus the new feature tests. Zero regressions are allowed for previously passing safety, trace, auth, and store behavior.
- Consequence traceability: every approved or triggered action must leave a trace that explains why it was allowed, who/what approved it, what policy applied, and which downstream side effect was attempted.
The reusable reviewer prompt for this is in Security audit prompt.
Honest Limits
- Prompt-injection defense is not complete. The bundled static corpus and
seeded dynamic mutation smoke tests now include base64, translation-wrapper,
and authority-framing regressions. v0.8.0 adds structured verdicts,
provenance-aware stricter scanning, held-out PINT/TensorTrust-style fixtures,
and optional
pramagent[ml]embedding/DeBERTa layers, but the project still needs larger third-party red-team sets and external assessment. - ToolGuard is a hard policy gate outside the model, but it is not a sandbox.
- ToolGuard chain detection and per-session call limits are per-process unless
a shared Redis backend is configured (
PRAMAGENT_TOOL_GUARD_REDIS_URLorPRAMAGENT_REDIS_URL). When running multiple uvicorn workers, a dangerous tool chain whose steps land on different workers is only detected with a shared Redis backend; the Redis path uses an atomic Lua append so concurrent same-session calls never lose history. - Slack is the main decision-collecting HITL adapter today. ServiceNow, PagerDuty, email, and generic webhooks are useful notification/escalation adapters. Persistent SQLite/Postgres approval queues exist, but broader enterprise approval workflows are still in development.
- Dashboard auth has tenant-scoped shared-key fallback plus optional SQL-backed users with generated dashboard keys and key regeneration. It is still not SSO/OIDC/RBAC-grade.
- Ethereum anchoring is Sepolia/testnet-oriented; no mainnet runbook, verifier contract, HSM/KMS key-management story, or enterprise anchoring operating model is included yet.
- The usage ledger is local audit evidence for pilots, not an invoice-grade billing system.
- Redis/Postgres support exists, but the stack has not been chaos-tested or load-tested for high-stakes deployments.
- No external penetration test or formal compliance certification has been run.
- QuantumLayer is future research only. It is not implemented, advertised as a feature, or exposed as a production API.
Optional Anchoring And Archive
pip install "pramagent[ethereum,s3]"Ethereum/Sepolia anchoring submits the audit head as transaction calldata and stores the tx hash plus block number on the trace when configured. S3 cold archive wraps a primary store and archives pruned/erased traces as encrypted gzip JSON while keeping metadata available for compliance reporting.
Demo Flow
pramagent init docker compose up -d python -m pytest -q --tb=no python -m pramagent.cli redteam --json --dynamic --attacks 200 --seed 999
Then use the dashboard to inspect traces, pending HITL approvals, audit status, metrics, and per-tenant usage.
Docs
- Implementation status
- Live test results
- Hardening guide
- Google Dev Library submission draft
- Cookbook submission plan
- Security test results
- More documentation
Author
License
Apache-2.0.