缘由:Kitex文档的一致性哈希实现负载均衡,好吧,我连什么是一致性哈希都不知道
一、传统哈希取模算法的局限性
1.1 节点增加、减少
任何节点的故障或临时增加我们都只希望性能上有所降低,而不是服务受到影响。
对于传统哈希算法,节点的增加、减少会导致键与节点的映射关系发生变化。对于已有的键来说,将导致节点映射错误。
1.2 结论
当集群中节点的数量发生变化时,之前的映射规则就可能发生变化。
对于分布式缓存,映射规则失效意味着之前缓存的失效,若同一时刻出现大量的缓存失效,则可能会出现 “缓存雪崩”,这将会造成灾难性的后果。
要解决此问题,我们必须在其余节点上重新分配所有现有键,这是非常昂贵的操作,并且可能对正在运行的系统产生不利影响。
二、一致性哈希算法
Wiki: https://zh.wikipedia.org/wiki/%E4%B8%80%E8%87%B4%E5%93%88%E5%B8%8C
一致性哈希算法是在哈希算法基础上提出的
哈希算法应该满足的几个条件:
- 平衡性:是指 Hash 的结果应该平均分配到各个节点
- 单调性:是指在新增或者删减节点时,不影响系统正常运行
- 分散性:是指数据应该分散地存放在分布式集群中的各个节点(节点自己可以有备份),不必每个节点都存储所有的数据
2.1 对象、服务器哈希
通过一致性哈希环(Hash Ring)实现。这个环的起点是 0,终点是 2^32 - 1,并且起点与终点连接,故这个环的整数分布范围是 [0, 2^32-1]
其实终点可以自定义,或许这个数字来源为IP地址为32位
点由哈希函数再取模得出
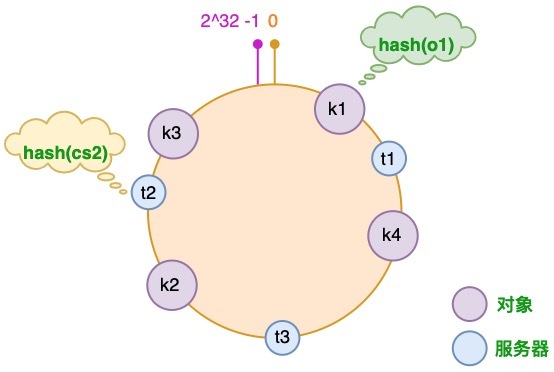
k1 k2 k3 k4 为四个对象哈希后的位置
t1 t2 t3 为三个服务器哈希后的位置,可以选择服务器的IP或主机名等等作为键
2.2 映射规则
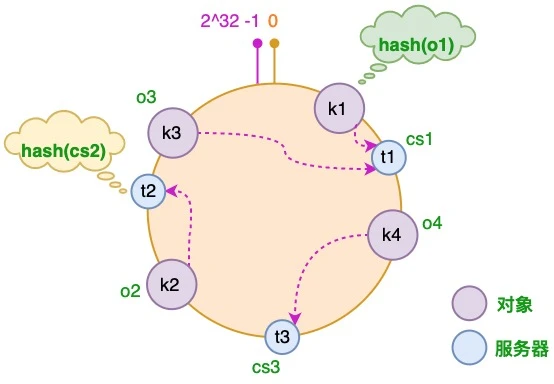
将对象和服务器都放置到同一个哈希环后,在哈希环上顺时针查找距离这个对象的 hash 值最近的机器,即是这个对象所属的机器。
以 o2 对象为例,顺序针找到最近的机器是 cs2,故服务器 cs2 会缓存 o2 对象。
而服务器 cs1 则缓存 o1,o3 对象,
服务器 cs3 则缓存 o4 对象。
2.3 服务器增加
假设由于业务需要,我们需要增加一台服务器 cs4
经过同样的 hash 运算,该服务器最终落于 t1 和 t2 服务器之间
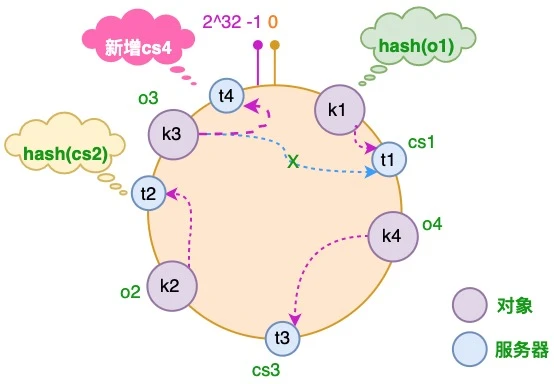
可见,只有 t1 和 t2 之间的对象需要重新分配
2.4 服务器减少
假设 cs3 服务器出现故障导致服务下线
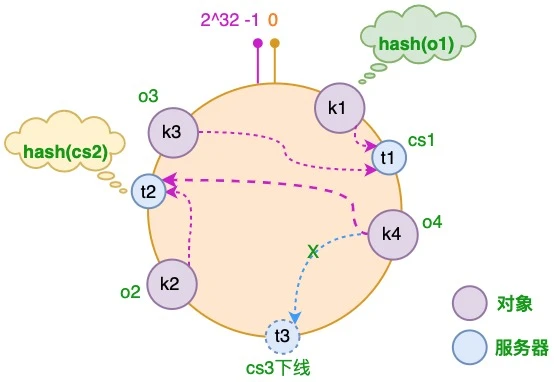
可见,只有 t2 和 t3 之间的对象需要重新分配
2.5 数据倾斜与解决方案
当物理节点数量较少时,一致性哈希的平衡性是有问题的
- 某些节点承担的
key非常多,一些节点却非常少。一旦负载较多的物理节点挂了,容易造成缓存雪崩。 - 纯物理节点无法实现权重分配
我们可以创造出一组虚拟节点,再让虚拟节点向物理节点映射,解决了以上两点
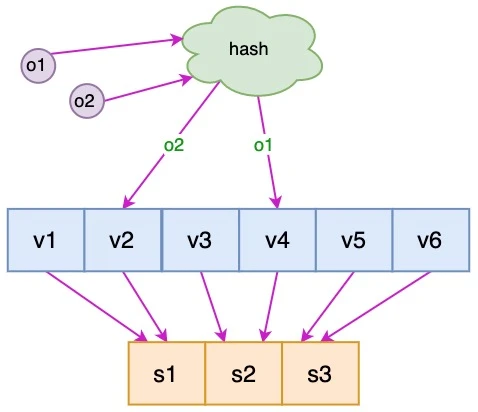
虚拟节点数越大,内存和计算代价越大,负载越均衡
在 Kitex 的文档中
推荐 VirtualFactor * Weight(如果 Weighted 为 true)的中位数在 1000 左右,负载应当已经很均衡了
推荐 总虚拟节点数 在 2000W 以内(1000W 情况之下 build 一次需要 250ms,不过为后台 build 理论上 3s 内均无问题)
2.6 依旧存在的缺点
- 哈希环结构的存在,无法手动管理和精细化控制
- 哈希环上的虚拟节点非常多或者更新频繁时,查找和迁移计算性能会比较低下
Redis 作为著名的分布式缓存系统,其 Sharding 采用的并不是一致性哈希,而是哈希槽,在一定程度上解决了以上问题
开源库实现
参考
相关文章实在是太多了