没有发布芯片,但这场发布会还是“出圈”了。
5 月 18 日,摩尔线程在北京举办主题为“词元时代,万物智能”的年度产品发布会,现场座无虚席。摩尔线程用接近 2 个小时的时间,一口气完成六大重磅发布:
从万卡级规模的夸娥智算集群,到自研“长江”SoC 驱动的智能终端 MTT AICUBE 和 MTT AIBOOK;从数字世界智能体“小麦”,到加速物理 AI 落地的首个全栈具身智能仿真平台 MT Lambda,再到持续进化的 MUSA 生态。
摩尔线程全面展示了一个覆盖“云 - 边 - 端”的全栈智算矩阵,每个都值得深入讨论。但在笔者看来,这场发布会带来的最大惊喜,是压轴发布的 MUSA 生态进化。
过去几年,国产 GPU 已经验证了硬件能力。通过架构迭代、工程优化,国产 GPU 是能够在硬件上交出高分答卷的。但企业采购 GPU 从来不是只买一张卡,而是在押注其背后的软件生态和开发体系。摩尔线程用一场发布会向开发者证明,MUSA 不只是国产 GPU 的生态底座,更是一个开放、自进化、与开发者共同成长的智能生态。
在过去很长一段时间里,国产 GPU 软件生态与全球主流开源生态之间,始终存在一道微妙的裂痕。国产 GPU 能支持不少主流框架运行,却少有人能进入真正的牌桌,融入全球开源生态。
这意味着,即便开发者能在国产 GPU 上完成训练或推理任务,但需要做的额外工作一点也不少。最显著的代价是,维护成本高昂。同样的模型跑在国产 GPU 上,如果缺乏原生支持,开发者需要针对不同训练或推理框架单独维护适配层,不少核心算子也无法直接调用,需要开发者手动替换实现方案,甚至重新编写部分 kernel。如果上游框架迭代,开发者还需要投入额外的精力维护 patch、跟进版本更新和兼容测试。
开发者用大量的时间和精力,填补生态上的空白。这也是为什么,MUSA 近期在开源生态层面的进展,值得拿来放到发布会上压轴讨论。
在当前最主流的两个大模型推理框架 SGLang 和 vLLM 上,MUSA 都带来了好消息:
SGLang 方面,MUSA 后端正式加入 SGLang 的官方支持体系,相关代码也已成功合入 SGLang 主线。截至 5 月 12 日,摩尔线程已向 SGLang 提交 47 个 PR,其中 41 个完成合并,并成功进入 SGLang 2026 年 Q2 官方硬件支持矩阵,与 GB200/GB300、AMD、TPU 等主流算力平台并列。
vLLM 方面,MUSA 成为 vLLM 的官方后端,并开源 vLLM-MUSA,开发者可原生获得摩尔线程 GPU 加速能力。
与单纯地多支持了一个框架相比,加入大模型推理框架官方后端矩阵意味着,国产 GPU 在生态适配上拥有更充分、更直接的兼容路径。以 SGLang 为例,无论开发者使用的是 SGLang 框架本体 sglang、高性能算子库 sgl-kernel,还是多模态生成组件 multimodal_gen,都能在原生框架环境中直接调用摩尔线程 GPU,开发者不需要维护额外分支或适配层,就能在熟悉的工作流中完成推理部署和性能优化。
除了推理框架,摩尔线程在底层编译生态上也有关键进展。
据介绍,摩尔线程正与智源研究院合作推进 Triton 生态,Triton-MUSA 已升级支持至 Triton 3.6 最新版本。基于 Triton 的 FlagOS 正在成为连接不同 AI 芯片的软件中间层,其重要性不言而喻。此前,在一场由摩尔线程举办的技术 Meetup 上,智源研究院展示了打通多种 AI 芯片的统一开源软件栈 FlagOS,其 FlagGEMs 算子库已涵盖超 497 个算子,并依托 FlagTree 编译器与 Triton-TLE 语言扩展,实现了跨芯片的高性能算子生成。
这一能力已经在实际场景中得到验证。以 DeepSeek-V4 的 Day0 适配为例,基于摩尔线程专用张量加速引擎与 FlagOSTune 调优方案,模型首 Token 返回时延(TTFT)降低 56.7%,吞吐量提升 65.7%。
从这个角度看,Triton-MUSA 升级更大的意义在于,开发者可以基于 Triton 这一主流高性能算子开发工具,在 MUSA 上进行更高效的算子开发与优化,进一步降低底层开发门槛。
在全球开源社区中,TileLang-MUSA 已成功合入开源主线。作为近一年快速崛起的热门开源社区,TileLang 开源不足一年便斩获超 6000 Stars,其目标是解决 Triton 等现有方案在极致性能控制上的不足,让开发者用更少的代码实现专家级的算子性能。
目前,TileLang 正与 MUSA 生态深度联调,共同构建适配摩尔线程全功能 GPU 的高性能算子库。在 GEMM 类算子上,已经实现了 95% 以上的汇编级性能效率,Attention 类算子也达到了 90% 以上的效率。
从 SGLang 到 vLLM,再到 Triton、TileLang,MUSA 正在加速进入主流开源生态,串联起从上层应用到底层优化的完整路径。降低开发者维护成本的同时,也让国产 GPU 更有可能被大规模采用。这或许才是国产 GPU 生态走向成熟的重要分野。
降低维护成本决定了开发者能否长期留下来,但在这之前,决定开发者是否愿意用起来的,是迁移成本。
正如前文所说,企业采购 GPU 从来不是只买一张卡,而是在押注其背后的软件生态和开发体系。代码能否复用、框架能否兼容、工作流是否需要重构,往往比单纯的算力参数更影响最终决策。
此次发布会上新的 MUSA SDK 5.1.0,直指的正是迁移痛点——它完全对标 CUDA 12.8,后者为 Blackwell 架构提供了完整、全工具链的支持,也是当前业界广泛使用的主力版本。

升级后,基于 CUDA 12.8 开发的 AI 模型、科学计算应用,都能以极高的效率运行在摩尔线程 GPU 上。MUSA 软件栈全链路覆盖了底层驱动、编译器、算子加速库、训练与推理框架,并且迁移流程得到了大幅简化:
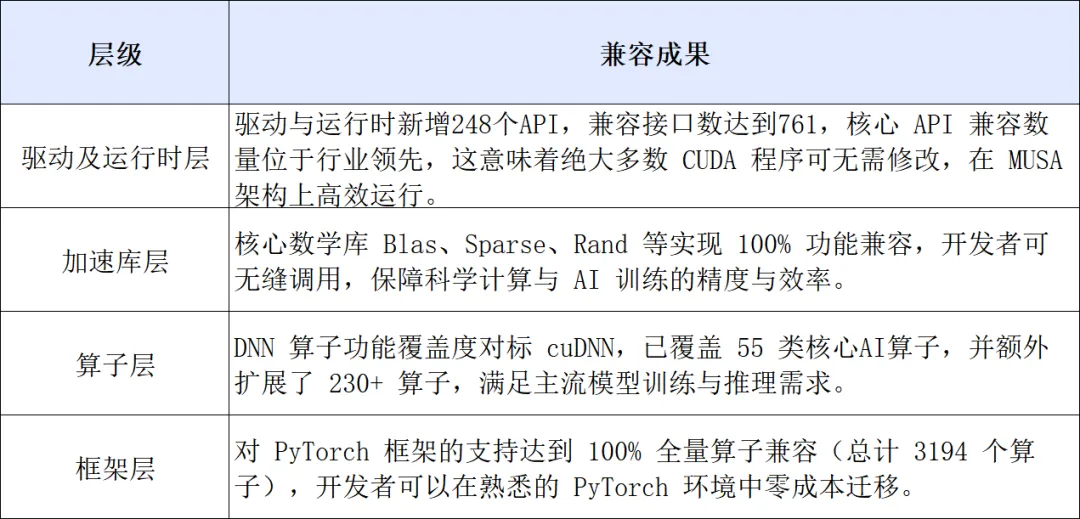
兼容只是第一步,决定开发者体验的,还有性能。针对 FlashAttention3、Sage Attention、DSA、GDN、DeepGEMM 等当前业界最常用的计算算子,摩尔线程推出了 MATE(MUSA AI Tensor Engine)加速库,并围绕核心算子进行了专项性能增强。
其中,FlashAttention3 在摩尔线程 GPU 上的计算效率高达 95%,整体热点算子覆盖率突破 90%。在 Attention 类算子上,MATE 已实现全场景、全覆盖支持,为大规模语言模型提供了核心性能保障。
这些数据代表的是,迁移不再以牺牲性能为代价,开发者将现有 CUDA 应用迁移至 MUSA 后,在热点计算环节的实际运行速度与原有平台几乎无差别。
为了提升开发者应用体验,摩尔线程还提供了“产品化”的训练与推理套件。比如在训练侧,基于 MTT S5000 全功能 GPU 的超大规模集群训练能力已实现全面产品化,同时,强化了对强化学习的支持,兼容业界主流的 VeRL 与 Slime 框架,并完成了对多项微调框架的适配。无论是千卡集群训练,还是模型微调,MUSA 都能提供稳定高效的开发体验。
从兼容 CUDA,到强化热点算子性能,再到训练与推理能力产品化,这些“上新”直指的,是国产 GPU 在过去很长一段时间里,最深层的痛点——迁移门槛太高了。
过去,开发者迁移至国产 GPU,既要考虑底层兼容性问题,比如接口差异、调用习惯,又要考虑性能,比如算子执行效率是否打折。此外,训练和推理环境本身也存在迁移成本。一次迁移,往往需要重新验证训练流程、部署推理框架、适配集群环境和工具链。
本次 MUSA 的更新,本质上就是在逐层拆解这些迁移障碍。这些变化对于开发者真正的意义,不只是把迁移门槛打下来。更重要的是,它尽可能保留了开发者既有的开发习惯和工作流,让整个迁移几乎零成本。
从进入主流开源生态到 100% 兼容,不难看出,上市后的摩尔线程,技术路线更加清晰了,也再次印证了摩尔线程创始人、董事长兼 CEO 张建中此前的判断:生态体系才是 GPU 行业的核心护城河与价值所在。
过去十多年,英伟达围绕 CUDA 构建起来的 API、编译器、算子库、框架适配和开发者社区,铸就了其坚实壁垒。MUSA 的路径,某种程度上也是在验证这一逻辑。但不同的是,摩尔线程试图用更高效率的方式补齐生态短板——引入 AI 技术加速生态的自我演进。
为了降低 MUSA 编程门槛,本次发布会上,摩尔线程带来了面向开发者打造的新一代 AI 编程工具 MUSACODE。

MUSACODE 支持自然语言生成代码,能实现 30 天自动生成、测试 PP 库 12015 个算子,并基于 TileLang 自动调优 Group GEMM 算子实现 60% 性能提升。此外,MUSACODE 还支持 Python、C++、Rust、Go 等多种主流语言,并提供 MUSA VSCode Edition 官方插件,支持代码完全在本地端侧运行,保护企业的隐私与数据安全。
在编程辅助之外,摩尔线程还进一步引入了 AI Agent 自动化迁移体系,从工具层、基础层到使用层,全方位降低开发者接入门槛。

在工具层,Automusify Skill 能够实现零干预、自动化地将现有工程迁移至 MUSA 平台,无需手动修改代码,极大提升迁移效率;在基础层,实现了对 Top 100 人工智能与 Top 100 科学计算两大领域加速仓库的 100% 自动迁移;在使用层,MUSA 提供了加速库在线源,开发者可通过在线源直接获取编译后的仓库及开源代码,真正做到即拿即用、开箱即跑。
从自动迁移工具,到兼容核心 API,再到在线加速库和 AI 编程助手,摩尔线程正试图用一条完整的自动化链路,将生态建设从人力追赶推进到自进化。
在一众国产 GPU 厂商中,为什么是摩尔线程率先把生态建设推到这一阶段?
背后的答案,或许就藏在其长期坚持的技术路线中。
不同于单一场景导向的 GPU 产品思路,摩尔线程一直走的是 基于统一系统架构的全功能 GPU 路线,同一颗芯片同时支持 AI 计算、图形渲染、物理仿真和超高清视频编解码,具备极高的全场景全栈计算通用性。
也正因此,MUSA 从诞生之初就被放在了核心战略位置。
回看近几年摩尔线程围绕 MUSA 的持续投入,无论是硬件架构迭代、软件栈补齐,还是如今加速融入主流开源生态、引入 AI 驱动生态自进化,可以看出,摩尔线程对于 GPU 竞争终局的判断一直围绕着一个主线:开发者。
硬件层面,MUSA 架构从 2021 年的“苏堤”起步,历经“春晓”、“曲院”、“平湖”,再到去年年末预告的“花港”,持续围绕全功能 GPU 能力演进。相比聚焦单一 AI 场景的产品路线,统一系统架构能让开发者基于更统一的算力底座进行开发和部署,这本身就是开发效率的重要保障。
软件层面,从早期补齐驱动、运行时和编译器等基础能力,到逐步完善数学库、算子加速库、训练与推理框架支持,再到持续提升 CUDA 兼容能力并接入 SGLang、vLLM、Triton、TileLang 等主流开源生态,MUSA 正通过降低迁移成本让开发者用起来、降低维护成本让开发者留下来。
相比单纯比拼硬件参数,摩尔线程显然更早意识到,GPU 行业的竞争终局,从来不只是芯片本身,而是谁能赢得更多开发者。只有当开发者愿意用起来、留下来,一家 GPU 厂商才真正拥有长期竞争力。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。