距离正式上线华为云还有两个月,华为的最新 AI 芯片昇腾 950DT,已经被提前放到了显微镜下。
近日,华尔街知名半导体研究机构 SemiAnalysis 已经率先拿到样机,围绕 950 系列运行 DeepSeek V4 的推理链路进行了 Trace 级拆解。
从芯片架构、并行调度、融合算子到 MoE 通信,报告深度解构了华为这款国产高端 AI 芯片是如何压榨极致性能,承接 DeepSeek V4 的核心推理负载需求的。(注:芯片的 Trace 分析是指利用专用软硬件记录芯片内部程序的运行轨迹、时序和性能数据)
值得注意的是,这不是一次普通的“适配”分析。SemiAnalysis 在报告中明确提到,DeepSeek V4 的部分架构,是为华为昇腾推理进行协同设计的,“in part co-designed for Huawei Ascend inference”。
也就是说,昇腾 950DT 并非在模型发布之后被动接入 DeepSeek V4,而是更早参与到了模型推理路径、硬件执行方式和软件栈优化的共同打磨中。
这也是 950 系列真正值得关注的地方。它有望成为推动 DeepSeek 从英伟达底座 转向 国产昇腾底座的关键节点,而这种迁移与转向往往是不可逆的。
过去,国产 AI 芯片一直被放在“能不能替代英伟达”的叙事下讨论。但 DeepSeek V4 把问题往前推了一步:它不是简单证明国产芯片能跑大模型,而是开始验证国产芯片能否支撑得起顶级模型的低成本、高并发推理。
在 DeepSeek V4 官方技术报告中,昇腾 950 已经与英伟达 H100/H800 一起进入硬件验证名单。950 系列可分为两个版本:950PR 面向 Prefill 和推荐场景,950DT 则面向 Decode 和训练场景。
前者解决当下供给,后者瞄准大模型推理里最烧钱的一段。
在训练端,由于此次 V4 放弃了多头注意力机制 MLA(Multi-head Latent Attention),首次采用了全新的压缩稀疏注意力机制 (CSA) 、高度压缩注意力机制 (HCA)架构。对此,华为官方直言“离不开昇腾 950 超节点的协同”。
推理端,V4 把百万上下文的价格打到 2 毛钱,较 Anthropic 便宜 50 倍左右,这背后同样少不了双方在底层芯片、推理框架、低精度计算和通信优化的共同作用。
换句话说,DeepSeek 的“价格屠夫”标签,不只是模型侧的胜利没,更是一场由模型架构、芯片带宽、编译器、融合算子、推理框架和云服务共同参与的成本战役。
昇腾 950DT 的含金量,正体现在它进入了 DeepSeek 这套成本结构的核心环节。
而这种成本优势,反映到市场上则是极具竞争力的商业价值。根据 Vercel 最新发布的 5 月 AI Gateway 生产指数,随着 4 月 DeepSeek V4 上线,DeepSeek 的 Token 流量份额从不足 1% 快速升至 17%,超越 OpenAI,位居第三,在一众海外模型中杀出重围。
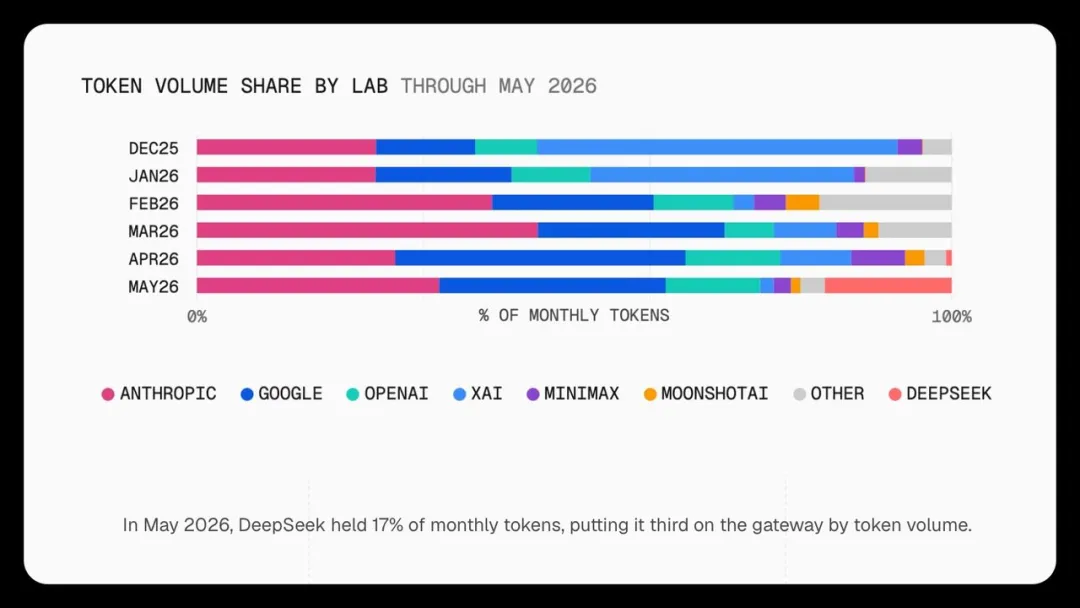
流量爆发的背后,价格是最直接的驱动力。
DeepSeek 早些时候在官网明确指出:“预计下半年昇腾 950 超节点批量上市后,Pro 的价格会大幅下调。”
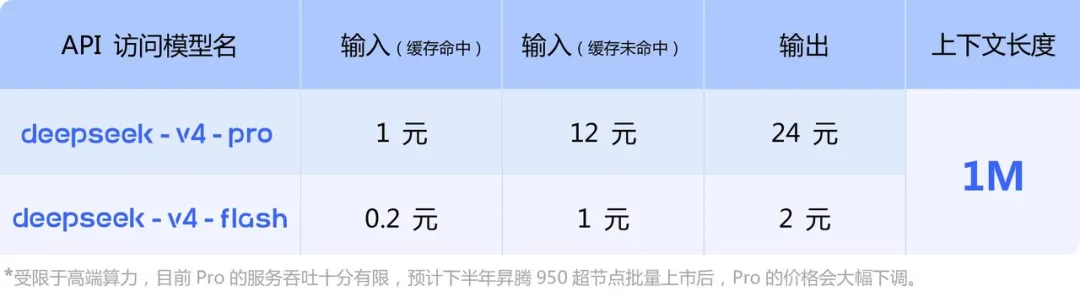
随后,便宣布 DeepSeek-V4-Pro API 永久降价至原价格的四分之一。这也直接印证了 V4 的 API 正深度依赖 950 部署,且成本结构仍有极大的优化空间。
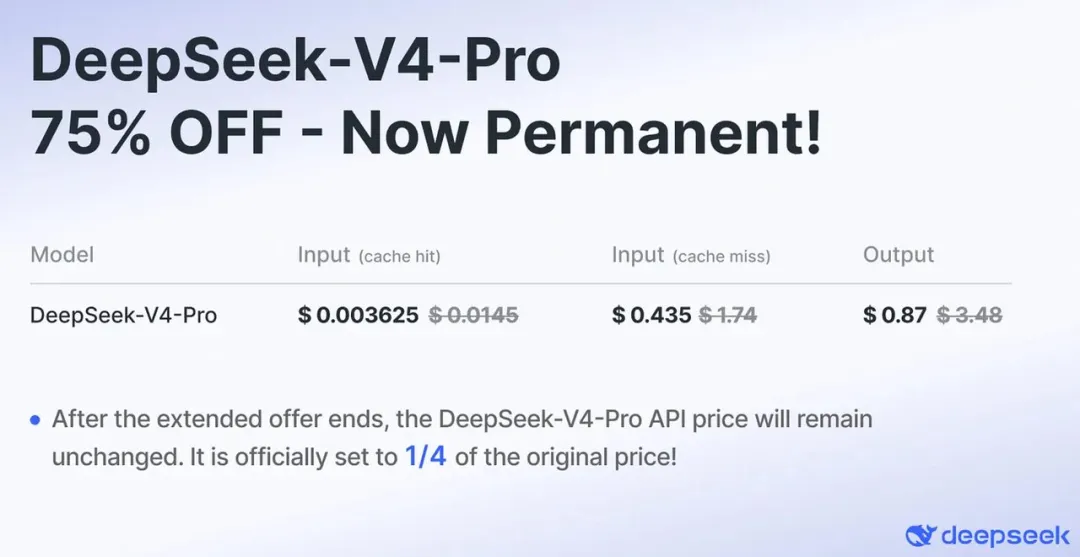
DeepSeek V4 的强大背书,给了 950DT “产品层面可验证”的底气,随即点燃了互联网大厂的采购热情。(注标题里的 BAT 指字节、阿里与腾讯)
4 月以来,昇腾 950 系列订单持续升温。据此前路透社报道,字节已拿下一半产能,阿里、腾讯分别跟进数十万颗。中国移动在 2026-2027 年度 AI 超节点设备集采清单中,也指定了 776 套昇腾节点设备,折合 6208 张 AI 加速卡。
所以,SemiAnalysis 的这份报告,不仅是全网首份在 950DT 正式上市之前、对其推理架构进行 trace 级别拆解的分析,也是 DeepSeek 与昇腾强耦合研发、国产大模型基于国产芯片进行原生开发的首次揭秘。
950 系列共用同一颗 Ascend 950 Die,采用双 Die UMA(统一内存访问)架构——两颗 Die 通过高带宽总线直连,在操作系统层面呈现为单一设备,而不是两块需要显式通信的独立芯片。
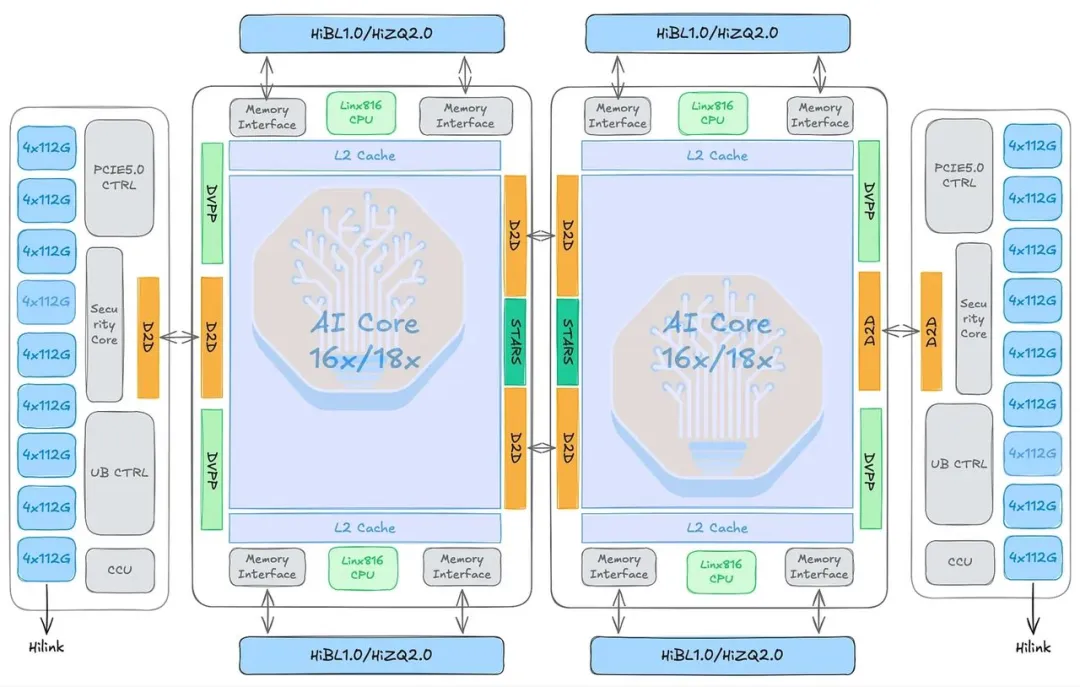
由于采用了不同的封装内存方案,950 系列分两个版本:950PR 和 950DT。
• 950PR(Prefill and Recommendation):今年 3 月已量产,面向推理预填充阶段和推荐系统,侧重成本优化
• 950DT(Decode and Training):搭载华为自研 HiZQ 2.0 内存,144GB 容量,带宽 4TB/s,专为
Decode 阶段和大模型训练设计,8 月上线华为云
Decode 阶段是典型的访存密集型任务,模型每次生成一个 token 都需要从内存里读大量 KV cache,带宽的提升直接对应吞吐的提升。这也是 950DT 命名里 "D" 的意义所在。
值得一提的是,华为在 CANN 内部代码库中,把昇腾 950 系列的代号定为 "David"。这个名字在多处源码文件中都有引用。
在某种程度上,也可以解读为,华为自己选择了”巨人对少年“的隐喻:弱者拒绝在强者最强的维度上竞争,用一个精准的点,打中对方的软肋。事实上,“以小博大”的精髓在昇腾和 DeepSeek 两个团队身上都有极致的展现。

(注:David 出自《圣经·撒母耳记》。以色列少年牧童大卫(David)面对的是非利士人的巨人武士歌利亚(Goliath),身高近三米、全身铠甲。大卫没有跟他正面硬拼,而是用一根弹弓投出一颗石子,精准击中歌利亚额头,当场将其击倒。)
从芯片内部看,Ascend 950 Die 包含四类关键执行单元,后面所有优化都建立在这套分工之上。
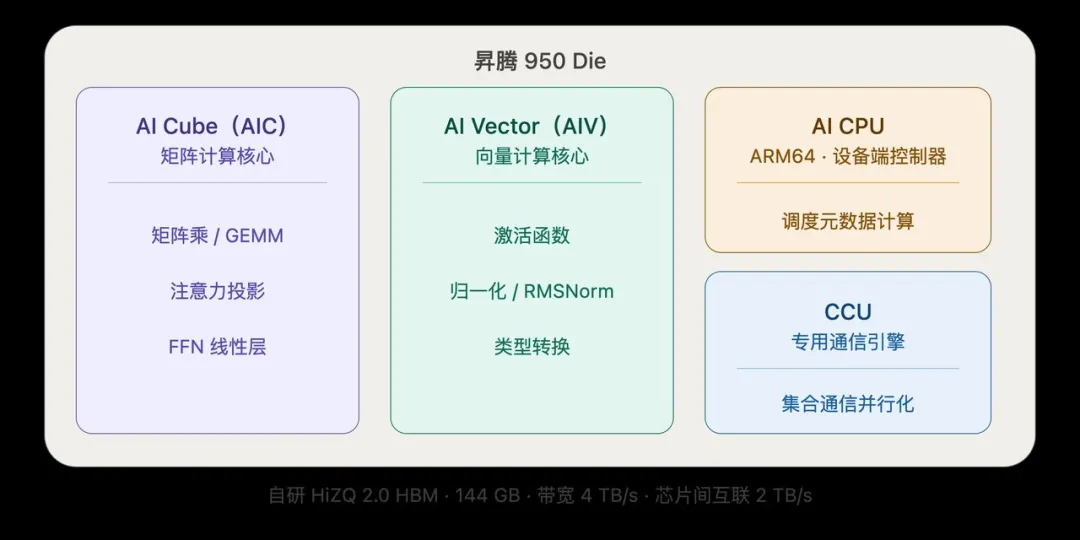
第一类是 AI Cube,也就是 AIC。
它负责大模型里最重的矩阵和张量计算,包括矩阵乘 GEMM、注意力投影 attention projection、FFN 线性层等。相当于英伟达架构里的 Tensor Core,或 谷歌 TPU 里的 MXU。
第二类是 AI Vector,也就是 AIV。
它负责逐元素向量操作,比如激活函数、归一化 RMSNorm、类型转换,以及矩阵计算前后的后处理。
昇腾在这里做了一个关键设计选择:AIC 和 AIV 是分离的独立核心,各自可以加载自己的代码段,并支持双主并行模式 dual-master mode,不需要互相等待。
这种分离让矩阵计算和向量计算能真正并发,而不是排队。
第三类是 AI CPU。
它是一颗独立的、设备端 ARM64 核,直接挂在设备内存上,专门处理 SIMD/SIMT 核心不擅长的工作,比如分支密集的控制流、标量逻辑、动态 shape 处理,以及内核执行前需要根据实时数值计算的调度元数据。
这里最关键的是“设备侧”。
关键在"设备端"三个字:这类控制流如果交给主机 CPU 处理,就需要一次出芯片的往返传输,这也是延迟和流水线停顿的主要来源之一。AI CPU 则在芯片内部就地处理,省掉了这个往返。
第四类是 CCU,专用通信引擎。
它专门处理集合通信的引擎,与计算核心并行工作,不占用 AI Core 的计算资源。
它支持“远端读 + 规约 + 本地写”和“本地读 + 远端写”两种通信模式,让通信可以真正叠加在计算过程中,而不是等计算结束后再开始。
这对 MoE 模型尤其关键。
MoE 的专家可能分布在不同设备上。如果通信一直占用计算核心,或者造成大量 HBM 读写,MoE 省下来的计算成本就会被通信吃掉。
总结来看,AIC 主要负责矩阵计算 ,向量和后处理则交给 AIV,动态调度交给 AI CPU,CCU 负责跨设备通信。
950DT 的推理优化,不是靠某一个核心单点冲高,而是靠这四类单元最大程度的并行与重叠,以减少等待。
硬件架构只是底座,真正决定 DeepSeek V4 能不能高效跑起来的,其实是 CANN。
它的全称是 Compute Architecture for Neural Networks,是华为为昇腾打造的 AI 计算软件框架,对标 CUDA 的定位。2025 年 8 月,华为将 CANN 开源。
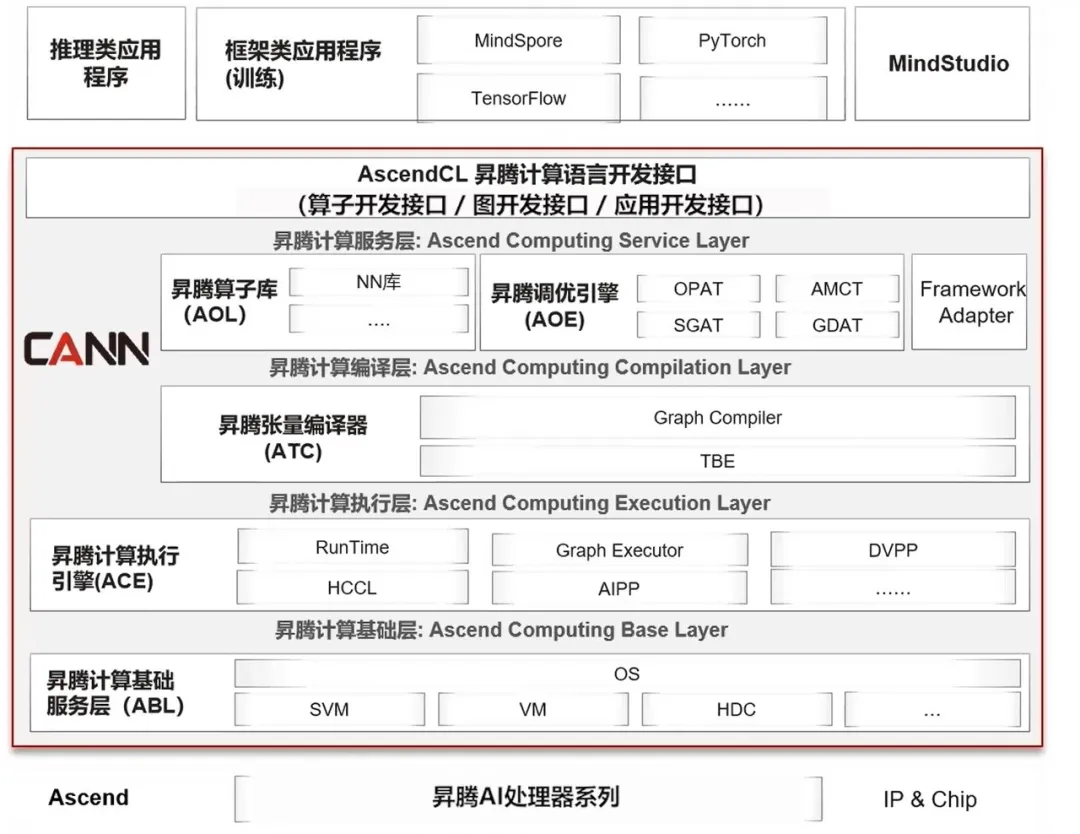
CANN 的策略非常清晰:每当中国头部大模型发布,全套打包交付,包括针对模型的 kernel、量化方案、分布式推理配方、serving 集成。
这和过去很多“国产芯片完成适配”的口径不是一回事。适配解决的是能跑,但完整推理路径解决的是能不能部署、复现、优化地跑。
比如,DeepSeek V4 对软件栈的要求尤其高。它不是一个普通稠密模型,而是包含长上下文、MoE、MTP、多种低精度格式,以及更复杂的 KV cache 压缩和稀疏注意力机制。只要其中某一环节,缺少适配都可能影响最终性能。
针对 DeepSeek V4,CANN 在模型发布当天,同步释放了完整的优化指南和 benchmark 数据,包括原生 MTP(多 token 预测)支持。
CANN 处理 MTP benchmark 的方式值得一提:一般的多 token 测试存在一个隐患,测试数据集上的 draft token 接受率往往高于真实用户场景,导致发布的性能数字,比实际部署后的体验更漂亮。
华为的做法是把完整 decode step 的耗时(到最后一个 MTP 模块结束)作为计量单位,公布"每 step 耗时",让用户自己乘以实际接受率换算。
这是一种更保守,也更工程化的 benchmark 方法。
SemiAnalysis 对 950DT 运行 DeepSeek Flash V4 的推理过程做了完整的 trace 分析,配置是 16-rank DP/EP 部署(16 路分布式专家并行)。
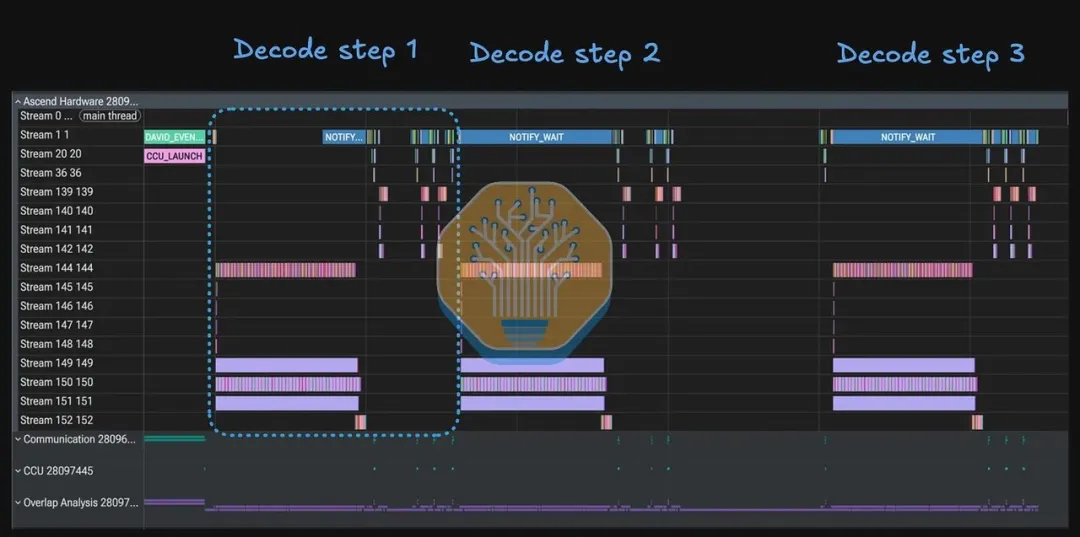
DP 是数据并行,EP 是专家并行。16-rank 意味着这不是单卡 demo,而是在多 rank 参与的分布式 MoE 推理环境中观察真实执行链路。trace 里能看到 16 路并行设备参与集体通信,MoE 专家分发与结果合并通信也在持续发生。
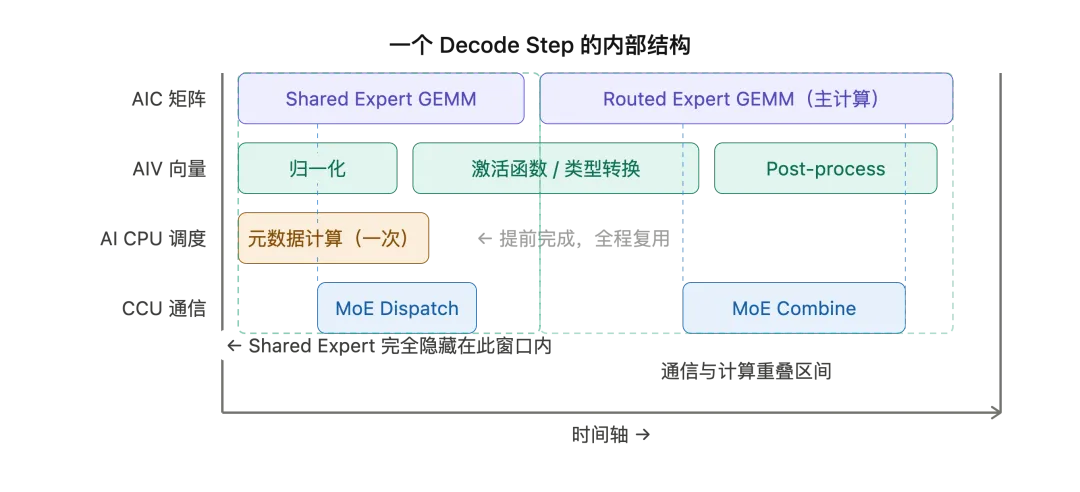
分析的核心是把一个 decode step 拆开来看。一个 decode step 不是一条串行的计算链,它在内部被拆分成多个 stream 流,在不同计算资源上尽量并发运行。
从 trace 看,CANN 至少做了三层重叠。
多卡 MoE 推理里,每层网络完成后都有一次 dispatch(把 token 分发给各专家卡)和 combine(把专家输出汇聚回来)的集合通信操作。
传统做法:算完等通信,通信完再算,等待时间是纯粹的浪费。
CANN 把 AIC、AIV、CCU 分配到独立的 stream 上同时运行。从 trace 里能看到:
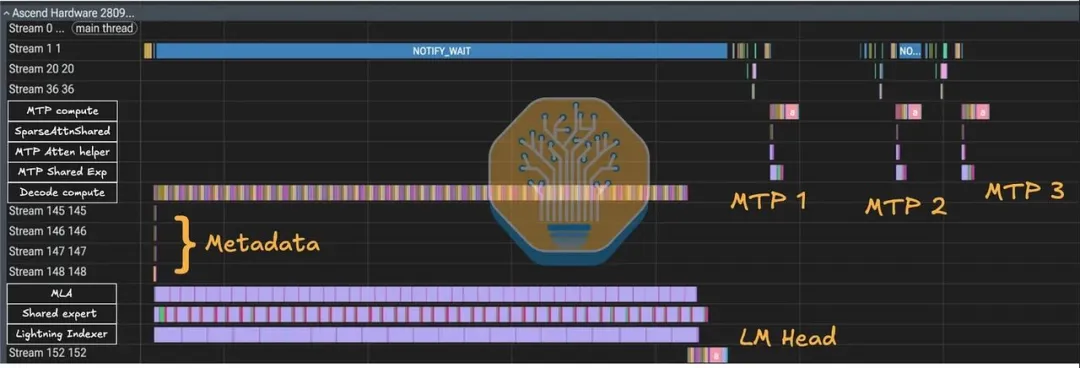
• C4A Compressor 的执行时间完全消失——被隐藏在其他计算的阴影里
• 共享专家(shared expert)的计算隐藏在路由专家(routed expert)执行之下,且不影响路由专家本身的性能
• Prolog、Compressor、LightningIndexer 三个操作相互重叠运行
这意味着 CANN 在指令调度层面做了精细的资源分配:计算和通信在时间轴上几乎完全叠加,相互填满了对方的空隙。
Decode step 开始前,有一类特殊的准备工作:根据当前序列长度、attention mask、分页 KV cache 的实时状态,计算出调度元数据:告诉每个计算核心,它负责哪个 batch、哪个 head、哪个 Q-block/K-block 的任务。
这类操作依赖运行时的实际数值,是分支密集的"控制类"任务,不适合放在矩阵核或向量核上跑。
传统解法:主机 CPU 处理,然后通过 PCIe 传回芯片。每一层都要这样做一次,加在一起就是不小的延迟。
CANN 的做法:把这个工作下沉到片上的 AI CPU,在设备内部就地完成。
从 trace 里看,Streams 145-148 对应这些元数据计算流——它们在 decode pass 开始时触发一次,预计算出可被后续内核复用的调度分区信息,耗时极短,且完全与 AI Core 的计算重叠。
SparseAttnSharedkv 和 QuantLightningIndexer 消费这些元数据,决定各计算核心的工作分配。
SemiAnalysis 指出,这个设计和 开源框架 FlashInfer 在主机侧为分页注意力做 planning 的思路一致,区别在于华为把 planning 下沉到了设备侧,省掉了出芯片往返的代价。在长上下文场景下,这个优化的收益更明显,因为需要 resolve 的序列分区信息更多。
另一个值得注意的细节是 Stream 152:它包含 LM head、最后一层,以及倒数第二层的 o_proj 和 MoE。这是 npugraph_ex(华为的图编译器)的决策——让主图在 Stream 144 就标记为"完成",而尾部操作在 Stream 152 继续异步执行。效果是解锁了更长的计算重叠窗口。
华为在 CANN 8.5,2024 年引入了 MC²(Merged Compute-Communication,通算融合)机制。
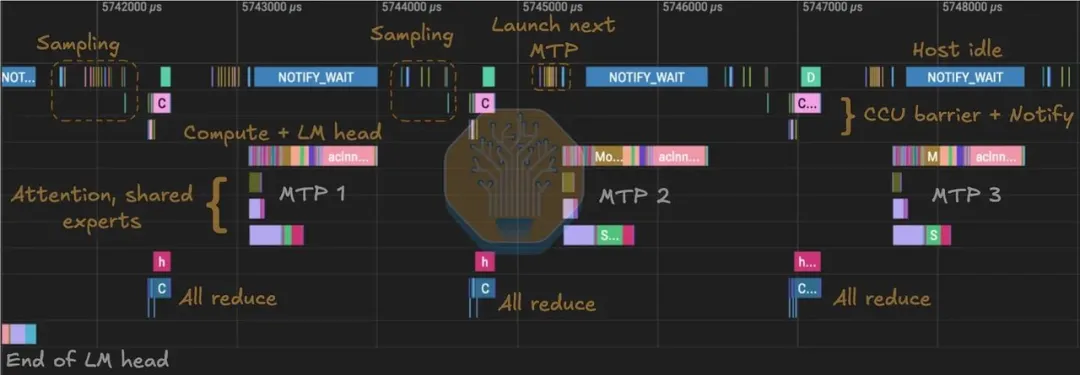
这不是普通 kernel,也不是 HCCL 集合通信,而是把通信原语和计算操作合并进同一个算子里。在 DeepSeek V4 的 decode 路径中,SemiAnalysis 观察到了两个 MC² 专家并行算子:
• MoeDistributeDispatchV2
• MoeDistributeCombineV2
MoE 架构里,dispatch 和 combine 是每层都必须发生的通信操作,是多卡推理最主要的通信开销来源之一。
MC² 把这个开销折叠进了计算流程里——从外部可见的角度,集合通信(Collective Communication)与 矩阵乘法计算(Matmul)变成了同一件事。
SemiAnalysis 在报告里做了一个对比:
去年 DeepSeek V3/R1 发布时,全球只有一个软件栈在 Day 0 完整支持推理:英伟达的 CUDA。
DeepSeek V4 发布时,实现 Day 0 完整支持的变成了两个:CUDA,和华为的 CANN。
AMD 的 ROCm 在 Day 0 几乎完全失效,推理吞吐低至每秒 1-2 个 token,完全不具备部署条件。
值得一提的是,英伟达自家的 TRT-LLM 在 Day 0 也存在一个显性 bug,隐藏状态被静默损坏,SemiAnalysis 自己提交 PR 才修复,整个过程花了 9 天以上。
所以说,Day 0 真正开箱即用的,是英伟达生态里的开源引擎 SGLang 和 vLLM,以及华为的 CANN。
而值得一提的是,其他主流国产 AI 芯片所谓的 Day0 支持主要是基于“类 CUDA”生态的软件栈。 某种程度而言,还是缺乏自主的软件生态。
这是代际变化,不是渐进追赶。而且这次变化的起点,是 DeepSeek V4 从架构设计阶段就和华为昇腾做了协同:新的注意力机制(HCA/CSA)、MoE 的量化方案、专家并行的通信设计,都考虑了昇腾硬件的执行路径。
CANN 证明了从第一天起就能交付完整的工程实现,不是“能跑”,是“优化好地跑”。这和其他国产芯片“宣称支持”的含义,不在同一个层面。
在《圣经》的隐喻里,巨人 Goliath 最终倒下了。但那个故事里的 Goliath 更多地被动地站在原地,被石头击中。而现实世界里,英伟达是一个一年一代新架构、持续在移动的目标。
Day 0 的表现证明了华为的工程执行力,但如今 DeepSeek V4 已经发布 40 多天,英伟达 GPU 的推理性能 与 950DT 拉开了多大距离? 是已经追上了,还是在某些场景已经反超?
后续,SemiAnalysis 将用同一套基准测试跑完英伟达 H 系列、B 系列、AMD MI 系列,以及昇腾 950 的完整性能曲线和吞吐对比数据。我们会持续跟进。
参考链接:
https://newsletter.semianalysis.com/p/deepseekv4-16t-day-0-to-day-43-performance
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。