谷歌表示,Gemma 4 12B 旨在“将具有自主性的多模态智能直接带入到你的笔记本电脑”,并进一步指出,该新模型可以与 Google AI Edge 结合使用,从而“在日常设备上进行本地构建和实验”。这种集成提供了广泛的功能,从自主数据处理到生成可视化洞察,甚至包括构建网页或执行工具。
在架构上,Gemma 4 12B 采用了一种创新的统一式多模态无编码器架构,通过将多模态数据直接输入到大型语言模型(LLM)中,省去了独立的多阶段视觉和音频编码器。这种设计解决了传统多模态模型中一个长期存在的效率问题——将独立的视频和音频编码器作为预处理步骤导致延迟增加和内存占用碎片化。
为了解决这些问题,Gemma 4 12B 采用了一个仅包含解码器的 Transformer ,它具有与 Gemma 4 31B Dense 模型相同的先进解码器结构。
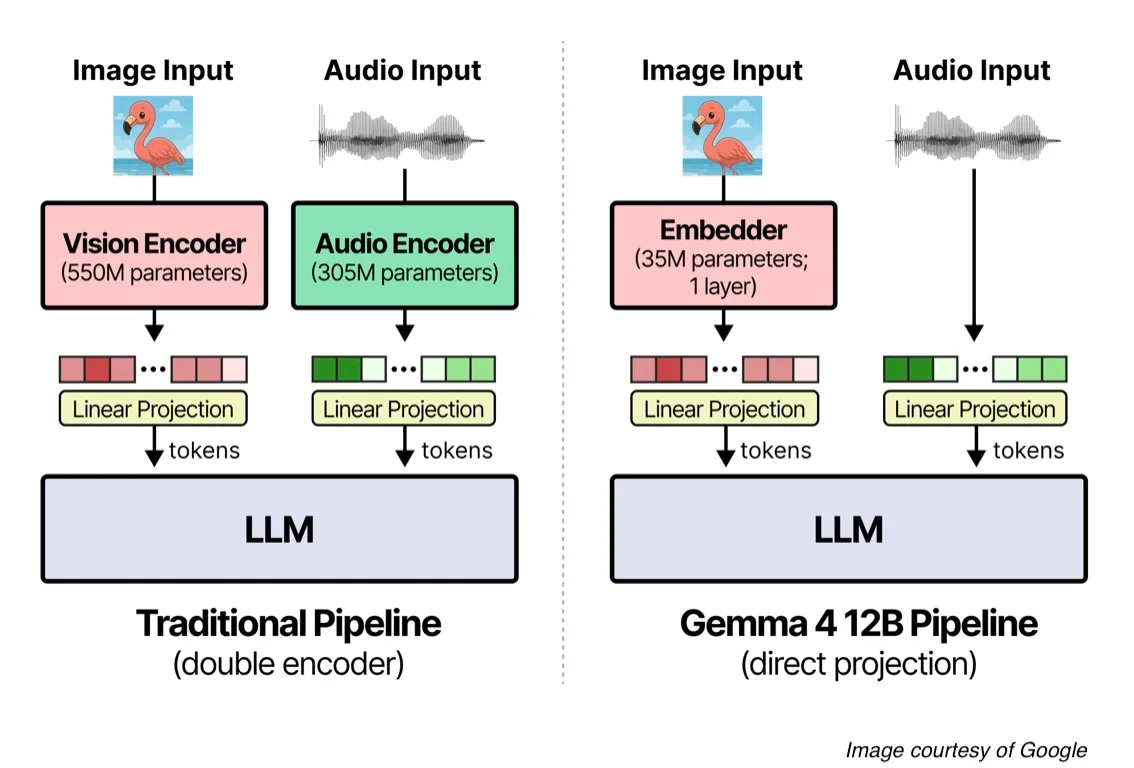
这个拥有 3500 万参数的视觉嵌入器取代了其他中型 Gemma 4 模型中使用的 27 层视觉 Transformer 。它通过单次矩阵乘法将原始的 48×48 像素直接投影到大语言模型(LLM)的隐空间中,同时在输入阶段利用因子化的 X–Y 坐标查找机制注入空间位置信息。
音频波形投影消除了对独立音频编码器的需求。取而代之,它直接将 16 kHz 的音频切分为 40 毫秒的帧(640 个采样点),并将其线性投影到大型语言模型(LLM)的输入空间中。
此外,对多模态输入使用相同的权重,简化微调过程,使适配器(如 LoRA)或全模型微调能够在单次迭代中更新整个多模态循环。
可以通过 Google AI Edge Gallery 展示应用、Google AI Edge Eloquent 设备端语音输入应用以及 LiteRT-LM 访问 Gemma 4 12B。
借助 Google AI Edge Gallery 应用,开发者可以“即时生成并执行脚本”,将自然语言指令转化为可运行的代码。例如,在谷歌的演示中,该模型能够创建一个 Python 程序,用于渲染一张 PNG 图表,对比 2024 年和 2025 年出生的前 10 名女婴的名字。
最后需要说明的是,借助 LiteRT-LM(通过 litert-lm serve 启动兼容 OpenAI 的服务器) 或 llama.cpp,Genmma 4 12B 可以与现有的 AI 框架(如 OpenCode)搭配使用。该模型可以从 Hugging Face、Ollama、LM Studio、Google Cloud 及其他平台上获取。
在 Reddit 上,LoveMind_AI 写道:“这可能是我很久以来听说过的最令人兴奋的模型之一。这种无编码器模型……简直酷毙了。120 亿参数的模型能原生处理音频,这非常令人振奋”。同样,Wrong_Mushroom 解释道,无编码器的优势在于,“它让你不需要额外的文件即可分享图像和音频。这同时也意味着,该模型的数据集在训练时已经将这些因素考虑在内,因此理论上它的准确性会更高”。
关于该模型的编程能力,虽然部分评论者对其有效性表示怀疑,但也有用户写道,他曾用它“构建了一个包含服务器端和客户端的 Python 应用。它的表现让我惊叹不已。上下文理解能力非常出色(是积极意义上的)。它能一次性完成大量任务,而且几乎不会出错”。此外,triynizzles 指出,“它在简单任务表上现尚可,但无法取代 QWEN 3.6”,并解释称,虽然他成功利用该模型解释了特定代码路径或修复了逻辑错误,但“一旦遇到更模糊的情况,它就会开始失效”。
如果想要深入了解该模型及其架构,请务必阅读 Maarten Grootendorst 的分析文章。
原文链接:https://www.infoq.com/news/2026/06/google-gemma4-12b-local-coding/
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。