ClickHouse 是一款开源的列式数据库管理系统,专为对海量数据集进行实时分析查询而设计。它擅长在数毫秒内聚合数十亿行数据,使其成为分析平台、可观测性系统、实时仪表盘和数据仓库的流行选择。ClickHouse 通过其列式存储格式、高效压缩和向量化查询执行来实现这一目标,但要获得最佳性能,需要理解如何与其架构协同工作。
尽管 ClickHouse 具备卓越的开箱即用性能,但设计不佳的 Schema、低效的查询或次优的配置都可能浪费大量的性能潜力。一个原本能在数毫秒内返回结果的表,可能需要数秒。能实现 50 倍压缩的存储,可能最终只能达到 10 倍。这种性能差距往往源于未能理解 ClickHouse 如何存储、压缩和查询数据,并应用正确的技术来使您的用例与其优势相匹配。
无论您是每天插入数十亿事件、运行复杂的分析查询,还是努力降低存储成本,正确的优化都能显著提升性能和效率。对数据类型、表引擎或排序键的微小调整,都可能带来数量级的改进。
在本文中,我将分享 10 项最佳实践,这些是我作为 ClickHouse 解决方案架构师,在日常与客户紧密合作中发现能够带来最大影响的。它们并非纸上谈兵的理论建议,而是我在各种规模的部署中反复运用并取得成效的模式,涵盖了从 Schema 设计、数据建模到查询优化和监控等多个主题。
将 ClickHouse 与 AI 代理一同使用? 如果您正通过 AI 代理或大型语言模型 (LLM) 应用程序查询 ClickHouse,请查阅 ClickHouse best practices for AI agents,获取针对该用例的专属指南(https://clickhouse.com/blog/introducing-clickhouse-agent-skills)。
在 ClickHouse 中,表定义中的 ORDER BY 子句是您做出的最关键决策之一。它决定了数据在存储中的物理排序方式,这直接影响查询通过主索引剪枝 (primary index pruning) 跳过无关数据的效率。同时,它还会影响压缩效率,因为排序后的数据中相邻行通常共享相似值,从而能实现更高的压缩比。
ClickHouse 写入数据时,会根据您指定的 ORDER BY 列对行进行排序,并在内存中存储每个数据颗粒(granule,默认为 8,192 行)的首个值。在查询时,对这些列应用的过滤器可让 ClickHouse 跳过那些无法包含匹配数据的整个数据颗粒。
关键在于使您的 ORDER BY 顺序与最常见的查询模式保持一致。优先放置像 tenant_id、region 或 category 这样的低基数(low-cardinality)列,随后是基于时间的列。应避免以 UUIDs 或 timestamp 等高基数(high-cardinality)字段开头,因为它们几乎无法提供裁剪优化效果。
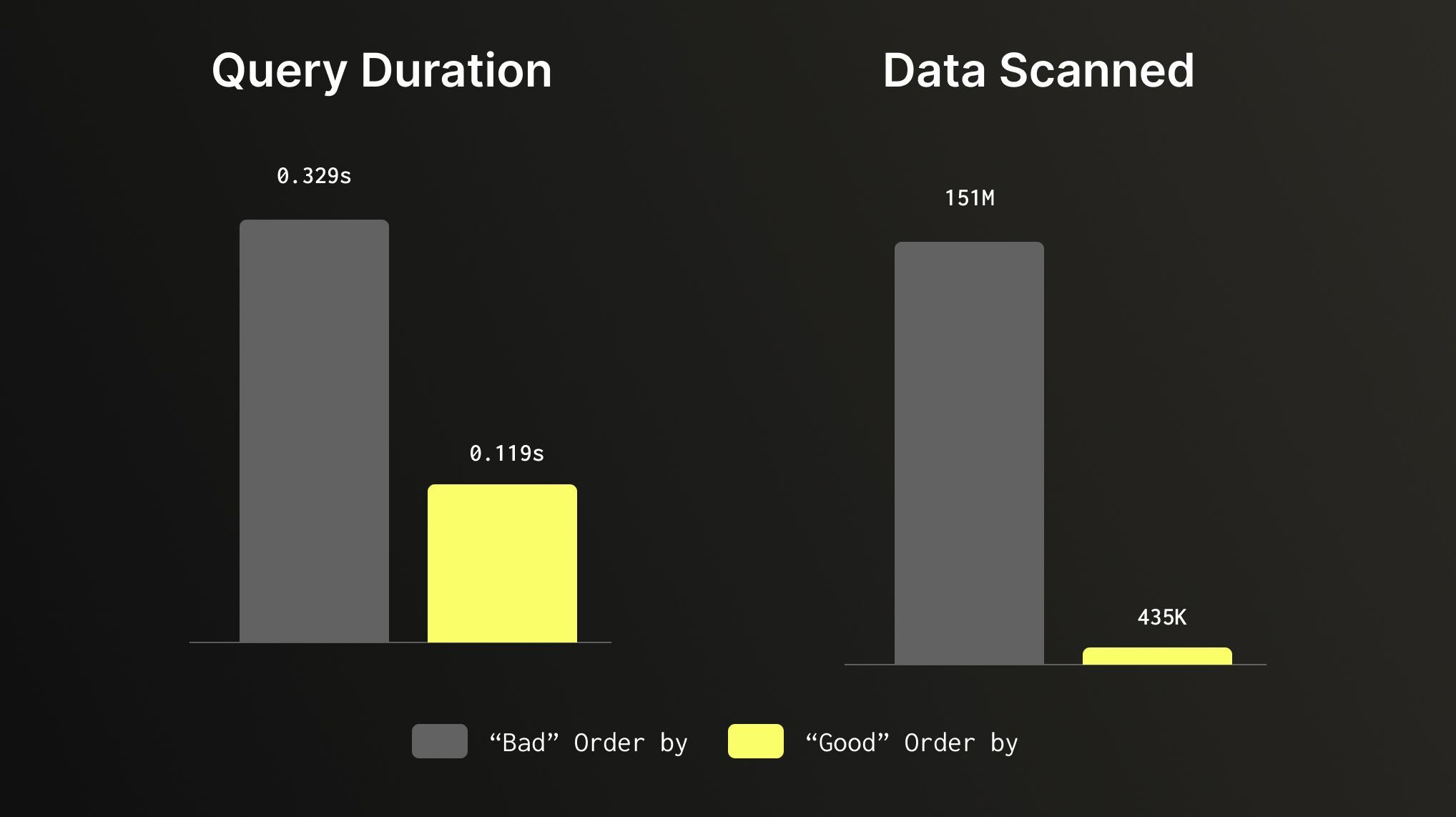
让我们以包含逾 1.5 亿行数据的 Amazon reviews dataset 为例。假设一个表默认按 (marketplace, customer_id, review_date) 排序,执行以下查询:
SELECT product_category, toStartOfMonth(review_date) AS month, count() AS review_count, avg(star_rating) AS avg_ratingFROM amazon_reviewsWHERE product_category = 'Electronics' AND toYear(review_date) = 1999GROUP BY product_category, monthORDER BY month;复制代码
它会执行一次全表扫描,遍历全部 1.5 亿行数据以查找极小部分数据。如果我们更改表的 ORDER BY 顺序为 (product_category, review_date),我们的查询将基于这些列进行过滤,从而使相同的查询运行速度 提升 3 倍,同时所需扫描的数据量 减少 347 倍。对于相同的查询和数据集,如果 ORDER BY 顺序与查询模式匹配,便能带来显著的不同。
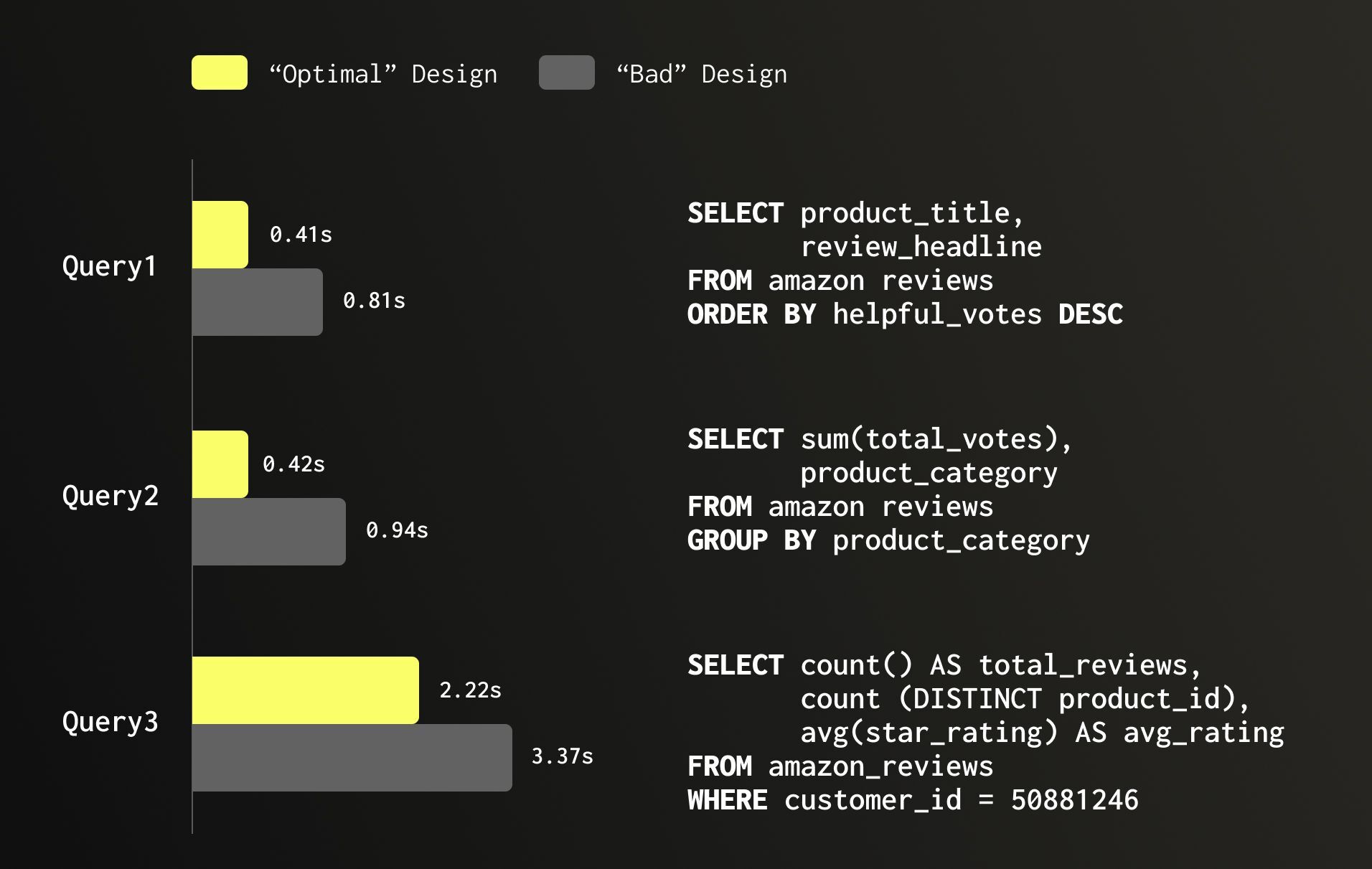
ClickHouse 中的数据类型不仅仅关乎正确性,它们直接影响存储大小、压缩比和查询速度。选择适合数据的最小类型,除非 NULL 值确实具有实际意义否则避免使用 Nullable (可为空) 类型,对于低基数文本列使用 LowCardinality(String) (低基数字符串) 类型,以及对于固定值集合优先选择 Enum (枚举) 类型而非自由文本字符串,可以显著提升性能和存储效率。同样的逻辑也适用于整数类型,当数据范围允许时,使用 UInt8 或 UInt32 代替 UInt64 意味着每次查询需要读取、解压缩和处理的数据量更少。 被标记为 Nullable (可为空) 的列要求 ClickHouse 额外存储一个 UInt8 列来追踪 NULL 值,这会增加存储和查询执行的双重开销。因此,除非 NULL 值确实具有实际意义,否则最好避免使用 Nullable 类型。在大多数情况下,一个合理的默认值可以作为有效的替代方案:文本字段使用空字符串、数值计数使用 0、或者对于 0 是有效条目的 ID 字段使用像 -1 这样的哨兵值。对于值集有限的字符串列,LowCardinality(String) (低基数字符串) 类型在底层使用字典编码,这使得它在列中不同值少于约 10,000 个时效率更高。
让我们继续以拥有 1.5 亿行数据的 Amazon 评论数据集为例。一个设计不佳的表,其中许多列是 Nullable (可为空) 类型、数值字段过大、低基数文本列使用普通 String 类型,会占用 30.16 GB 存储空间。通过优化,即通过删除 Nullable (可为空) 类型、调整数值列大小、并在适当位置应用 LowCardinality(String) (低基数字符串) 类型,将其切换到更合适的数据类型后,存储空间可降至 26.8 GB。但其价值不仅仅体现在存储方面,它对性能也有显著提升,如下例所示,查询速度提高了 2 倍。
ClickHouse 中的分区 (partitioning) 是最容易被误解的特性之一,最常见的错误是将其用作性能优化手段。ClickHouse 中的分区主要是一种数据管理特性,而非通用的性能加速器。ClickHouse 通过主索引剪枝 (primary index pruning) 在数据跳过方面已经极其快速。在此基础上再进行分区,很少有帮助,反而常常适得其反。原因是 ClickHouse 需要大的数据块 (parts)(通常高达 150GB,常含数十亿行数据)才能高效地进行压缩和查询,并且数据块 (parts) 永远不会跨分区边界合并。过度分区,例如按天或按高基数 (high-cardinality) 列(如 tenant_id)进行,常常导致大量小数据块 (parts)、合并速度变慢、内存占用增加以及查询性能下降。一个好的经验法则:如果您创建了超过几十个分区,您很可能正在过度分区。
那么何时应该进行分区呢?在两种情况下,对数据进行分区是很有价值的。第一种情况是基于 Time-to-Live (TTL) 的数据过期:按月或按年分区可以高效地删除整个旧数据分区,而无需触发变异 (mutation) 或合并 (merge) 操作,这对于大型数据集来说比行级 TTL 效率高得多。第二种情况是与 ReplacingMergeTree、CollapsingMergeTree 或 AggregatingMergeTree 等合并型表引擎 (merge-oriented table engines) 配合使用时,通过为历史分区保留一个数据块 (part),我们可以在带有 FINAL 修饰符的查询中获得显著的性能提升。
除了这两种情况,在添加 PARTITION BY (分区子句) 之前请务必谨慎考虑。默认的不分区,或者简单的按月或按年分区,通常是正确的选择。
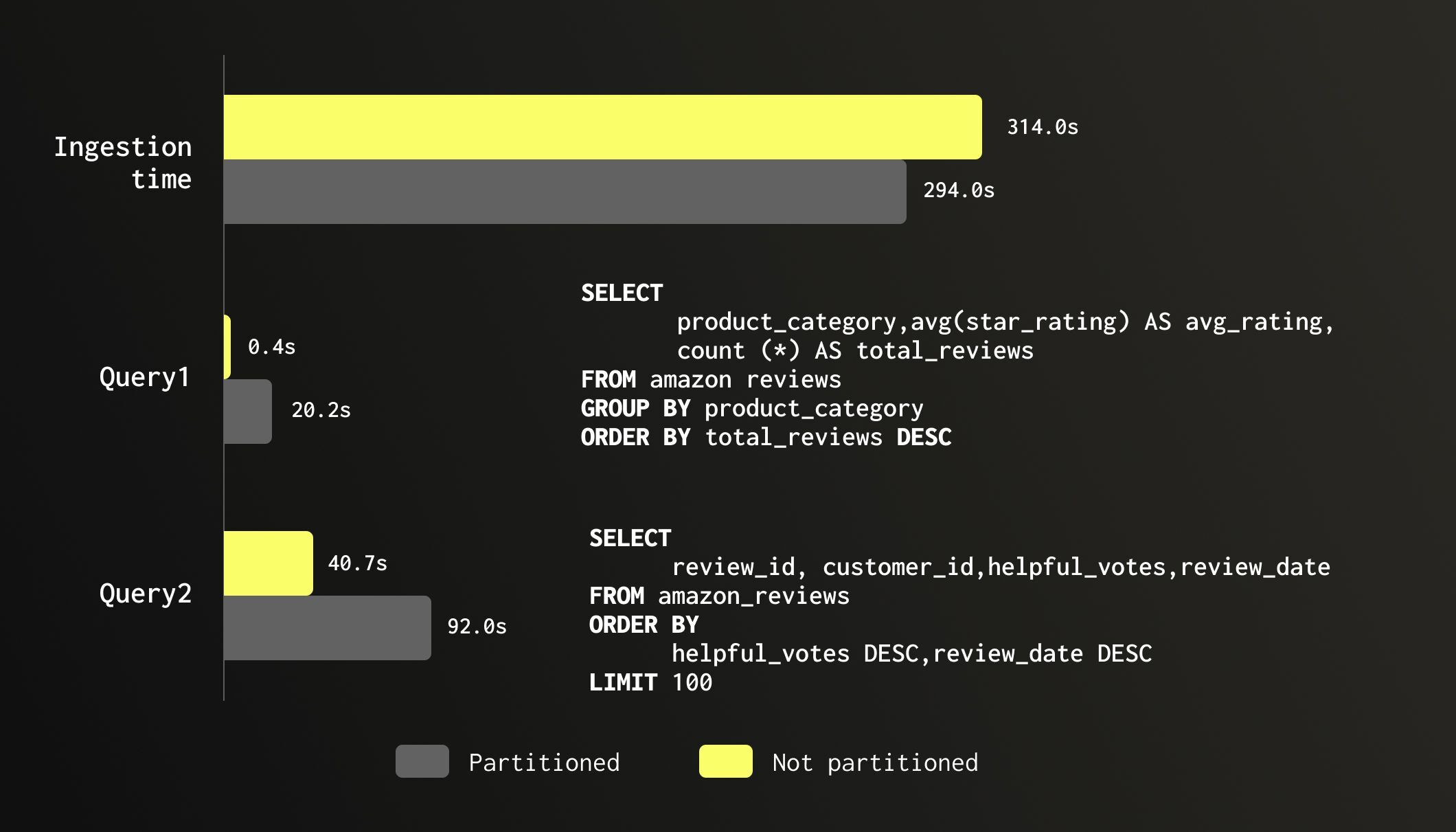
为了说明不必要分区的成本,我们在两个结构相同的表上,使用了包含 1.5 亿行 Amazon 评论的同一份数据集进行测试。其中一个表按 review_date 的月份进行分区,另一个则未分区。数据摄入时间大致相同(294 秒 对 314 秒),但分区表在加载过程中消耗了多达 55% 的内存(4.71 GB 对 3.03 GB)。真正的性能损耗体现在查询阶段。一个针对所有 product_category 值进行简单聚合的查询,在未分区表上仅需 0.4 秒,而在分区表上则耗时 20 秒。尽管扫描了完全相同的行数,但性能下降了 46 倍。一个按 helpful_votes 进行 Top-100 排序的查询也展现了类似但程度稍轻的性能差异:未分区表耗时 40 秒,分区表则耗时 92 秒。同样的数据,同样的查询,速度却慢了一倍以上。由于这两个查询均未对review_date 进行过滤,分区并未带来任何剪枝 (pruning) 优化。相反,数据碎片化反而增加了每次扫描时的合并与调度开销。
ClickHouse 的主索引是基于 ORDER BY 字段构建的稀疏索引,是实现快速数据访问最强大的工具。但在实际应用中,查询并非总能通过主键列进行过滤。在这种情况下,跳过索引 (Skipping Indexes) 能够将相同的数据粒度剪枝 (granule-pruning) 能力扩展到数据模型中的任意其他列。跳过索引是与数据一同存储的辅助索引,它不会改变数据的物理存储和排序方式。
跳过索引有多种类型,我们可以将它们大致分为两类:轻量级索引 (Lightweight Indexes) 和重量级索引 (Heavyweight Indexes)。轻量级索引对写入性能和存储的影响微乎其微,因此可以在任何有助于提升查询效率的地方自由添加。而重量级索引则会带来更高的存储开销和写入放大 (write amplification) 成本。因此,只有当查询加速效果显著且足以抵消这些额外开销时,才值得考虑使用。
minmax - 针对每个数据粒度 (granule) 存储其最小值和最大值。最适用于数值或日期列,对字符串列也可能有所帮助。其构建与维护成本极低,存储开销几乎可以忽略不计;
set - 针对每个数据粒度存储一小组独特的(distinct)值。最适合经常用于过滤条件但未包含在 ORDER BY 子句中的低基数 (low-cardinality) 列。可以通过 set(0) 来存储所有唯一值,或者使用 set(N) 来设定上限,当超出此上限时,查询将回退到全表扫描。
bloom_filter - 一种概率型数据结构,用于判断“某个值是否确定不在当前数据块中”。最适用于高基数字符串列,例如 ID 或 URL。它允许存在误报,但绝无漏报。由于会带来显著的存储和写入开销,因此仅当其带来的扫描优化能够抵消其成本时才应使用;
ngrambf_v1 / tokenbf_v1 - 是 bloom_filter 的变体,专门针对自由文本列上的 LIKE 或 hasToken 查询进行了优化。虽然在子字符串和词元(token)搜索方面表现强大,但其构建和存储成本较高,因此仅应在经常进行搜索的列上使用;
Text - 一种全新的(自 26.2 版本起正式发布,即 GA)文本搜索专用倒排索引,其功能类似于 Lucene/Elasticsearch 等系统中的倒排索引。它支持高精度的精确词条(term)、前缀和子字符串匹配。它是文本搜索场景中最强大的选择,但同时在存储和写入放大方面也是开销最大的。当 Bloom_filter 无法满足您的性能需求时,可选用 Text索引。
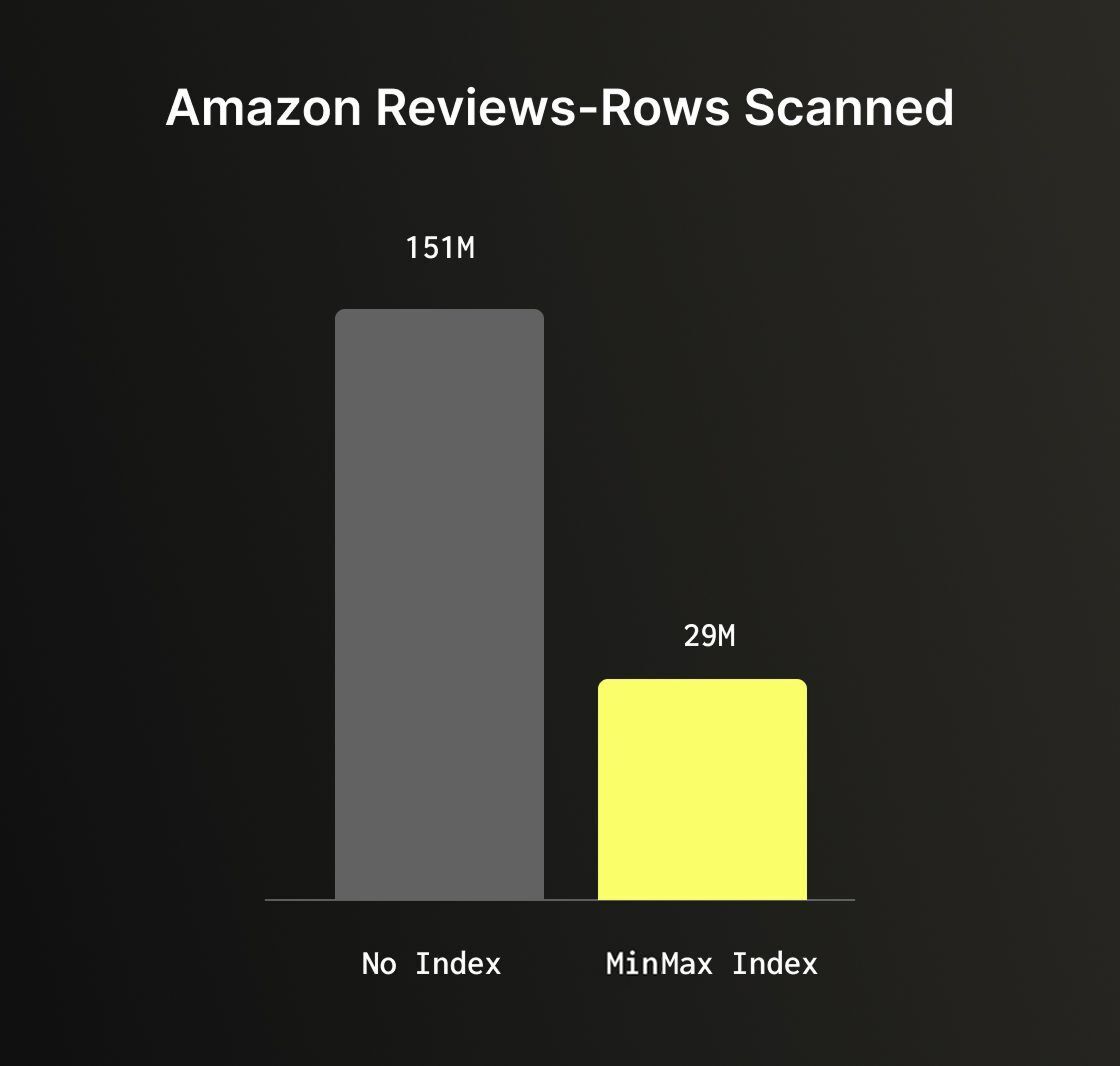
通过 Amazon 评论数据集可以很好地说明跳过索引(skipping index)的优势。当执行一个 total_votes > 1000 的过滤查询时,如果没有跳过索引,系统将对全部 1.5 亿行数据执行全表扫描。若在 total_votes 列上添加一个 minmax 索引(这是开销最低的索引之一),扫描的行数将降至 2900 万行,实现高达 80% 的数据扫描量减少,且几乎不带来额外开销。
ClickHouse 的原生 JSON 数据类型是处理半结构化数据的强大工具,特别适用于那些键值不可预测、随时间变化或包含多种类型值的场景。它能够在插入数据时自动推断类型,并将每个被发现的路径存储为独立的子列(受限于 max_dynamic_paths 的定义),从而为动态数据提供列式存储的性能优势。
然而,这种灵活性并非没有代价。JSON 类型在每次数据插入时都会执行类型推断,这相比静态 Schema 会带来额外的开销。此外,当同一路径下包含多种类型的值时,它还会占用更多的存储空间。对于结构已知且一致的数据,即使数据以 JSON 格式传输,采用带有显式列类型的静态 Schema 也将始终比 JSON 类型表现出更优的性能。
在使用 JSON (JavaScript Object Notation) 数据时,一个关键参数是 max_dynamic_paths,它控制 ClickHouse 将多少个不同的 JSON 路径作为单独的子列进行存储。默认情况下,一旦超出此限制,其他路径将被存储在一个共享结构中,这会降低查询效率。默认值为 1024,但对于路径集有限且结构明确的有效载荷,将其设置得更低,可以使数据结构更紧凑、更可预测。当您知道某些路径始终存在且类型固定时,可以使用 JSON 提示 (hints) 明确声明这些路径。例如:
CREATE TABLE events ( id UInt64, payload JSON(\`timestamp\` DateTime, \`level\` LowCardinality(String))) ENGINE = MergeTree ORDER BY id;复制代码
提示 (Hints) 为 ClickHouse 提供了有关这些路径的更多信息,这些路径像常规列一样被存储和压缩,而有效载荷的其余部分则保持完全动态。在将 Amazon Reviews 数据集转换为文档型数据集时,相比不使用提示的 JSON,使用提示可将存储空间减少 38%;同时,此示例查询的速度在使用提示时比不使用提示时提高了 26%。
SELECT count(*), review_data.product_category PCFROM amazon_reviews_jsonGROUP BY pc复制代码
然而,这不仅是为了优化存储和提升性能,提示路径也是跳过索引 (skipping indexes) 的可靠目标,而完全动态的路径在不同数据粒度 (granules) 之间可能存在不一致,从而导致索引效率较低。需要指出的是,虽然可以在任何 JSON 路径上添加跳过索引,但这需要进行类型转换 (casting)。
总而言之:如果数据结构扁平且可预测,应使用显式列 (explicit columns)。如果数据存在可预测的核心结构,但伴随动态变化,则考虑对已知部分使用静态列 (static columns),其余部分使用单个 JSON 列。只有当数据模式完全不可预测时,才应考虑使用完全动态的 JSON 列。
如何高效地将数据插入 ClickHouse 是一个值得深入探讨的重要议题。数据摄取 (ingestion) 模式通常有四种,每种模式都有其推荐的方法和最佳实践。
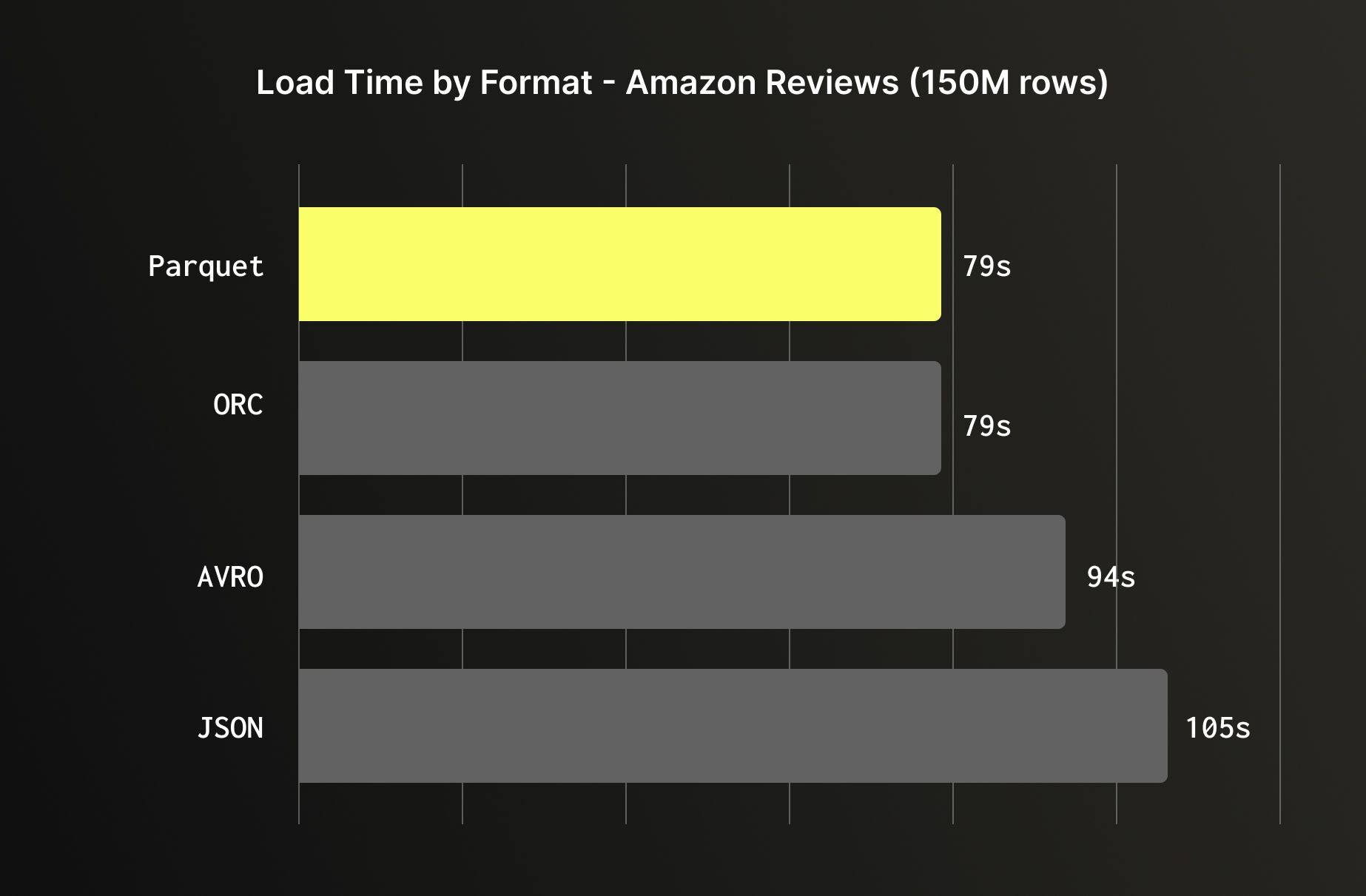
对象存储 (Object Storage)(如 Amazon S3、GCS、Azure Blob)是批量加载最常见的数据源之一。在有格式选择时,建议优先选择 Parquet 或 ORC 等列式格式,而不是 JSON 或 Avro 等行式格式;ClickHouse 可以仅从 Parquet 和 ORC 格式中读取所需列,完全跳过其余部分,而 JSON 则需要解析每一行的每个字段。即使在加载所有列时,列式格式也更快,因为数据到达时已按照 ClickHouse 内部存储的方式组织,从而减少了摄取过程中的转换开销。加载 Amazon reviews 数据集清楚地说明了这一点:Parquet 和 ORC 格式加载耗时 79 秒,Avro 格式耗时 94 秒,JSON 格式耗时 105 秒。
对于从对象存储进行托管式持续数据摄取,ClickPipes 直接支持 S3 和 GCS 数据源。
数据库的 CDC (Change Data Capture)(如 Postgres、MySQL、MongoDB 等)和 事件流(如 Kafka、Kinesis 等)最好通过 ClickHouse Cloud 的原生托管式摄取服务 ClickPipes 来处理。ClickPipes 开箱即用地支持模式映射、偏移量管理、错误处理和背压。针对 CDC,它采用基于日志的方法,以最小的源数据库负载捕获每一行级别的变更。如果您的数据库位于私有 VPC (Virtual Private Cloud) 中,ClickPipes 支持反向 PrivateLink,从而实现安全连接,而无需将数据库暴露给公共互联网。
后端应用程序 直接写入 ClickHouse 是企业非常普遍的做法,但这确实需要考虑一些事项。ClickHouse 针对大型、不频繁的批次进行了优化,而非应用程序代码中常见的小型、频繁的插入。每次插入都会在存储层中创建至少一个部分 (part),而过多的小部分会导致合并压力 (merge pressure)、内存使用量升高,并最终导致插入限流 (insert throttling)。两种解决方案是:客户端批量处理(累积行并在每隔几秒或几千行时刷新),或者启用 异步插入 (async inserts),这让 ClickHouse 自动缓冲传入的插入并以批次形式刷新它们:
SET async_insert = 1;SET wait_for_async_insert = 1;复制代码
当 wait_for_async_insert = 1 时,客户端会等待数据写入分片(part)的确认,这为您提供了小批量写入的便利,并具备适当的确认机制和可靠的错误处理能力。您可以通过 system.asynchronous_insert_log 监控异步插入行为,从而针对您的工作负载调整刷新间隔和缓冲区大小。
无论采用何种数据导入方式:请避免一次只插入一行数据;在可能的情况下,优先选择原生二进制格式而非 JSON;并通过监控 system.parts 中的分片(part)数量,尽早发现数据导入问题。
物化视图和投影都遵循相同的核心思想:在数据插入时执行计算,从而使读取操作更快,并减少计算资源消耗。与在查询时进行扫描和聚合不同,您可以选择在数据到达时预先计算并存储结果。两者的权衡取舍是一致的:更快的读取是以增加存储空间和额外的写入开销为代价的。
投影是存储在同一表内部的替代排序方式或预聚合数据。当 ClickHouse 执行查询时,如果查询的过滤和排序模式与某个投影匹配,它会自动选择最佳投影,因此无需对查询进行任何修改。这使得它们对应用程序透明,易于采用。缺点在于,每次插入操作都必须为每个投影写入和排序数据,这会增加插入延迟和存储占用。在围绕投影制定查询优化策略之前,有必要验证它们是否真正在查询时被选中。最简单的方法是启用以下设置:
SET force_optimize_projection = 1;复制代码
启用此设置后,如果您的查询没有找到合适的投影,ClickHouse 将抛出错误,从而立即明确您的投影是正在被使用,抑或是被默默忽略。
关于投影,需要强调的一点是,它们常常被“以防万一”地添加,这会影响存储和写入成本。首先,应该使用设计良好的主键,并识别出实际运行缓慢的查询,然后只在真正需要的地方添加投影。让实际使用数据来指导投影的定义。
物化视图 (Materialized views) 有两种类型。
可刷新物化视图 (Refreshable materialized views) 的工作方式与传统数据仓库中的预期一致,它们会按计划重新计算结果,因此适用于复杂的转换。但这种方式通常需要管理已处理数据的“书签”,以区分已处理和未处理的数据;在遇到延迟数据或历史数据回填时,需要进行重新处理;同时强烈建议在处理过程中考虑幂等性。
增量物化视图 (Incremental materialized views) 是 ClickHouse 的独特之处,它们更灵活,但也需要更精心设计。它们充当插入触发器,对每个传入批次运行 SELECT 查询并将结果写入目标表。这使得它们在数据到达时,能够极其高效地持续维护聚合、汇总或扇出数据管道。一个重要的限制是,它们仅在插入操作时触发:对源表的删除和更新操作不会传播,因此它们最适合仅追加或不可变的数据模式。
增量物化视图中的连接操作值得特别关注,因为只有连接中的左表会触发视图更新。如果右侧表发生变化,物化视图将不会更新。此外,物化视图的良好可组合性也值得了解:单个源表可以“扇出”到多个物化视图(MV),每个 MV 维护不同的聚合或转换;同时,来自不同源表的多个 MV 也可以汇聚到同一个目标表。这使得它们成为构建更复杂数据管道的强大基石。
在 ClickHouse 中,一种常见模式是利用物化视图来维护用于仪表盘和高频查询的预聚合汇总表,同时保留原始表以进行即席探索。
ClickHouse 的系统表是其最强大的内置功能之一。集群中发生的一切,包括查询、合并、后台活动和错误,都被捕获并可以通过标准 SQL 进行查询,从而使用标准 SQL 为你提供深入的可观测性。
在多副本服务中,查询系统表仅会显示当前查询所在副本的日志。若要获取所有副本的完整视图,需使用clusterAllReplicas。此外,由于许多系统表会轮转,历史数据可能不会直接显示,除非你显式地通过 merge 表函数对它们进行合并。以下是如何查询 system.query_log 以确保获取表中所有服务日志的示例:
SELECT event_time, query_id, query, typeFROM clusterAllReplicas('default', merge('system', '^query_log*'))WHERE event_time > Now() - toIntervalMinute(5);复制代码
system.query_log 和 system.parts 是两个最值得熟悉的系统表。
system.query_log 是理解查询行为的主要工具。每个查询会根据事件(QueryStart、QueryFinish、ExceptionBeforeStart 或 ExceptionWhileProcessing)生成一行记录,从而提供服务上所有查询的完整生命周期视图。每行数据会捕获查询耗时 (query_duration_ms)、资源使用情况 (read_rows、read_bytes、memory_usage)、查询文本本身,以及所涉及的数据库、表、列和投影。在错误排查时,还可以利用 exception_code、exception 和 stack_trace。ProfileEvents 列则提供了更深入的洞察,它是一个低级执行计数器的映射,能够精确揭示时间开销分布,从 CPU 周期到 I/O 读取再到缓存命中。当查询速度低于预期时,ProfileEvents 常常能帮助我们判断瓶颈是在 I/O、CPU 还是网络。
system.parts 表详细展示了您的存储中所有 MergeTree 系列表(MergeTree-family tables)的每个物理数据部分的信息。每行对应一个数据部分,使其成为监控存储、诊断合并行为和理解表健康状况的理想选择。其中最关键的列包括:active 指示一个数据部分是当前活跃的,还是已完成合并后留下的旧部分;因此,通过 active = 1 进行过滤,可确保查询只关注活跃的相关部分。partition 和 partition_id 显示了每个数据部分所属的分区,而 rows、bytes_on_disk、data_compressed_bytes 和 data_uncompressed_bytes 则清晰地展示了数据部分的大小和压缩效率。part_type 区分 Wide 和 Compact 两种数据部分,它们决定了列的存储方式。在 Wide 格式中,每个列都存储在各自独立的文件中,这是较大数据部分的标准格式,并在读取时实现了高效的列裁剪(column pruning)。Compact格式将所有列存储在单个文件中(默认小于 10MB),这减少了文件句柄(file handle)的数量,对于行数较少的小型数据部分而言,效率更高。
值得我们随时取用的两个查询是:
各表的数据部分数量和大小:
SELECT table, count() AS parts, sum(rows) AS total_rows, formatReadableSize(sum(bytes_on_disk)) AS size_on_diskFROM system.partsWHERE activeGROUP BY tableORDER BY parts DESC;复制代码
过度分区表:
SELECT table, partition, count() AS partsFROM system.partsWHERE activeGROUP BY table, partitionHAVING parts > 10ORDER BY parts DESC;复制代码
ReplacingMergeTree 是 ClickHouse 中备受欢迎的表引擎之一,它用于支持需要去重(deduplication)或更新插入(upserts)的场景。此表引擎根据指定列(例如版本/时间戳)保留每行的最新版本。去重操作依据 ORDER BY 列的唯一性进行。旧的重复数据会在后台合并(background merges)过程中被舍弃。需要注意的是,这些合并是异步进行的,这意味着在查询时,表中可能仍然存在重复行。若要获取正确的结果,需要使用 FINAL 或 argMax 模式,并深入理解它们之间的权衡。
FINAL 是最简单的方式,只需将其添加到查询中,ClickHouse 就会透明地处理去重操作。然而,代价是 FINAL 在返回结果之前必须协调(reconcile)所有的数据部分,其性能与查询时存在的数据部分数量直接相关。在一个合并良好、分区中只有一个数据部分的表上,使用 FINAL 与否,性能差异不大。而在一个处于数据摄取(ingestion)中期、存在大量数据部分的表上,它可能带来显著的性能开销。
SELECT star_ratingFROM mytests.amazon_reviews_rmt FINALWHERE review_id = ''复制代码
argMax 模式是一种替代方案,它将去重逻辑整合到聚合操作本身中,从具有最高版本的行中选取值:
SELECT argMax(star_rating, review_date)FROM mytests.amazon_reviews_rmtWHERE review_id = ''复制代码
在包含 1.52 亿行(1.5 亿原始行 + 200 万重复行)的 Amazon reviews 数据集上,这两种方法的性能差异与表的状态密切相关。在存在 9 个未合并的数据分块时,上述使用 FINAL 的查询耗时 1.5 秒,而 argMax 耗时 1.0 秒。为了展示数据分块更少时的差异,我们强制将这些数据分块合并为一个单一分块,此时两种方法的性能均下降到大致相同的水平:0.48 秒对比 0.40 秒。尽管具体结果可能因查询形态、基数和数据分块数量而异,但这一规律依然成立:无论合并状态如何,argMax 都表现出更高的稳定性,而 FINAL 则随着数据分块的合并,性能显著提升。
实际上,对于日常查询或当表数据合并良好时,FINAL 是一个更简单的选择。而当处理有活跃写入的表,并且需要可预测的延迟时,argMax 则更值得选用。
在生产环境中,减少 FINAL 性能不稳定性的一种方法是配置后台合并,使其对旧数据处理得更积极。默认情况下,ClickHouse 会根据内部启发式算法合并数据分块,该算法会考虑数据分块的大小、数量和创建时间,但并没有强制将一个分区的数据合并成一个单一分块的机制。这意味着一个表可以无限期地保持每个分区拥有多个数据分块,从而导致 FINAL 持续产生额外开销。min_age_to_force_merge_seconds 设置改变了这一默认行为,它会强制 ClickHouse 不断合并早于指定阈值的数据分块,直到每个分区只剩下一个数据分块:
min_age_to_force_merge_seconds = 600, min_age_to_force_merge_on_partition_only = 1;复制代码
请注意,这样做可能会增加后台合并的负载,因为 ClickHouse 会持续合并数据分块直到每个分区只剩下一个,从而占用更多本可用于查询或写入的 CPU 和 I/O 资源。
min_age_to_force_merge_on_partition_only = 1 标志确保此操作仅在所有数据块(parts)都已足够旧的分区上触发,从而避免干扰仍在活跃写入的分区。值得注意的是,为了使此设置在实践中有效,表应该进行分区。如果没有分区,所有数据将存储在单个分区中,可能积累过多的数据。由于 ClickHouse 默认不会合并会使数据块大小超过 150GB 的分块,因此将所有数据整合为单个数据块变得不切实际。通过按月或按年分区,每个分区都将保持在可控的尺寸范围内,从而能够合并为单个数据块,这正是 FINAL 操作性能最佳的状态。
过去,ClickHouse 中的 JOIN 曾是建议用户谨慎使用的一个特性,普遍的建议是尽可能通过反范式化(denormalization)、字典(dictionaries)或物化视图(materialized views)来避免使用 JOIN。这一建议在当时是合理的,但显著的引擎级改进使 JOIN 在高并发生产工作负载中变得越来越可行。作为默认查询执行层引入的 Analyzer(查询优化器)为 JOIN 规划带来了重大改进:ClickHouse 24.4 引入了更好的谓词下推(predicate pushdown)功能,通过将过滤条件推送到 JOIN 的两侧,可将查询性能提升 10 倍;版本 24.12 获得了自动重新排序双表 JOIN 的能力,将较小的表放在右侧;25.9 则将此功能扩展到连接三个或更多表的查询。结合多种 JOIN 算法可供选择以平衡不同的内存和性能考量,如今 ClickHouse 中的 JOIN 其能力显著增强,也更容易正确使用,甚至比一年前有了巨大的提升。
尽管如此,JOIN 在分析型数据库中仍然伴随着开销,因此有几项原则值得遵循。对于对毫秒级延迟有严格要求的实时工作负载,目标是每个查询最多包含 3 到 4 个 JOIN。此外,反范式化、字典或预聚合物化视图是值得考虑用于进一步提升查询性能的工具。
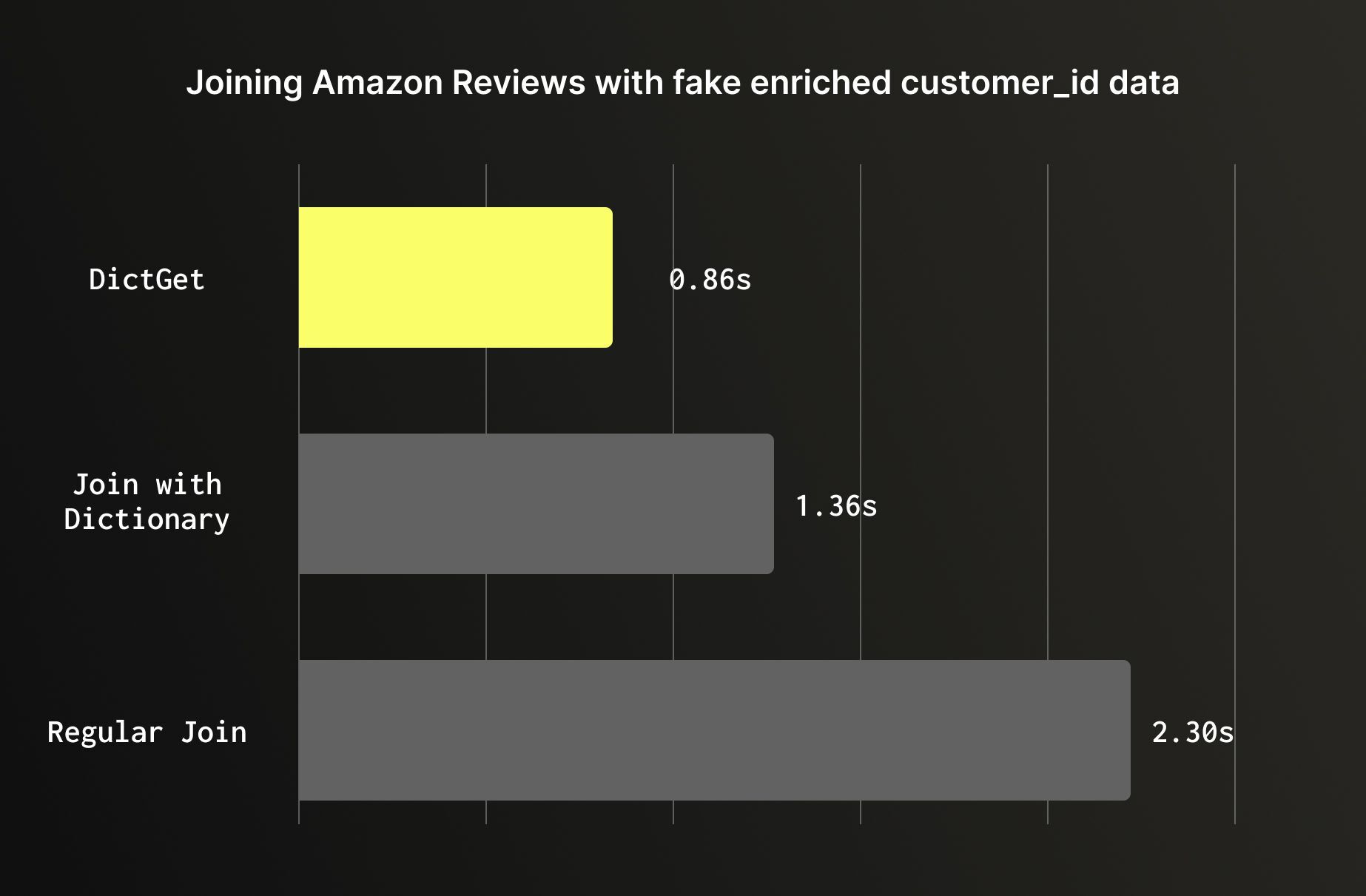
对于静态或变化缓慢的查找,推荐使用字典。当需要用不常变动的小型参考表数据来丰富大型表时,字典的性能将优于常规连接。字典会完全加载到内存中,并通过 dictGet 进行访问,从而彻底绕过哈希连接过程。以客户元数据丰富后的 Amazon reviews 数据集为例,性能差异显著:在 1.5 亿行数据上执行常规 JOIN 操作耗时 2.3 秒,与字典表进行连接耗时 1.36 秒,而 dictGet 操作仅需 0.86 秒;这比基准连接快了近 3 倍,且底层数据无需修改。
ClickHouse 开箱即用即表现出极快的速度,但要充分发挥其潜力,就必须深入理解其数据存储、合并和查询机制。本文介绍的最佳实践并非孤立存在,而是相辅相成。精心选择的 ORDER BY 子句通常能使跳跃索引 (skipping indexes) 更为高效。恰当的数据类型能够减轻物化视图和投影的工作负担。明智的分区策略能让 ReplacingMergeTree (ReplacingMergeTree) 和基于 TTL 的过期策略 (TTL-based expiration) 有序运行。优化数据摄取过程能保持健康的数据分片数量,进而确保 FINAL 操作的执行效率。
本文中贯穿使用的 Amazon reviews 数据集基准测试表明,这些并非微不足道的提升:选择正确的主键能将扫描数据量减少 347 倍,正确的数据类型能将存储空间削减 12% 并将查询时间缩短 50%,不必要的分区可能导致查询速度降低 46 倍,而字典查找的性能可比常规连接快 3 倍。这些都是纯粹源于设计决策而非硬件升级所带来的数量级差异。
如果你是 ClickHouse 的初学者,应重点关注前两点:主键设计和数据类型。它们的影响最为广泛,适用于你创建的每个表。在此基础上,在查询需要时添加跳跃索引,仅在有明确理由时进行分区,并根据具体用例需求采用物化视图和 ReplacingMergeTree。
ClickHouse 会回馈那些深入理解其架构的用户。你的 schema 和查询与 ClickHouse 数据管理方式越是契合,你的系统就将越快、越高效。在理想情况下,这意味着你能够摄取数十亿行数据,并以毫秒级的速度查询它们。
/END/
面向社区长期正文,文章内容包括但不限于关于 ClickHouse 的技术研究、项目实践和创新做法等。建议行文风格干货输出 &图文并茂。质量合格的文章将会发布在本公众号,优秀者也有机会推荐到 ClickHouse 官网。请将文章稿件的 WORD 版本发邮件至:Tracy.Wang@clickhouse.com。


此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。