OpenAI 近期介绍了如何为全球规模的低延迟语音 AI 调整 WebRTC。新的架构将传统的媒体终结模型替换为更适合 Kubernetes 和云负载均衡器的中继收发器架构。它将 WebRTC 会话状态保留在专用的收发器层,同时利用轻量级中继来减少公共 UDP 暴露,并让媒体路由更贴近用户。
在这篇文章中,OpenAI 的技术人员 Zhang Yi 和 William McDonald 解释说,实现全球覆盖、快速建立连接以及保障媒体往返时延偏低且稳定是此次架构调整背后的主要制约因素。团队评估了多种媒体会话对外暴露的方案,各类方案在实际运行中各有利弊。
第一种方案是直接对外暴露 UDP 端口,沿用传统 WebRTC 架构模式。但该方案会把运维压力转嫁至基础设施层面,尤其是在 Kubernetes 环境中,大规模的公网端口难以安全管控。为每台服务器单独分配专属端口虽能简化部分路由决策,却依旧会让运维人员面临端口规划困难、端口使用率失衡以及部署发布稳定性差等问题。
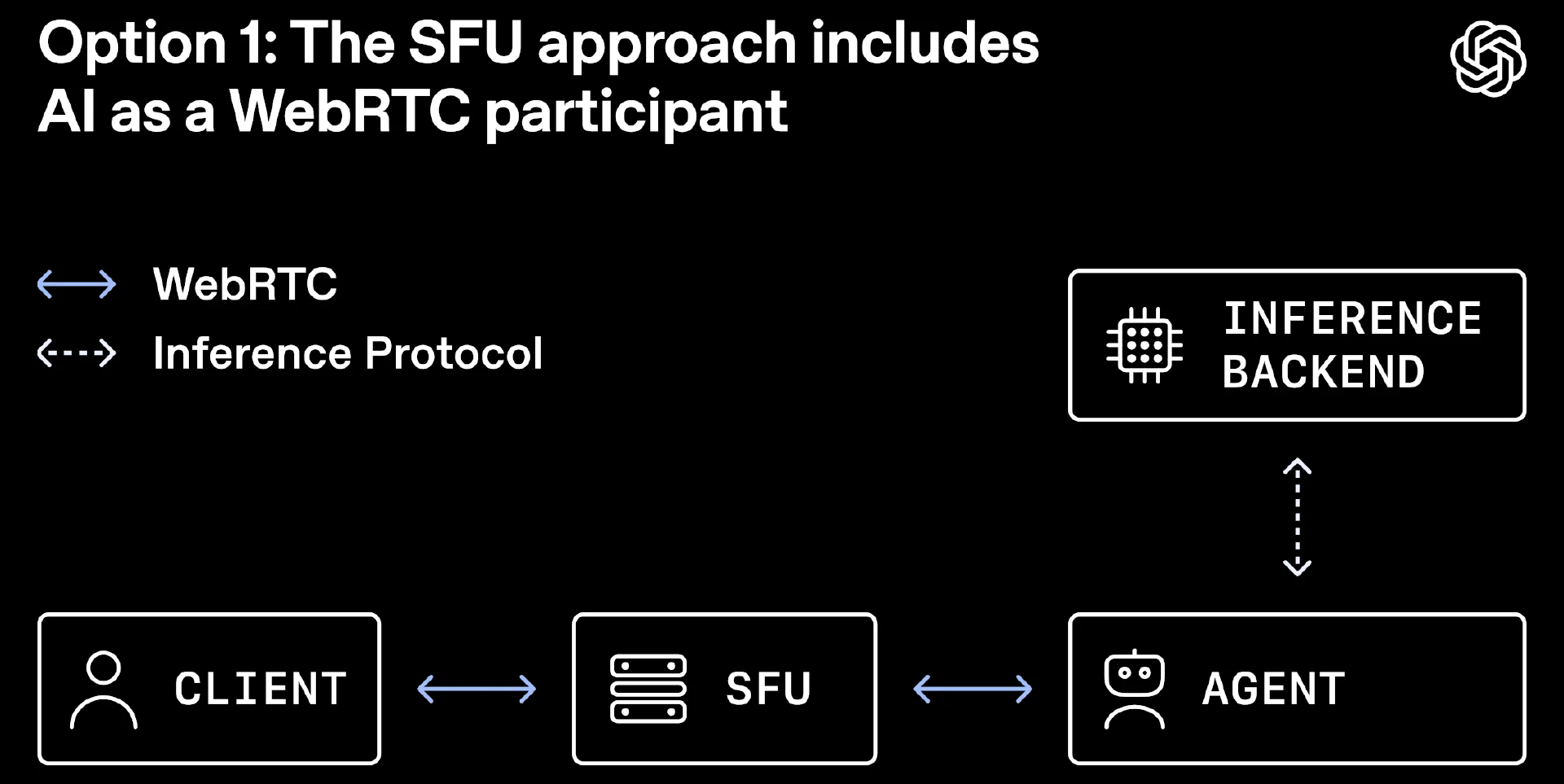
选项 1:SFU 方案——将 AI 作为 WebRTC 参与者(来源)
TURN 风格的中继也是一个可行的选项,但它们会在媒体路径中引入更重量级的中间层,所能解决的问题超出了 OpenAI 以一对一为主的模型与用户会话的需求。OpenAI 选择在两层之间划分职责,轻量级中继负责接收传入的数据包并转发,收发器则承载所有有状态的 WebRTC 机制,包括 ICE 协商、DTLS 握手、SRTP 加密以及整体会话生命周期。
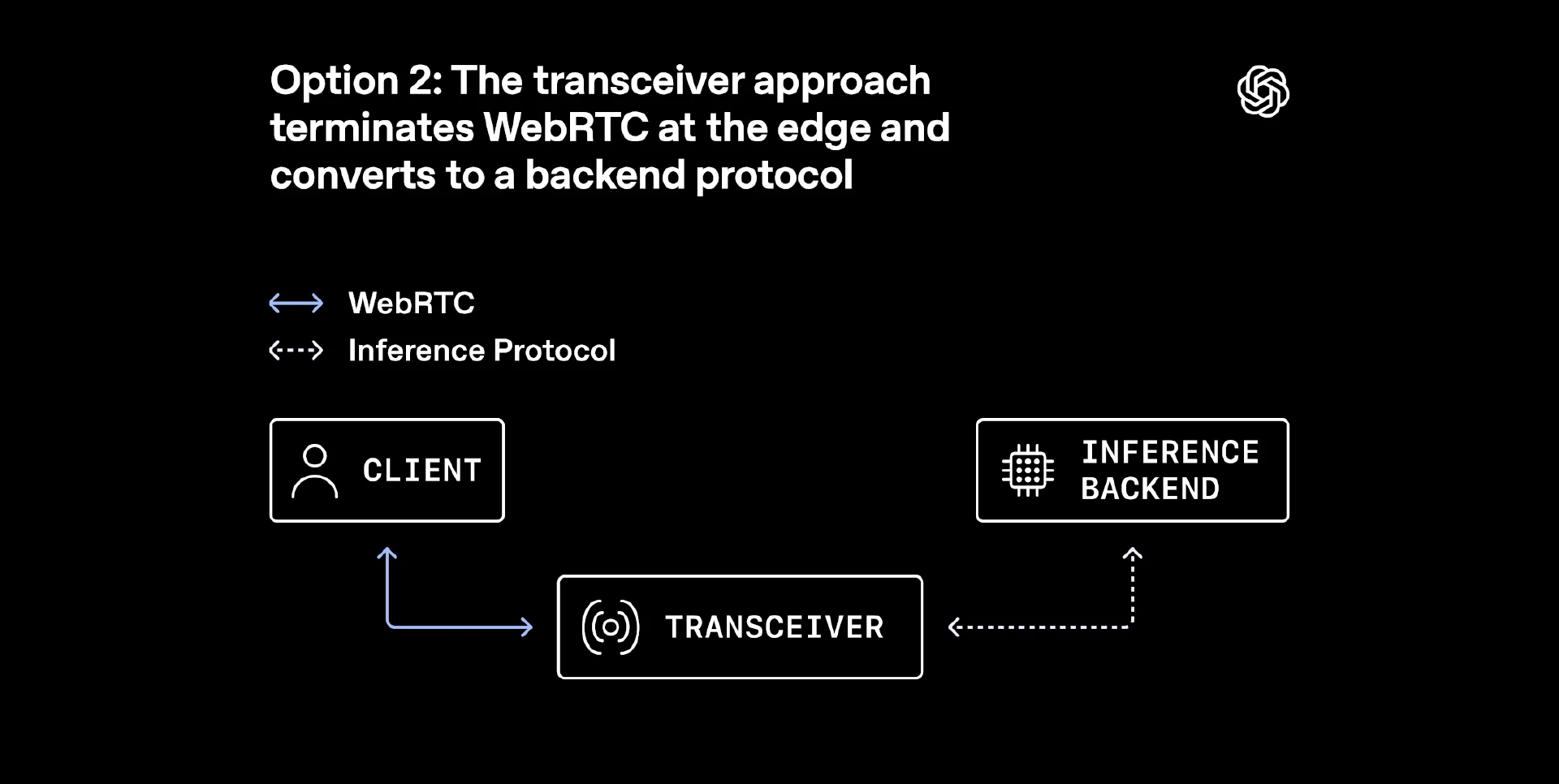
选项 2:收发器方案——在边缘终结 WebRTC 并转换为后端协议(来源)
这种职责分离让中继能够保持简单、快速且基本无状态,收发器成为唯一需要理解完整协议的组件。这既避免了后端服务之间重复堆砌复杂逻辑,也不会将复杂逻辑转嫁到客户端层面。作者表示:“新增复杂逻辑最合理的位置是精简的路由层,而非各个后端服务,也不是客户端。”
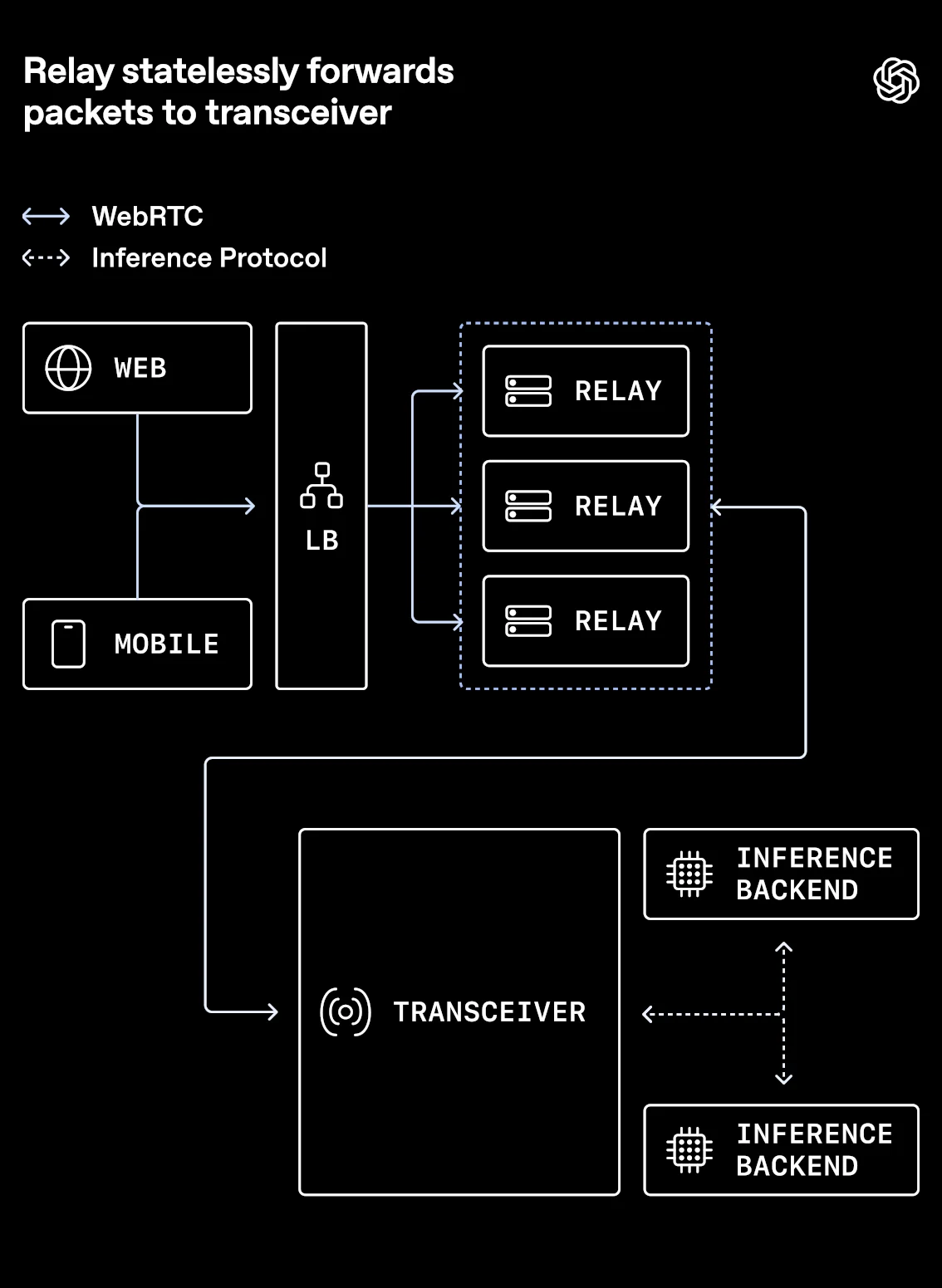
中继将数据包无状态地转发给收发器(来源)
WebRTC 是实时 AI 业务场景中常用的技术方案。除了低延迟媒体传输外,它还提供 NAT 穿透、加密传输、编解码器协商、抖动缓冲以及回声消除等跨浏览器和移动平台的音频功能。STUN 是这个技术体系的基础组成部分,能够协助终端设备确认自身在网络中的对外地址,并在连通性检测阶段为 ICE 流程提供支撑。
许多团队都会默认使用选择性转发单元(SFU),用来为多方系统集中管理媒体路由和传输策略。但 OpenAI 的工作负载主要是用户与模型之间的一对一会话,相比把模型当作会议架构里的普通参与端,采用收发器设计会更为合适。
这篇文章补充了 OpenAI 在实时语音技术布局中更多基础设施层面的细节,相关功能已在其产品中提供,例如 ChatGPT 语音和 Realtime API。对于搭建交互式媒体系统的架构师而言,这套架构拆分思路更具参考价值:在边缘保留协议行为,将硬会话状态集中在一处,并将复杂性移入薄路由层,而不是将其分散到后端服务中。
查看英文原文:https://www.infoq.com/news/2026/05/openai-voice-ai-scale/
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。