SPEC’s CPU benchmark suite has been a long established industry standard, and is almost impossible to miss when reading through various publications. Intel used SPEC CPU2000 to showcase Pentium 4’s improvements over Pentium III. Samsung used SPEC CPU2000 and SPEC CPU2006 traces to tune their Mongoose cores. SPEC CPU2017 formed part of Intel’s performance projections for Lion Cove. Now, SPEC has updated their CPU benchmark suite with SPEC CPU2026. The new suite consists of 52 workloads, up from 43 in SPEC CPU2017. Individual workloads consist of more source code lines, measured in KLOC (thousands of lines of code). SPEC’s goal is to modernize their CPU benchmark suite, while retaining the portability goals that characterized SPEC.
Because of SPEC’s importance in the CPU performance world, I’ll be looking over the new suite’s workloads to examine the challenges that they serve up to CPUs. I’m interested in hardware rather than compiler comparisons, so I’ll be using GCC 14.2.0 with -O3 and native architecture/optimization targets. I did try GCC 15.2.0, but ran into various issues and decided to stick with GCC 14.2.0 to conserve time. I’m testing all of the systems below using Linux.
SPEC CPU scores represent speedup ratios relative to a reference system. Each SPEC CPU update tends to update the reference system, though not always to one that’s a relevant comparison for recent hardware.
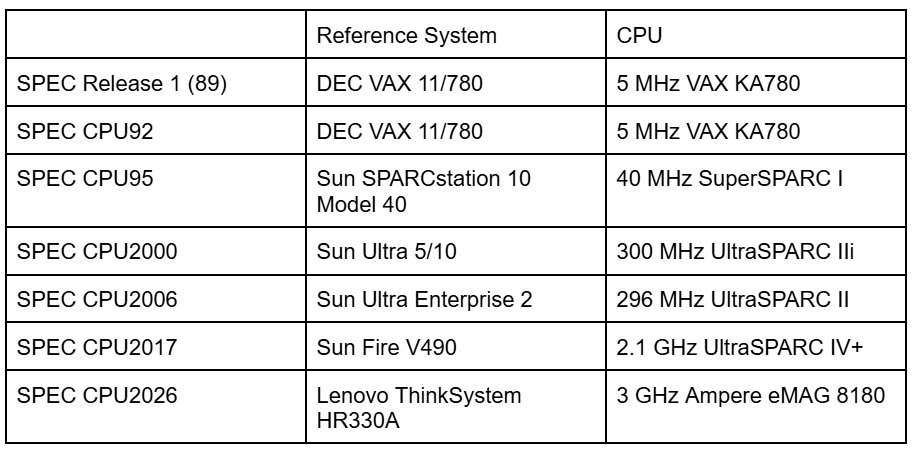
An Ampere eMAG 8180 system provides the reference score of 1.0 for SPEC CPU2026. Ampere’s eMAG is faster than the Sun Fire V490 used for SPEC CPU2017, in much the same way that a Cessna 172 might be faster than a Sopwith Camel. Neither is a good comparison against modern airliners. Similarly, Ampere eMAG was not a widely deployed platform, and even systems that pre-date it by many years outperform it by a large margin. I’ve heard part of the motivation behind using a slower system was to let most systems achieve high scores, but that could have been accomplished by making the reference score a higher number, like 1000, instead of 1.0. Geekbench 6 takes a more reasonable approach, with a Core i7-12700 calibrated to a reference score of 2500. Unlike Ampere’s eMAG, Intel’s Core i7-12700 and similar CPUs were widely deployed across consumer systems, and Intel today uses a similar core architecture in Xeon 6.
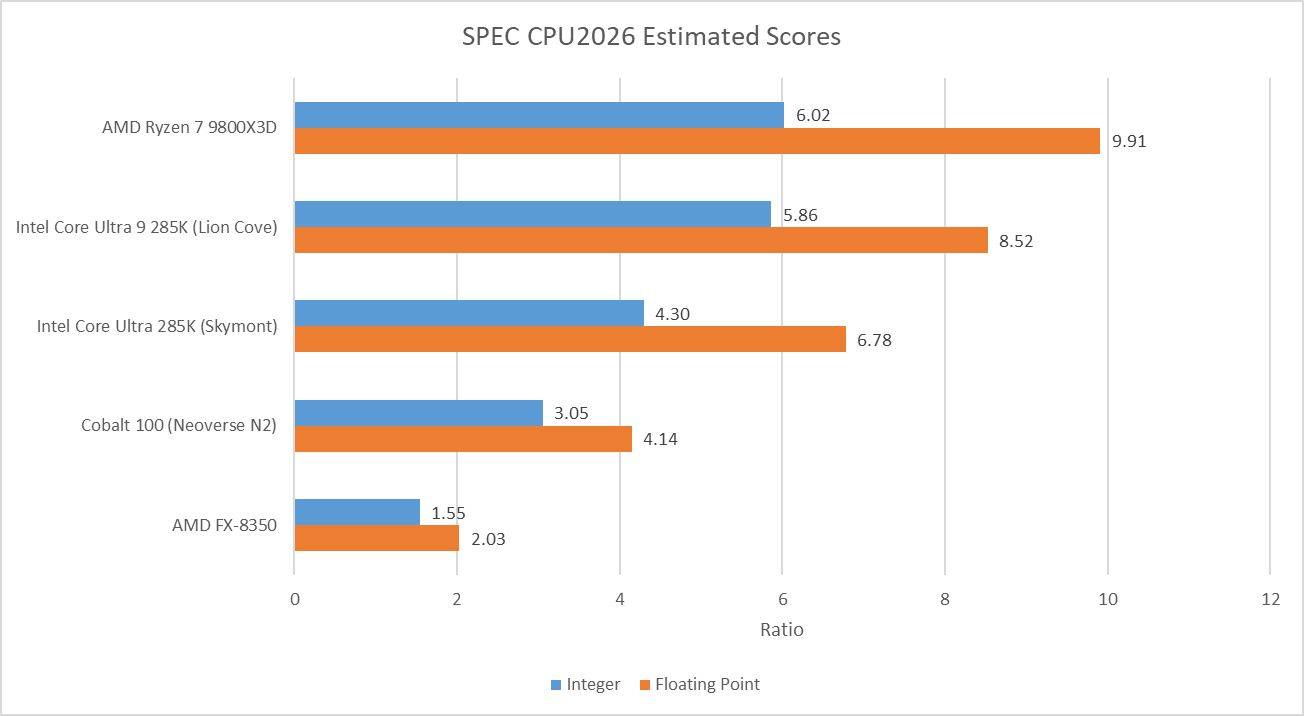
Examples of Intel and AMD’s latest desktop CPUs show similar performance in SPEC CPU2026’s integer suite, while Zen 5 tends to pull ahead in floating point tests. I had to run SPEC CPU2026 on a Lion Cove core that only reached 5.5 GHz, because the two 5.7 GHz capable cores had trouble completing the test suite without crashes. There seems to be something wrong with my sample, but I suspect a Lion Cove core that does complete the tests at 5.7 GHz would narrow the gap.
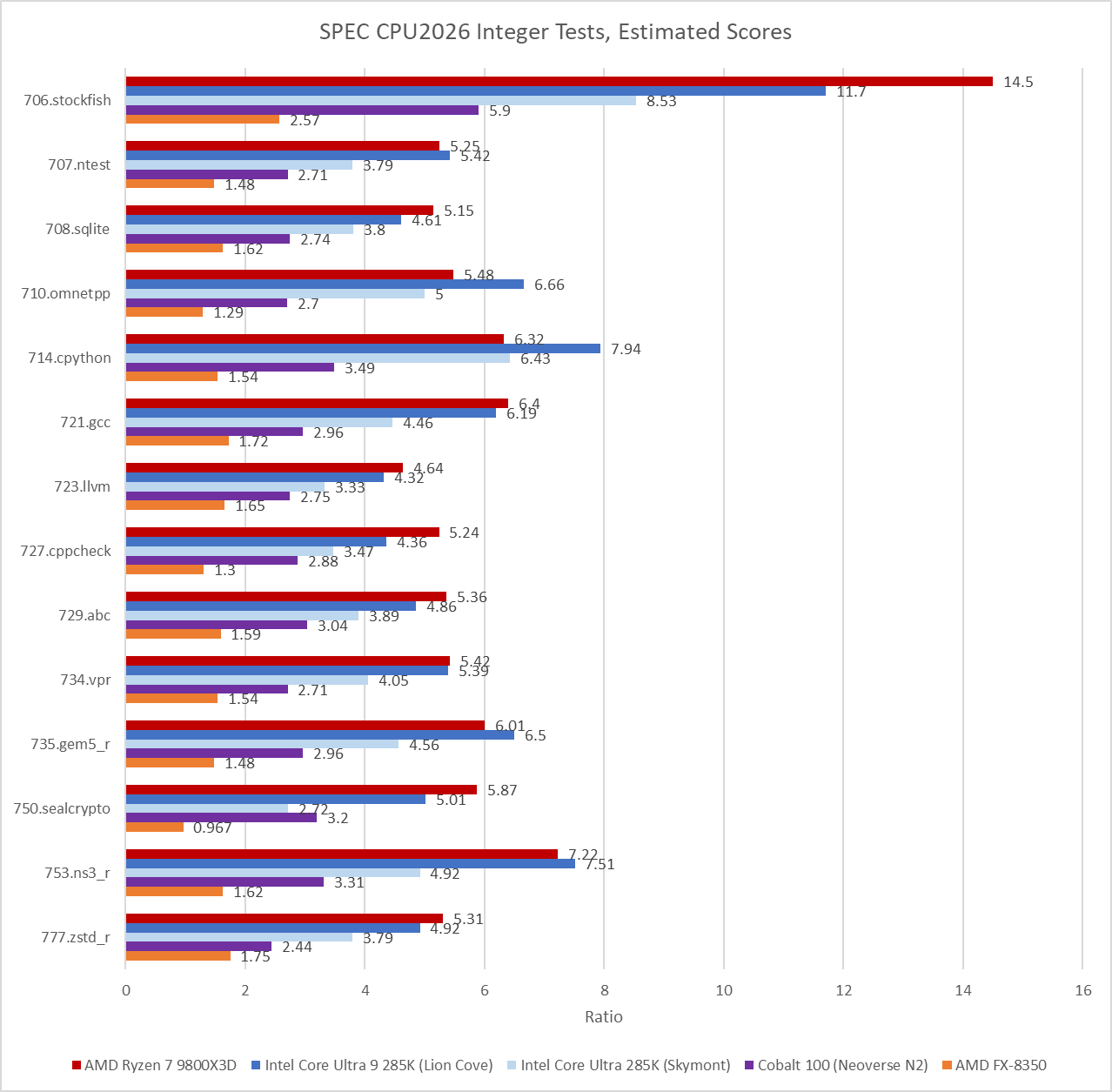
Individual scores in the integer suite show Zen 5 and Lion Cove closely matched, as the aggregate scores would suggest. Absolute scores show just how far outmatched the Ampere eMAG system is. Current desktop cores obliterate ones in the Ampere eMAG, especially in 706.stockfish. Even the FX-8350, which is over a decade old, might be a better reference point. It also sails way past the eMAG system in nearly every test.
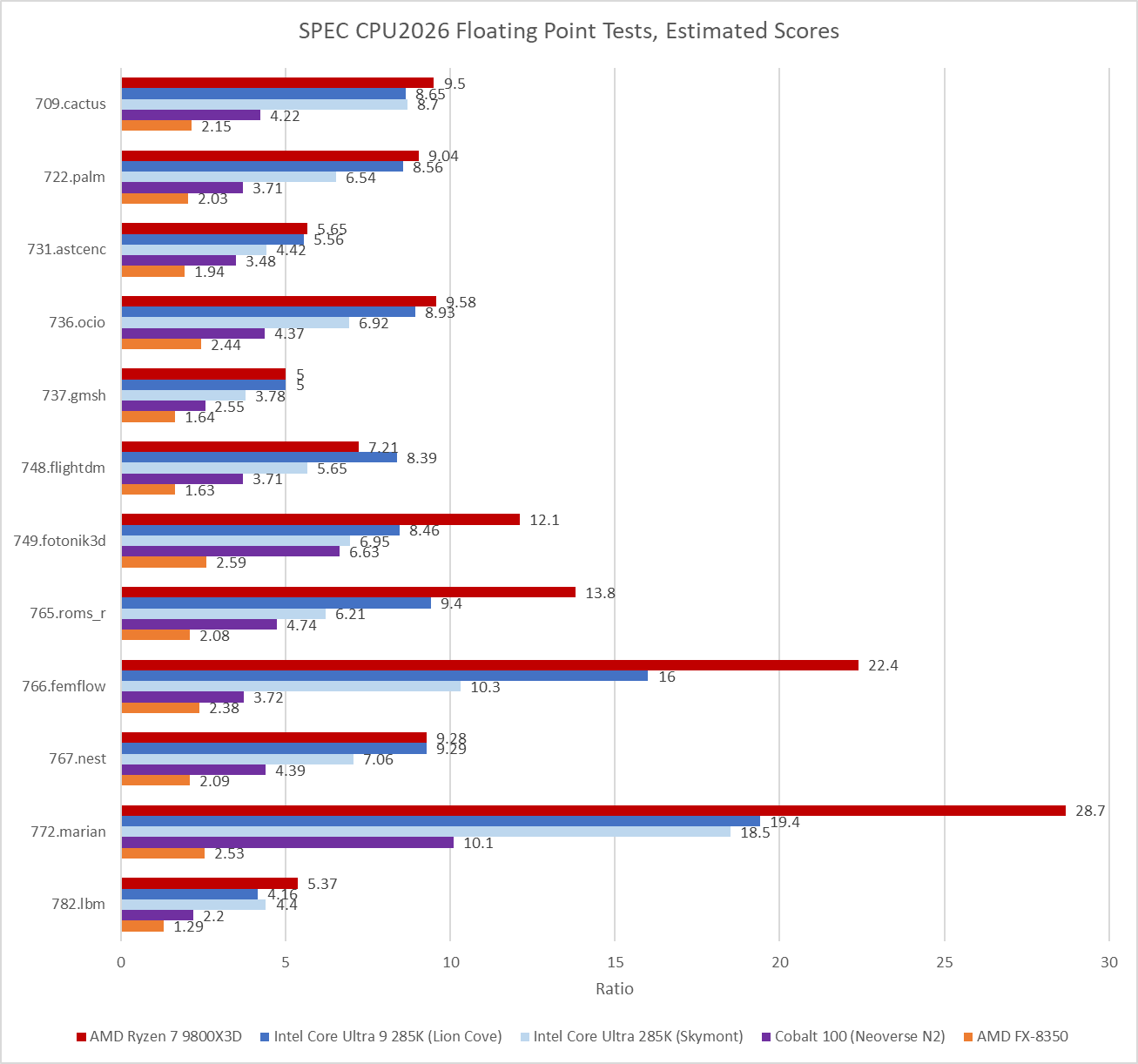
Floating point workloads are even worse for the old eMAG system. Zen 5 has a field day in several of the floating point workloads. Some of that is because GCC was able to generate AVX-512 instructions. I used Intel’s Software Development Emulator to get instruction counts for the last invocation of each workload, to give an idea of what instruction types are in use. Some SPEC CPU2026 tests run multiple commands to test the same binary against different input data, but I only profiled the last invocation to save time.
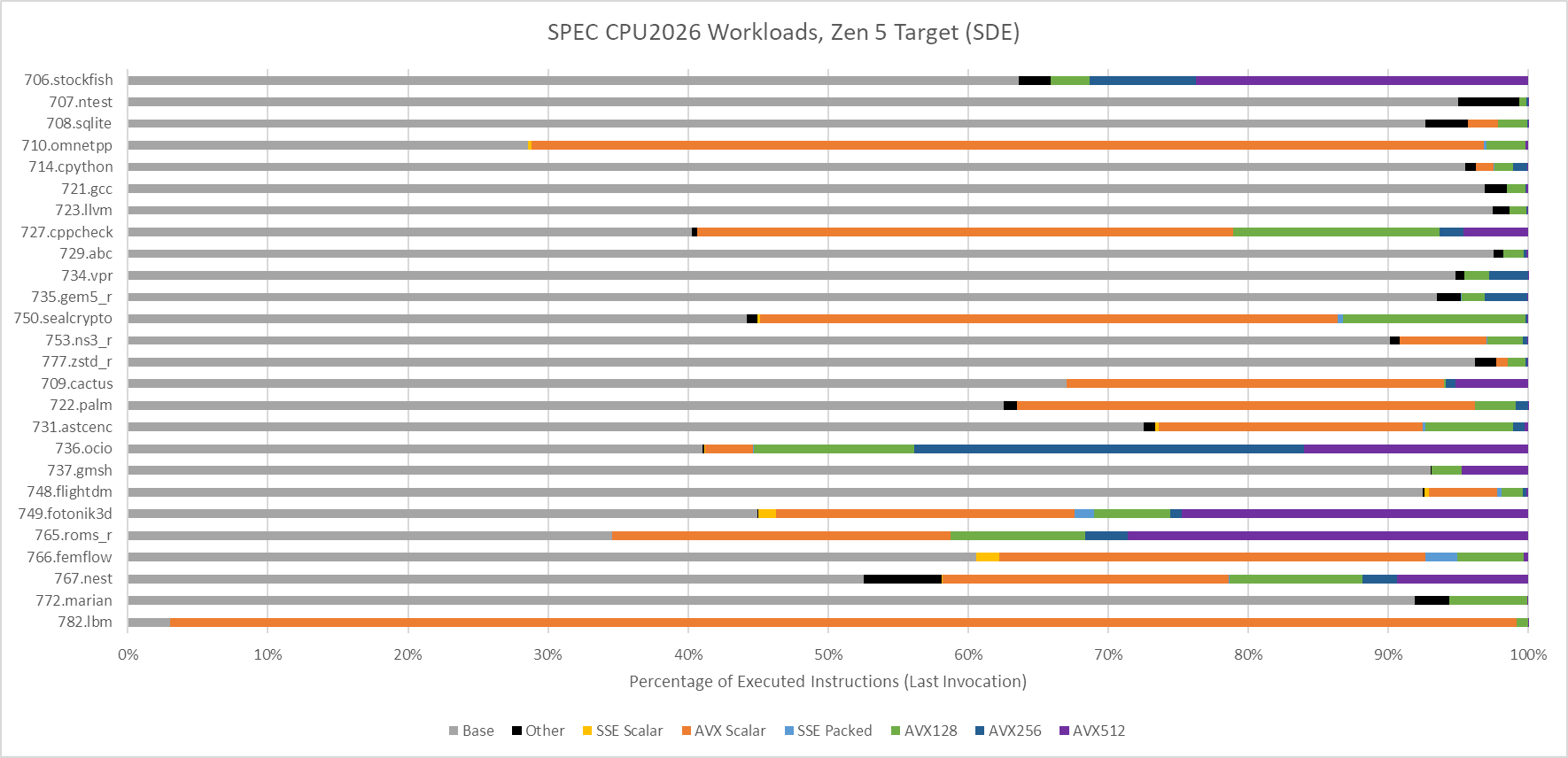
706.stockfish, 749.fotonik3d, and 765.roms all include AVX-512 code when compiled with GCC 14.2.0. Several other tests take advantage of 128-bit or 256-bit vectors too.
Average IPC, or instructions per cycle, gives a rough idea of how well CPU cores can bring their execution resources to bear. Low IPC often indicates cache misses, branch mispredicts, or less commonly, specific performance hazards in a core’s architecture. High IPC suggests performance is limited more by execution latency, execution resources, or core width. IPC of course shouldn’t be confused with actual performance, which depends on clock speed as well as work done per instruction.
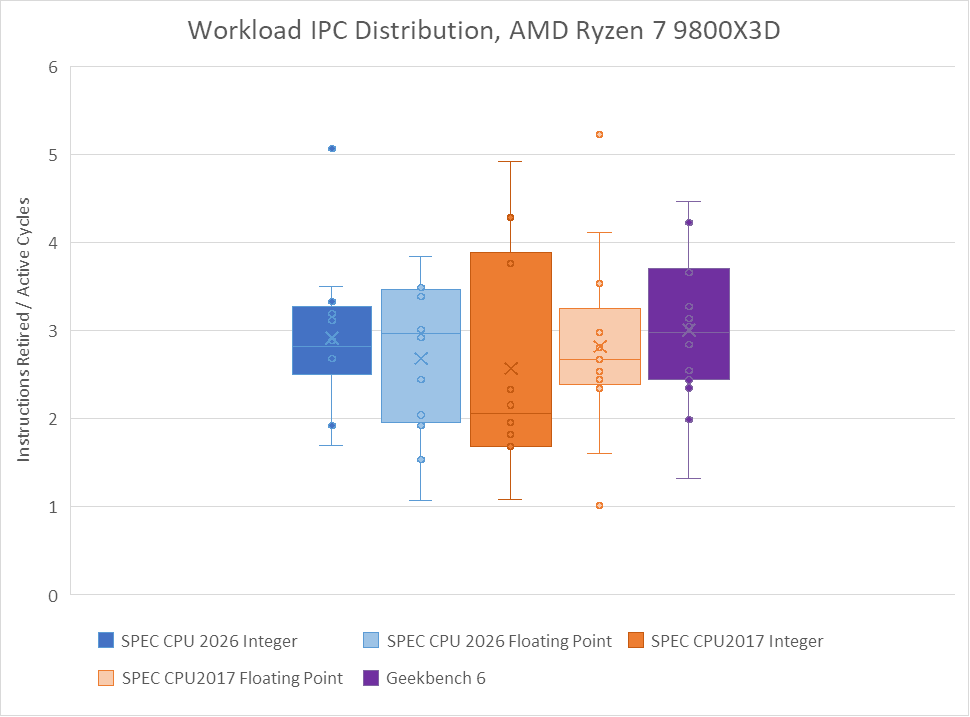
SPEC CPU2026’s integer suite displays a higher and tighter IPC distribution than SPEC CPU2017’s integer suite on both AMD’s Zen 5 and Intel’s Lion Cove. The IPC spread feels close to that of Geekbench 6, which tends to emphasize core throughput with few branch mispredicts or last level cache misses.
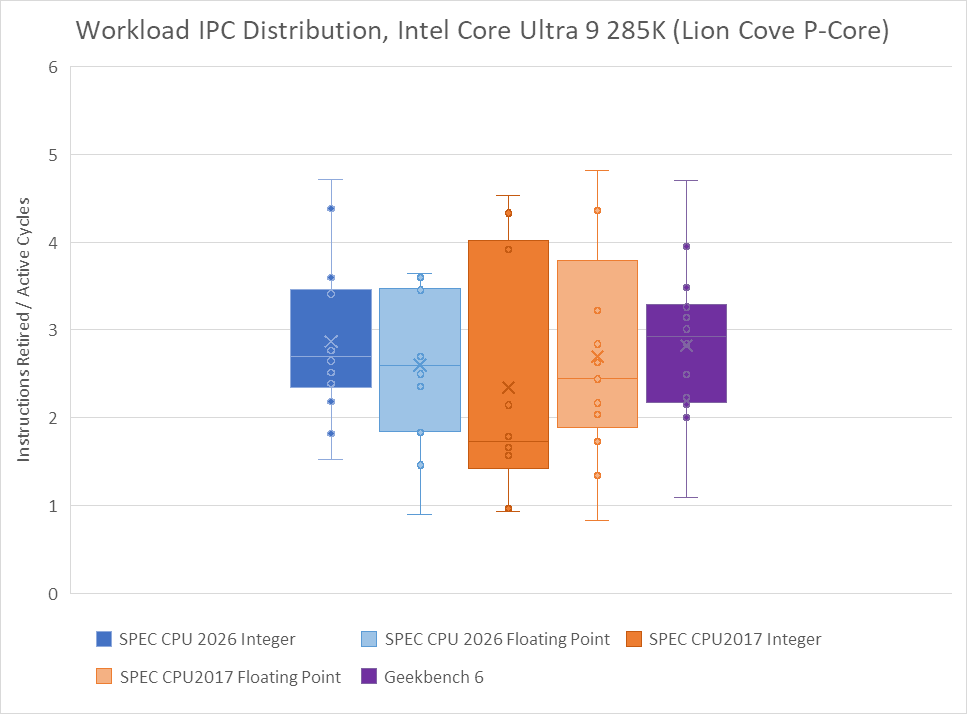
Floating point workloads get a wider spread on Zen 5 with the updated suite, while SPEC CPU2017’s floating point tests tended to bunch up around 2-3 IPC. Lion Cove had a wider IPC spread with the older floating point suite, and continues to see a wide spread in the new one.
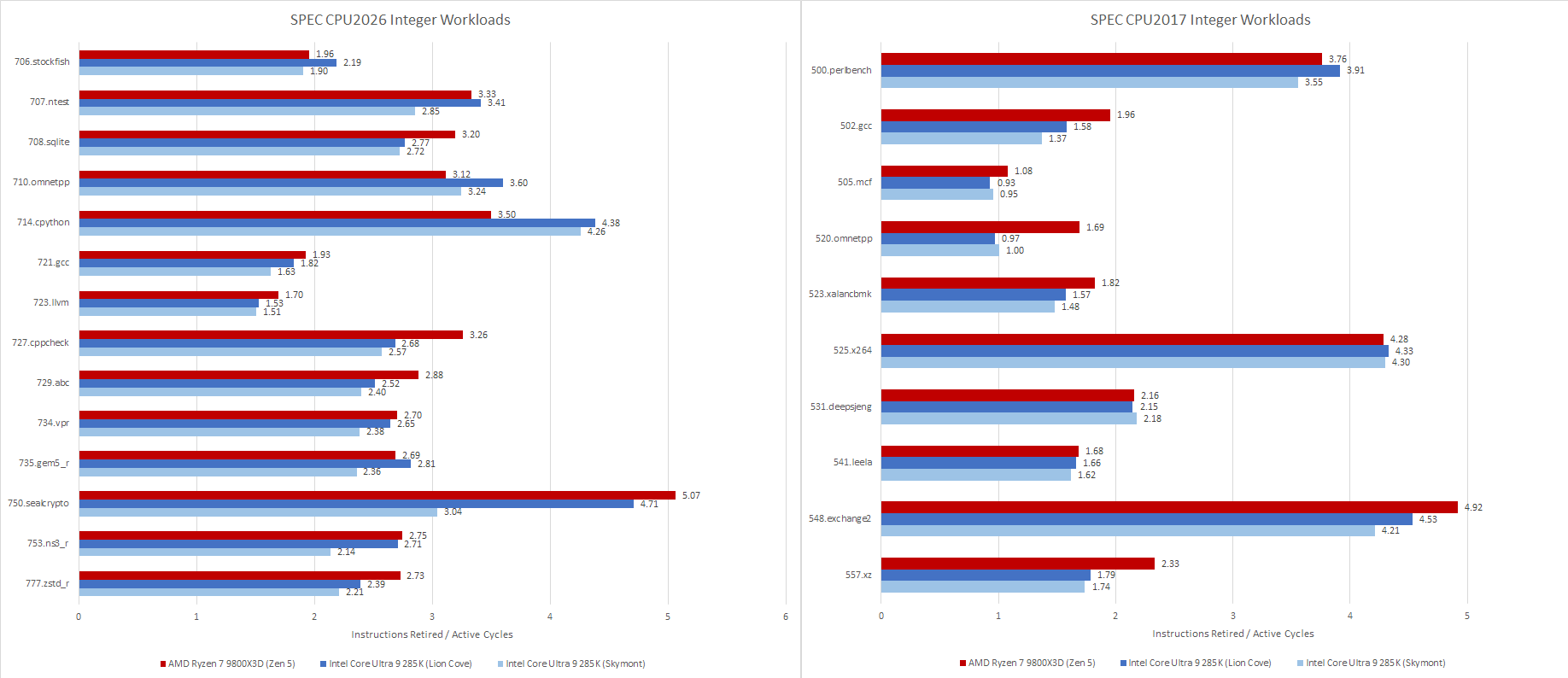
505.mcf and 520.omnetpp were low IPC workloads in SPEC CPU2017. Both suffered plenty of cache misses, and 505.mcf suffered a lot of branch mispredicts too. Neither test has an equivalent in SPEC CPU2026’s integer suite. MCF is gone, and 710.omnetpp is a completely different animal despite sharing the same name as the old test. Two code compilation tests, 721.gcc and 725.llvm, take over as the lowest IPC integer tests. They still average above 1.5 IPC though, which isn’t too low. For perspective, most PC games average around 1 IPC.
On the other hand, SPEC CPU2026’s integer suite includes plenty of high IPC workloads. More than half average close to 3 IPC if not beyond. 750.sealcrypto reaches the highest IPC across all integer workloads on both Zen 5 and Lion Cove. It’s also a high IPC workload on the Skymont E-Core, if just a little less so.
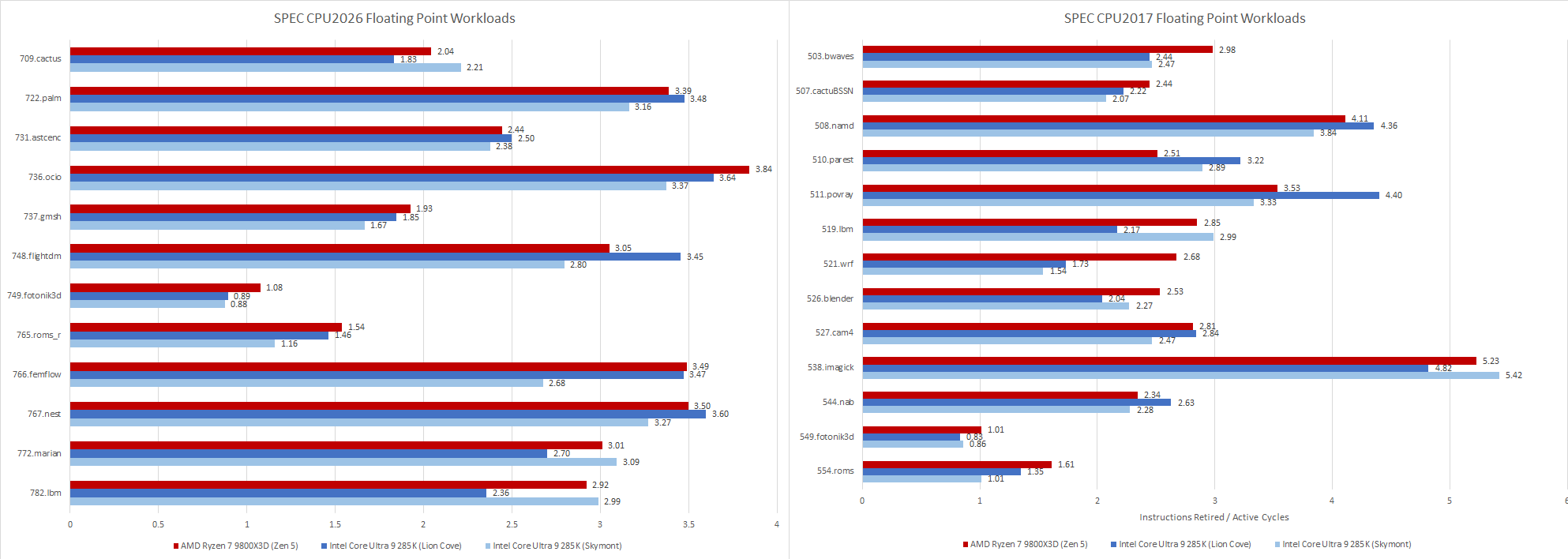
SPEC’s floating point workloads tend to focus on core throughput, and that remains the case with SPEC CPU2026. Many workloads sit above 2 IPC, which I consider a medium to medium-high IPC range. 749.fotonik3d and 765.roms fill the same role as their SPEC CPU2017 counterparts, and continue to stress DRAM performance by often missing in the last level cache. At the high IPC end, 538.imagick is gone with no direct replacement. Several SPEC CPU2026 floating point workloads do average well above 3 IPC, but none go as astronomically high as 538.imagick did.
Top-down analysis attributes under-utilized core width to various reasons, and provides a high level overview of where potential core throughput is being lost. It works at the rename/allocate stage, which is typically the narrowest part of a CPU’s pipeline that all instructions must pass through. Each pipeline slot at that stage is classified as follows:
Retiring: Slot was used by a micro-op that ultimately retired, meaning its results were made architecturally visible after passing all checks. Retired micro-ops represent useful work.
Backend Bound: A micro-op was available from the frontend, but couldn’t be sent to the backend because a required out-of-order tracking resource wasn’t available. That could mean the reorder buffer, register files, or memory ordering queues didn’t have a free entry when one was needed.
Frontend Bound: The frontend didn’t supply enough micro-ops to feed all renamer slots
Bad Speculation: A micro-op went through the slot, but wasn’t retired. This represents wasted work, for example from branch mispredicts
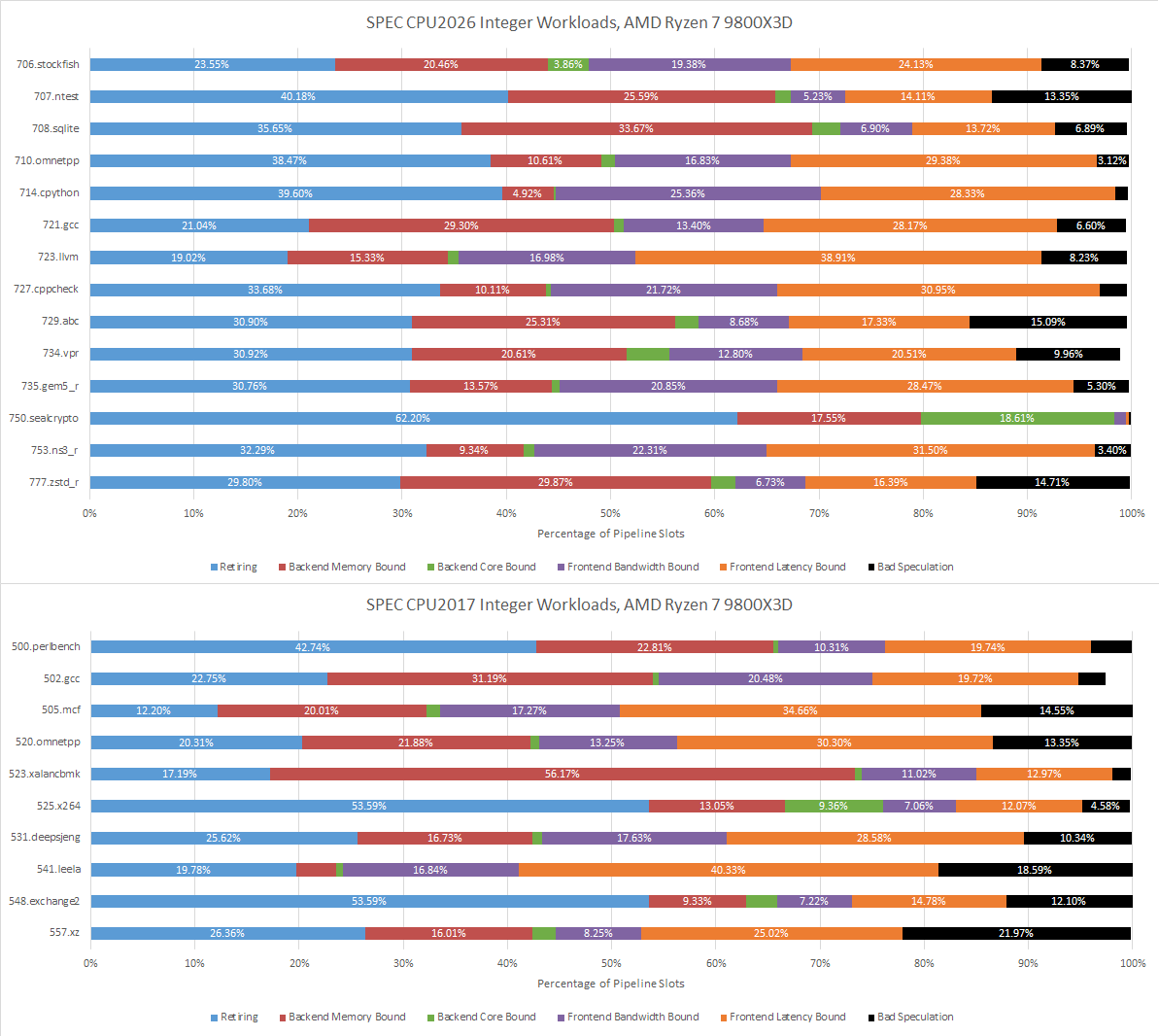
Retiring slots are up across the board compared to SPEC CPU2017’s integer suite, which is expected given the higher IPC figures seen above. 723.llvm and 721.gcc are mostly held back by frontend latency, which is classified as cycles where the frontend didn’t supply any micro-ops to the renamer. Both 723.llvm and 721.gcc are branchy workloads and occasionally suffer mispredicts, which interrupts the frontend’s ability to follow the instruction stream and smoothly deliver micro-ops. At the other end, 750.sealcrypto barely has any branches. Both Lion Cove and Zen 5 blast through it unimpeded, since there’s not much slowing their backends either.
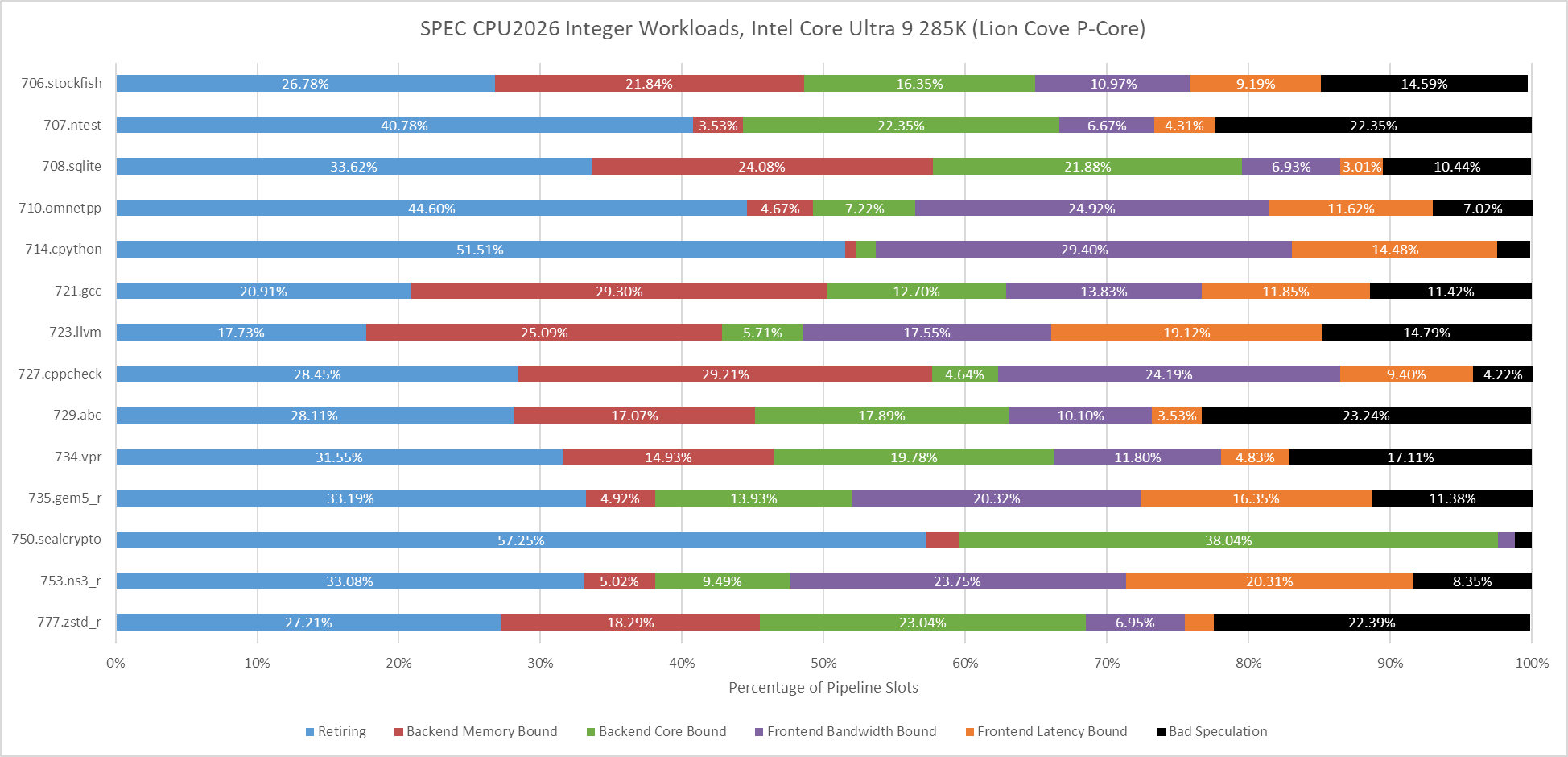
SPEC CPU2017’s floating point workloads tend to focus more on core throughput, and that continues to be the case in SPEC CPU2026. Branches tend to be rare and predictable, letting the frontend on Lion Cove and Zen 5 operate with high efficiency.
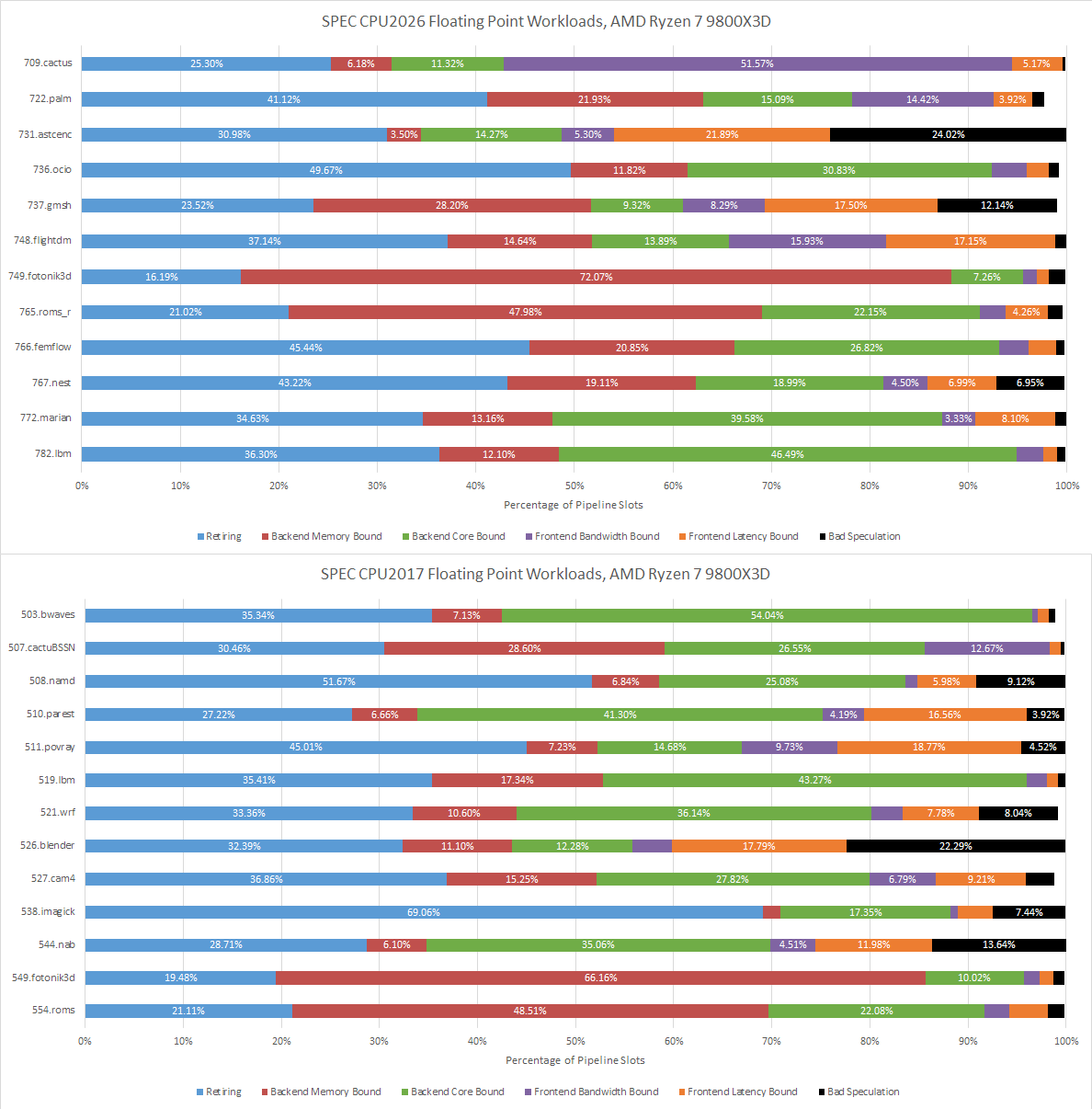
Fotonik3d and roms are heavily backend memory bound on both Lion Cove and Zen 5. Most other tests are core-bound, though there are exceptions. Both Lion Cove and Zen 5 are challenged in similar ways, except for 709.cactus. In that test, Zen 5 is bound by frontend bandwidth, meaning the frontend delivered some micro-ops but not enough to fill all eight renamer slots.
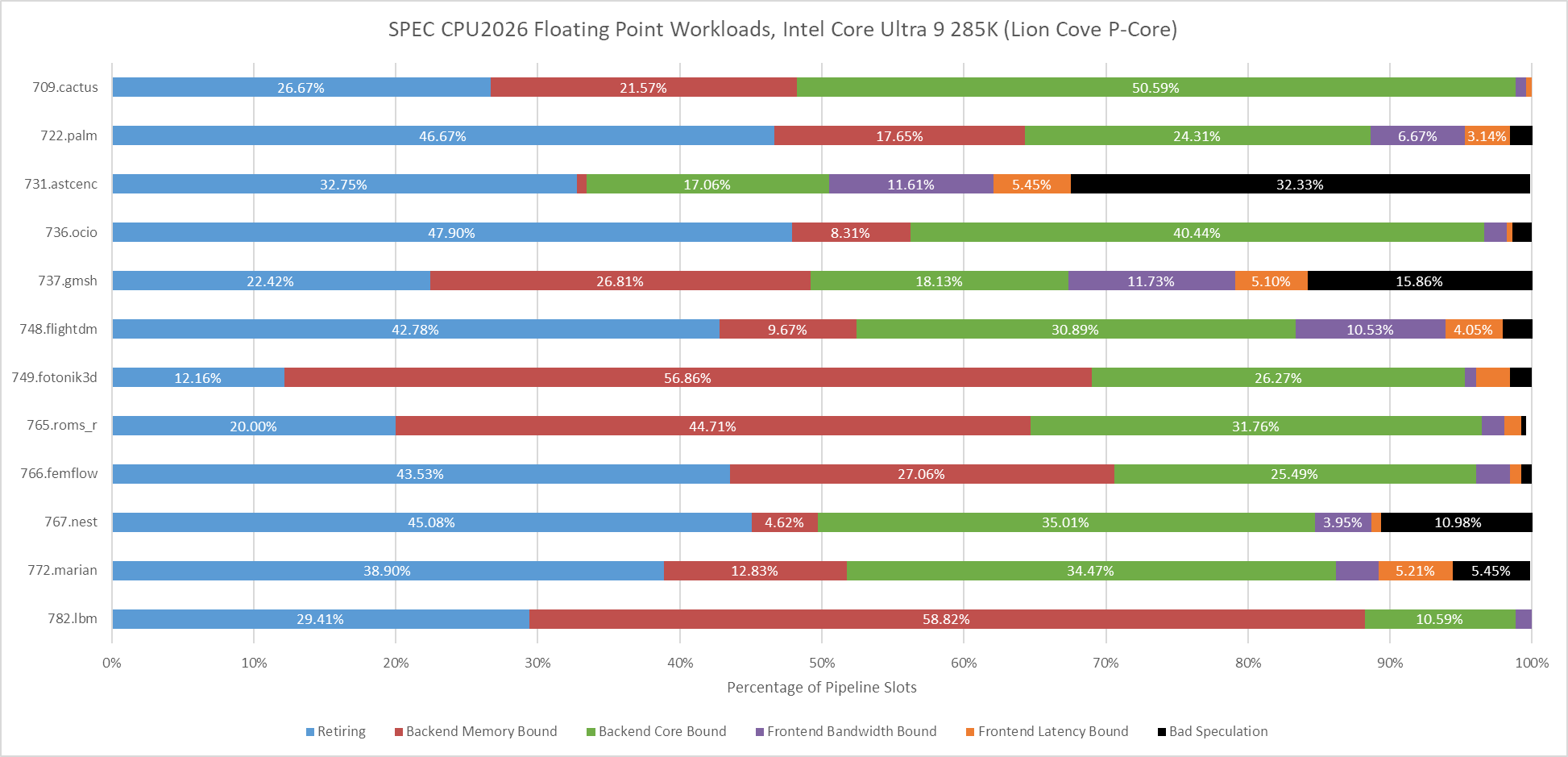
Lion Cove’s frontend has a field day in 709.cactus, but the core runs into backend limitations and overall Intel isn’t able to pull ahead of AMD.
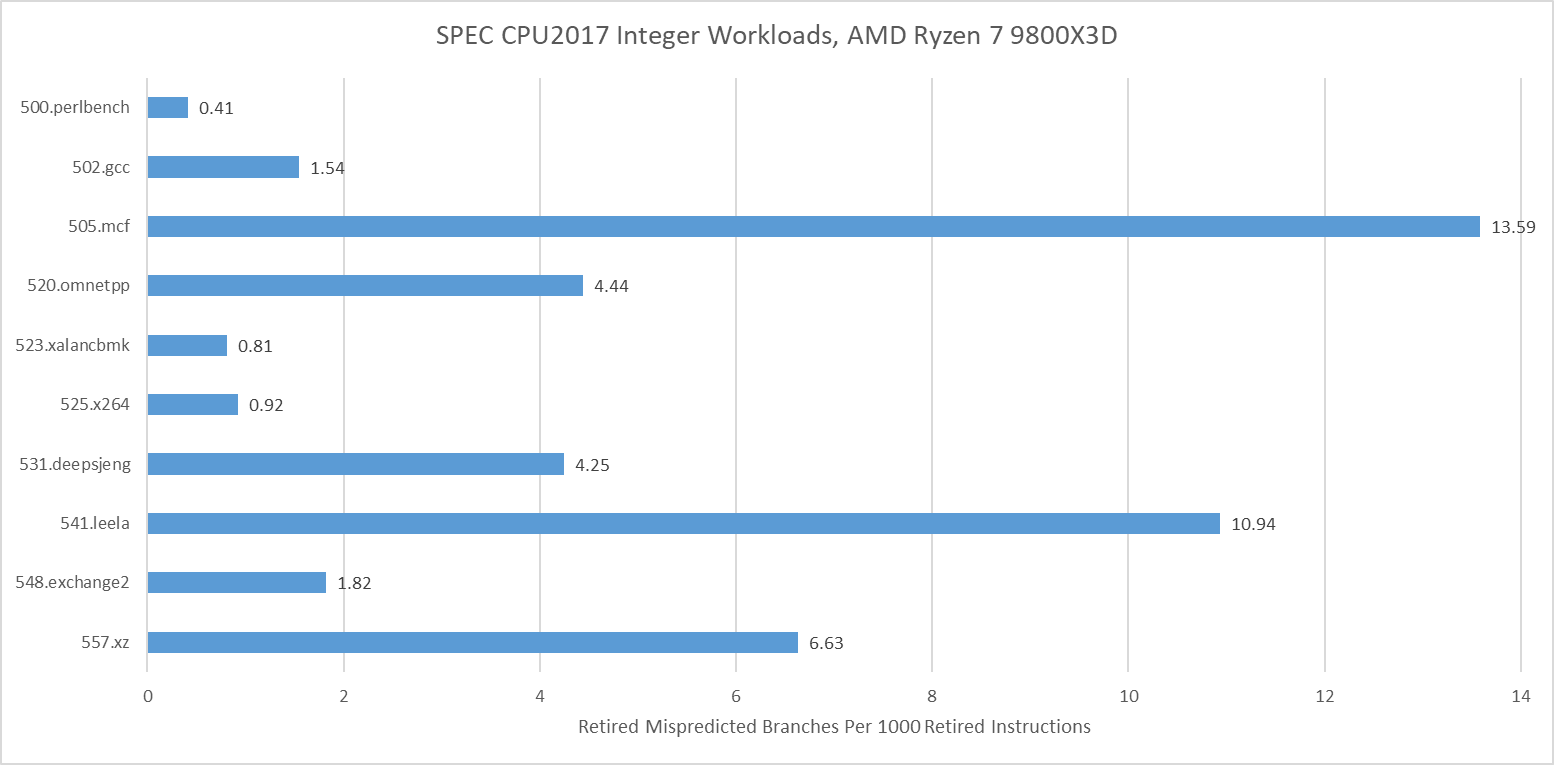
Branch prediction has been a key challenge in designing high performance CPUs for decades. SPEC CPU2017’s integer tests were often challenging from a branch prediction perspective, even for modern cores with sophisticated branch predictors. 505.mcf, 541.leela, and 557.xz all suffer plenty of mispredicts on AMD’s Zen 5. Those tests would reward CPUs with better branch prediction, faster branch resolution, and the ability to hide mispredict penalties behind other work.
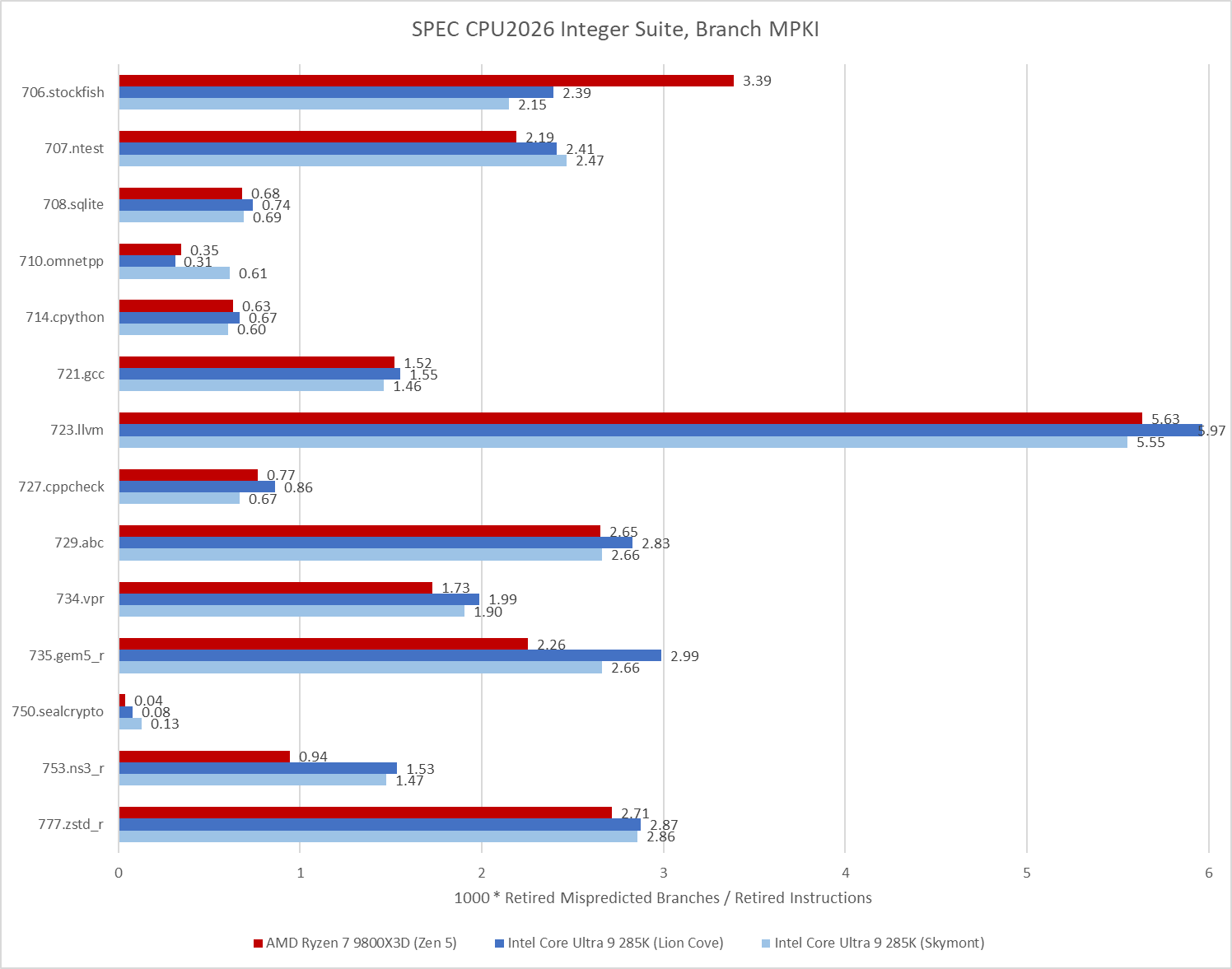
SPEC CPU2026’s integer suite places less emphasis on branch prediction. 721.llvm remains a moderate challenge, but suffers fewer mispredicts per instruction than 557.xz, to say nothing of 505.mcf and 541.leela. Lower difficulty on the branch prediction side contributes to higher IPC averages.
Floating point workloads in SPEC CPU2017 tend to be less challenging for branch predictors, though not always. 526.blender did lose throughput to bad speculation, but SPEC CPU2017’s floating point tests didn’t get close to 557.xz, 505.mcf, or 541.leela in terms of branch prediction difficulty.
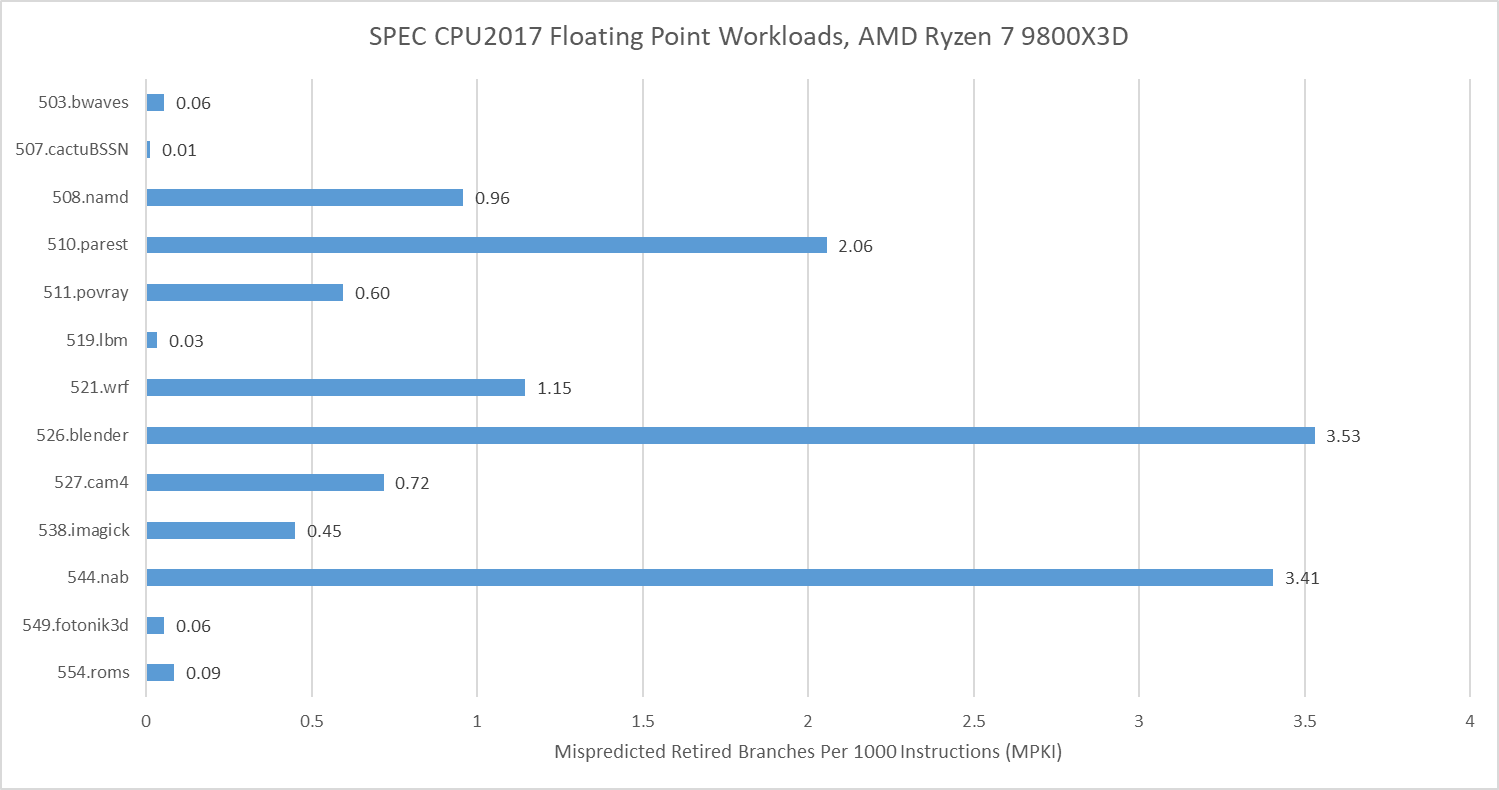
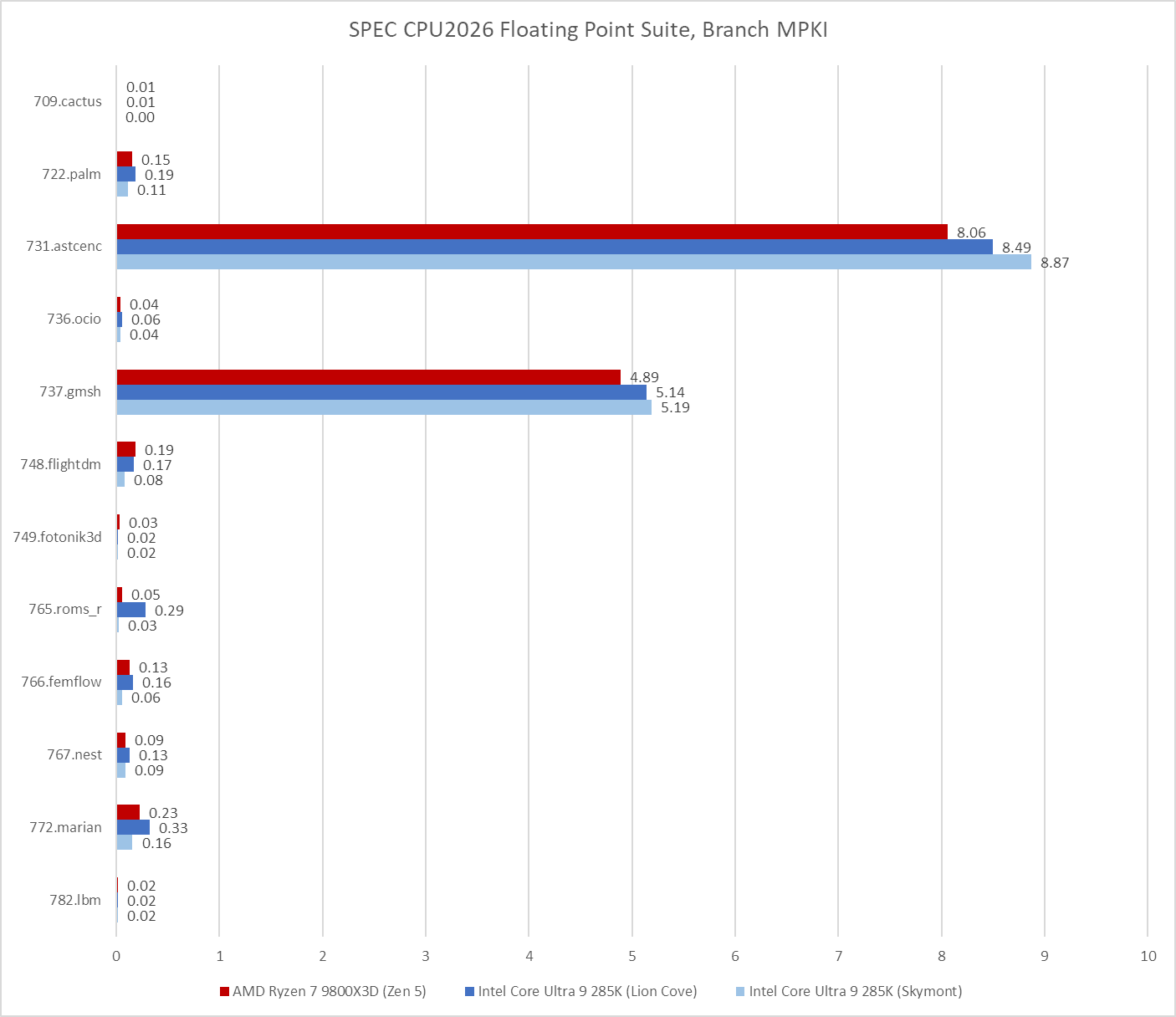
SPEC CPU2026 moves the needle on that, with 731.astcenc stepping up as the single biggest branch prediction challenge across both the integer and floating point suites. It’s still not as big of a challenge as 505.mcf from SPEC CPU2017’s integer suite, but it should still suffice to represent a workload with unpredictable control flow.
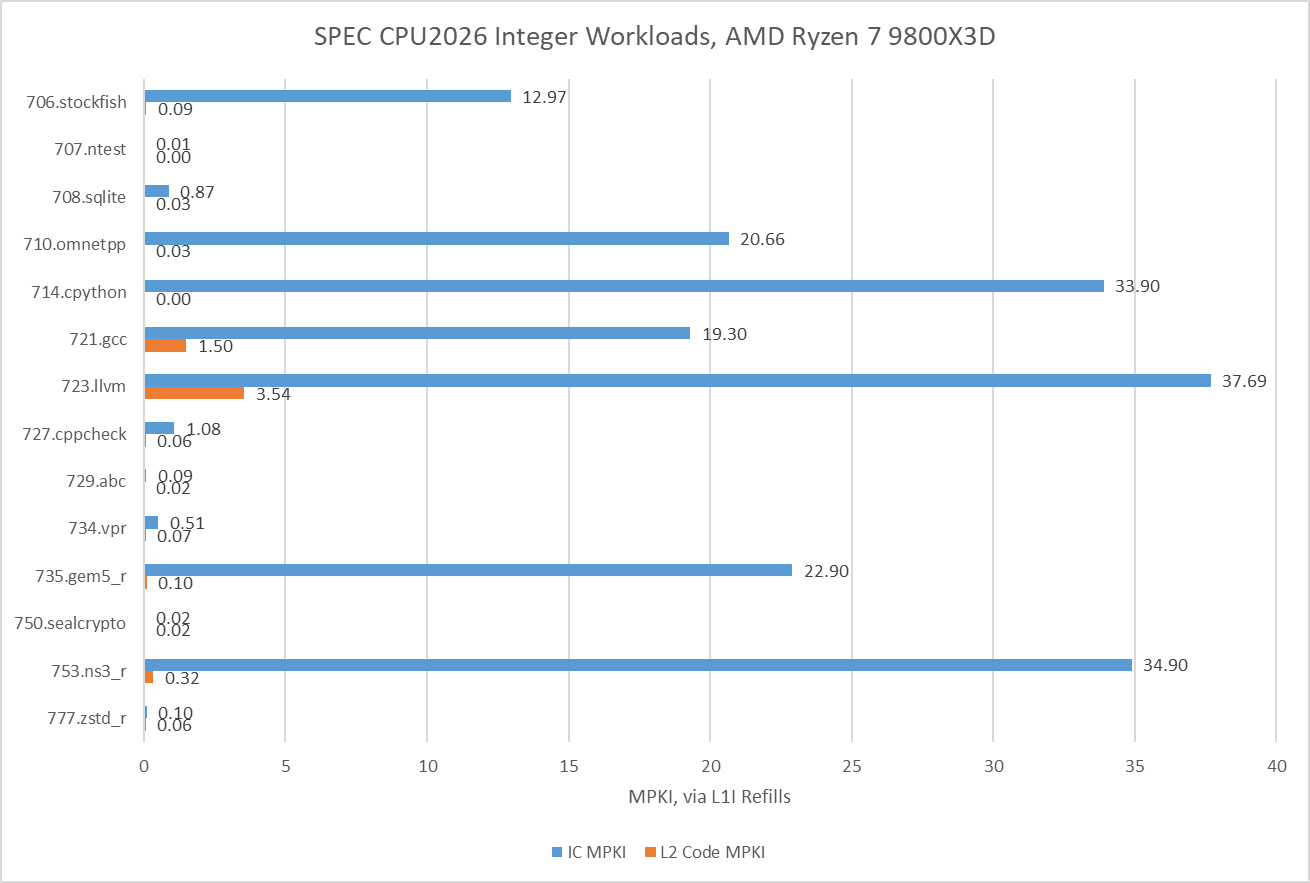
Good caching is important for instructions as well as data. AMD’s recent cores lean towards optimizing for small instruction footprints, and seek to capture much of the instruction stream in a highly optimized micro-op cache. SPEC CPU2026’s integer suite challenges that approach more than SPEC CPU2017’s did. Several workloads have less than 80% op cache coverage, so it appears that SPEC’s move to workloads with more source code lines sometimes correlates with worse code locality. Still, Zen 5 is able to mostly run code out of its op cache, and the decoders don’t see much use.
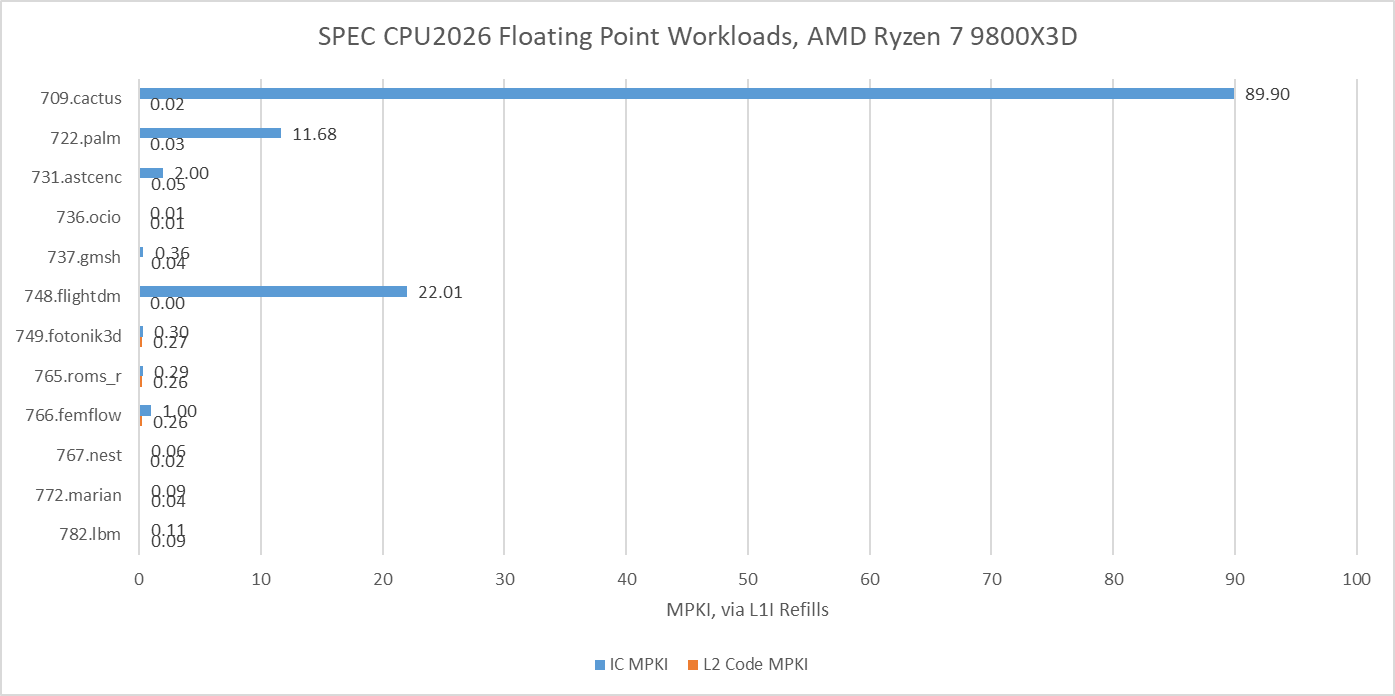
Further down the cache hierarchy, many of the tests with less than 90% op cache coverage see significant L1 instruction cache misses too. AMD has stuck with a 32 KB L1 instruction cache ever since Zen 2 which doesn’t offer too much extra coverage over the op cache. In nearly all tests, the 1 MB L2 cache is enough to capture the vast majority of L1 instruction cache misses. Only the two code compilation workloads see a noticeable degree of code fetches that miss L2, which could contribute to their lower IPC.
Intel takes a different frontend approach, with a smaller 5.2K entry op cache backed by a larger 64 KB instruction cache. Intel also uses a 8-wide decoder, which can provide higher instruction bandwidth to a single thread for large code footprints than AMD’s 4-wide, per-thread decoders. Lion Cove’s larger instruction cache suffers fewer misses across the board, and nearly eliminates code fetches from L2 in 714.cpython and 706.stockfish. Where the L1 instruction cache does see a significant number of misses, Lion Cove’s huge 3 MB L2 is able to step in and largely prevents code fetches from going through to L3.
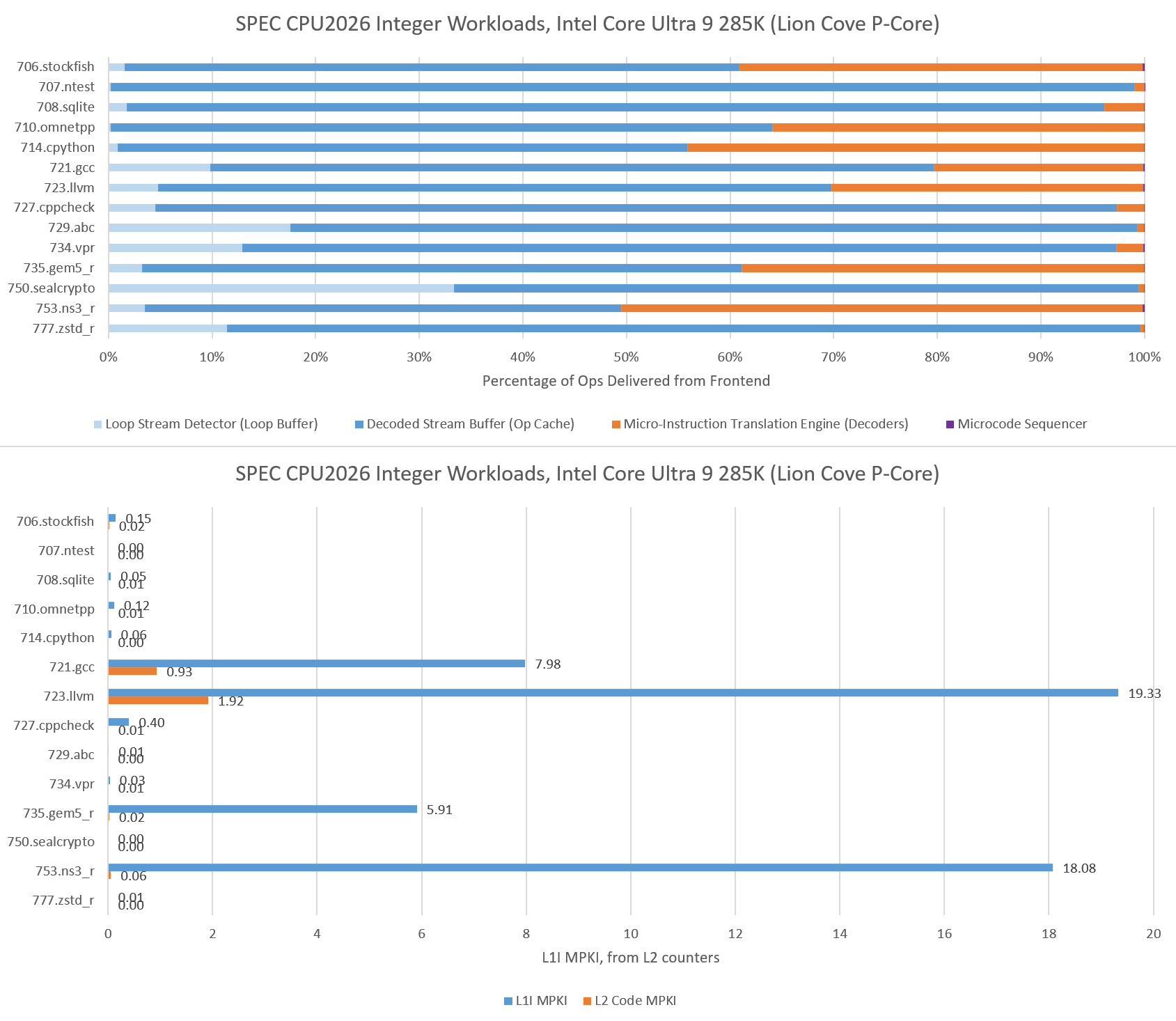
For very small code footprints, Intel has a Loop Stream Detector that locks down the micro-op queue and uses it as a loop buffer. The LSD plays a minor role in most integer tests, except for 750.sealcrypto.
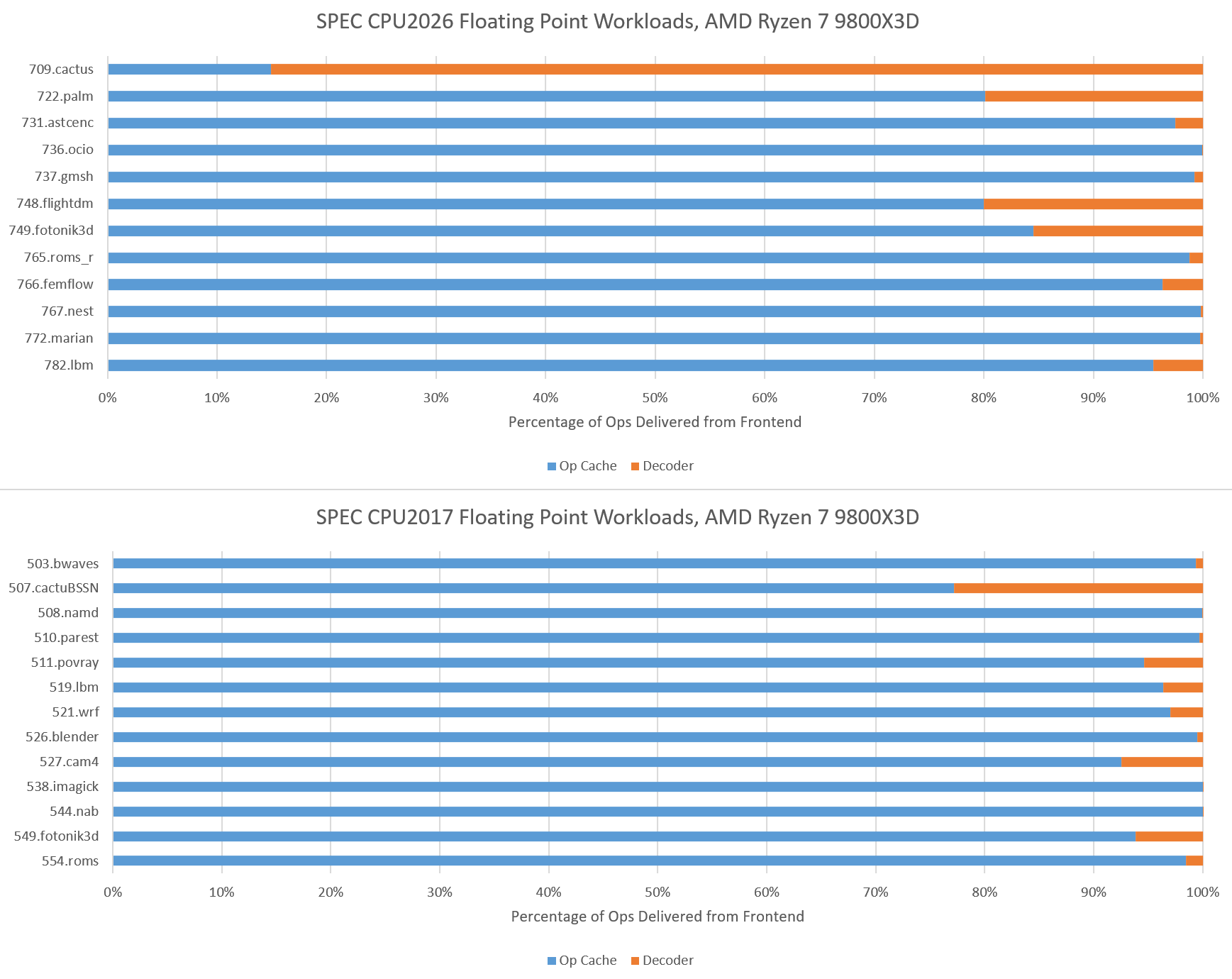
SPEC CPU2017’s floating point suite tended to be core throughput focused, with smaller instruction footprints than their integer counterparts, with exceptions of course. SPEC CPU2026’s updated floating point suite has more of those exceptions, and tougher ones too. 709.cactus has Zen 5 mostly feeding itself from its decoders, which explains why top-down metrics showed it as being frontend bandwidth bound. As with the integer suite, tests with lower op cache coverage tend to also miss in L1i. 749.fotonik3d doesn’t though. It spills out of the op cache more than its identically named predecessor in SPEC CPU2017, but all of that is caught by Zen 5’s L1 instruction cache.
LSD data from Lion Cove shows that many floating point tests spend a lot of runtime in tiny loops. 722.palm is a funny case, with Lion Cove’s 192 entry micro-op queue achieving over 40% coverage. Then once it gets out of that loop, it has a good chance of missing the op cache and the 64 KB L1 instruction cache.
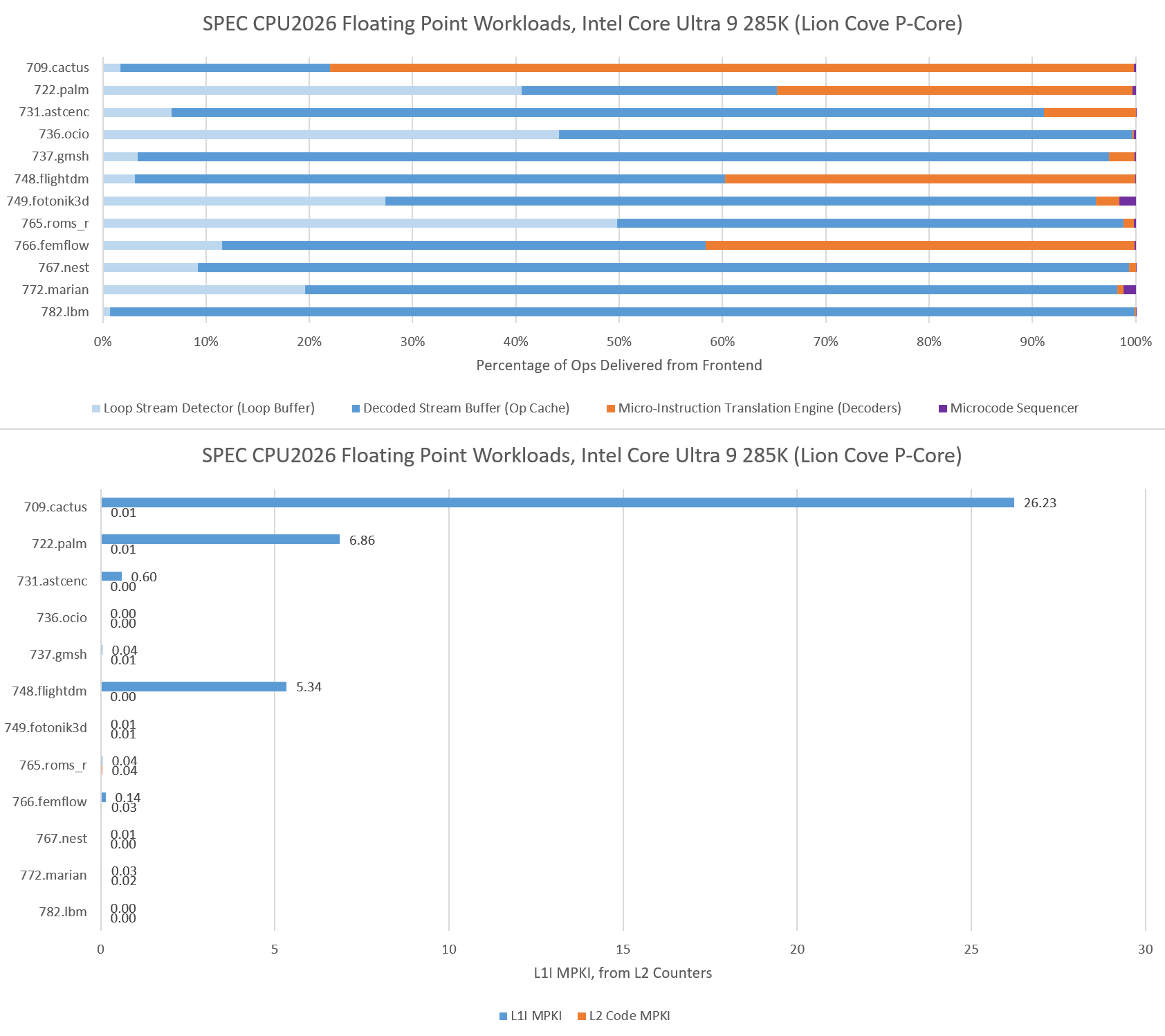
None of the floating point workloads presents enough of a challenge on the code footprint side to spill out of L2.
Data accesses that miss cache present another performance limiter for modern CPUs, especially for PC games. SPEC CPU2026’s integer suite has plenty of workloads that often miss in a 48 KB first level cache, and many that challenge a 1 MB L2 as well. However, the integer suite is light on workloads that encounter last level cache demand misses.
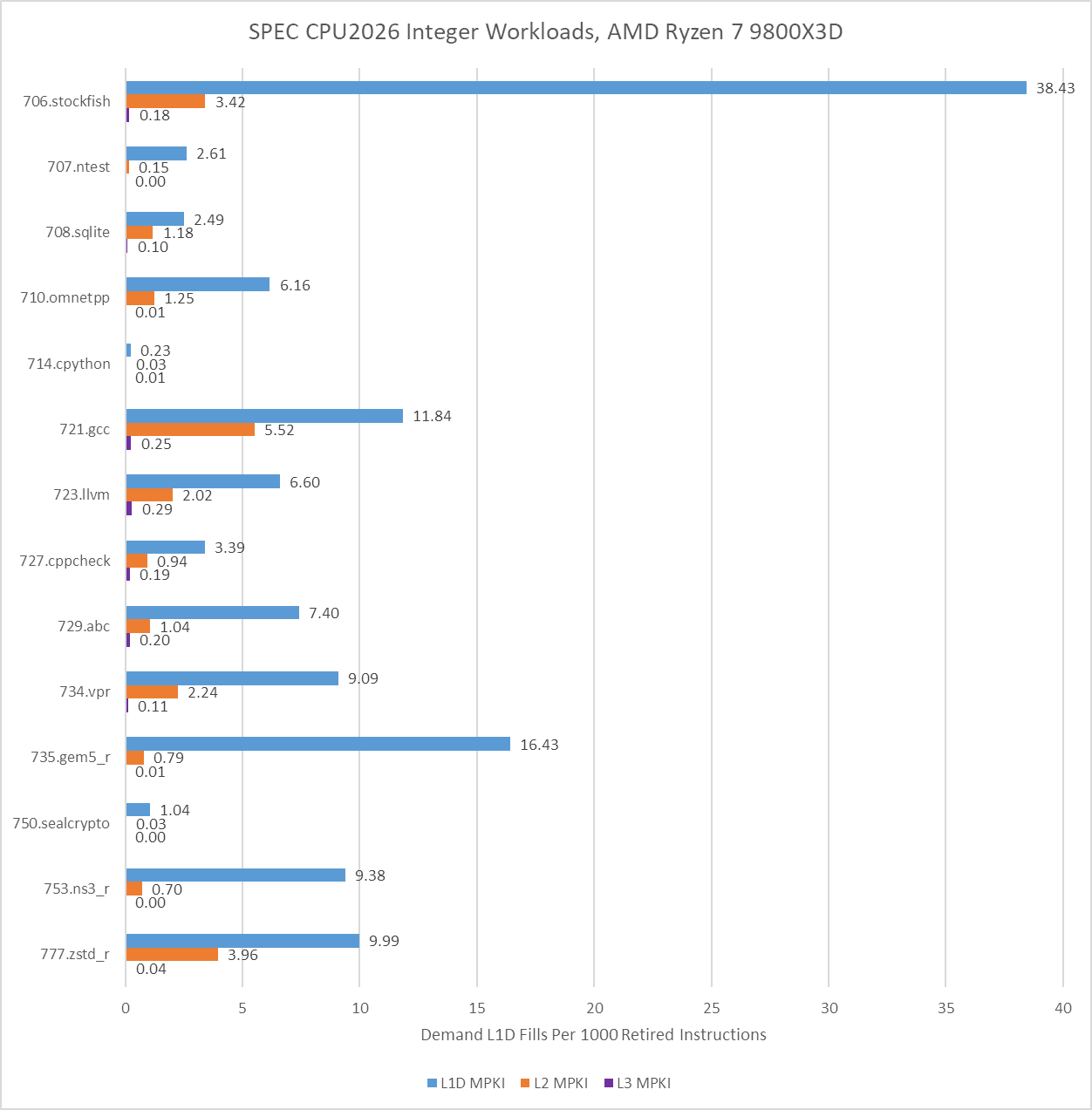
714.cpython and 750.sealcrypto rarely miss even in Zen 5’s L1D cache, which explains their high IPC alongside other factors.
Lion Cove performance counter data does a good job of justifying its 192 KB L1.5 data cache. As it turns out, quite a few workloads with significant L1D misses have nearly all of those misses contained within 192 KB. Last level cache misses are rare, suggesting a 36 MB cache is sufficient for many of SPEC CPU2026’s integer workloads.
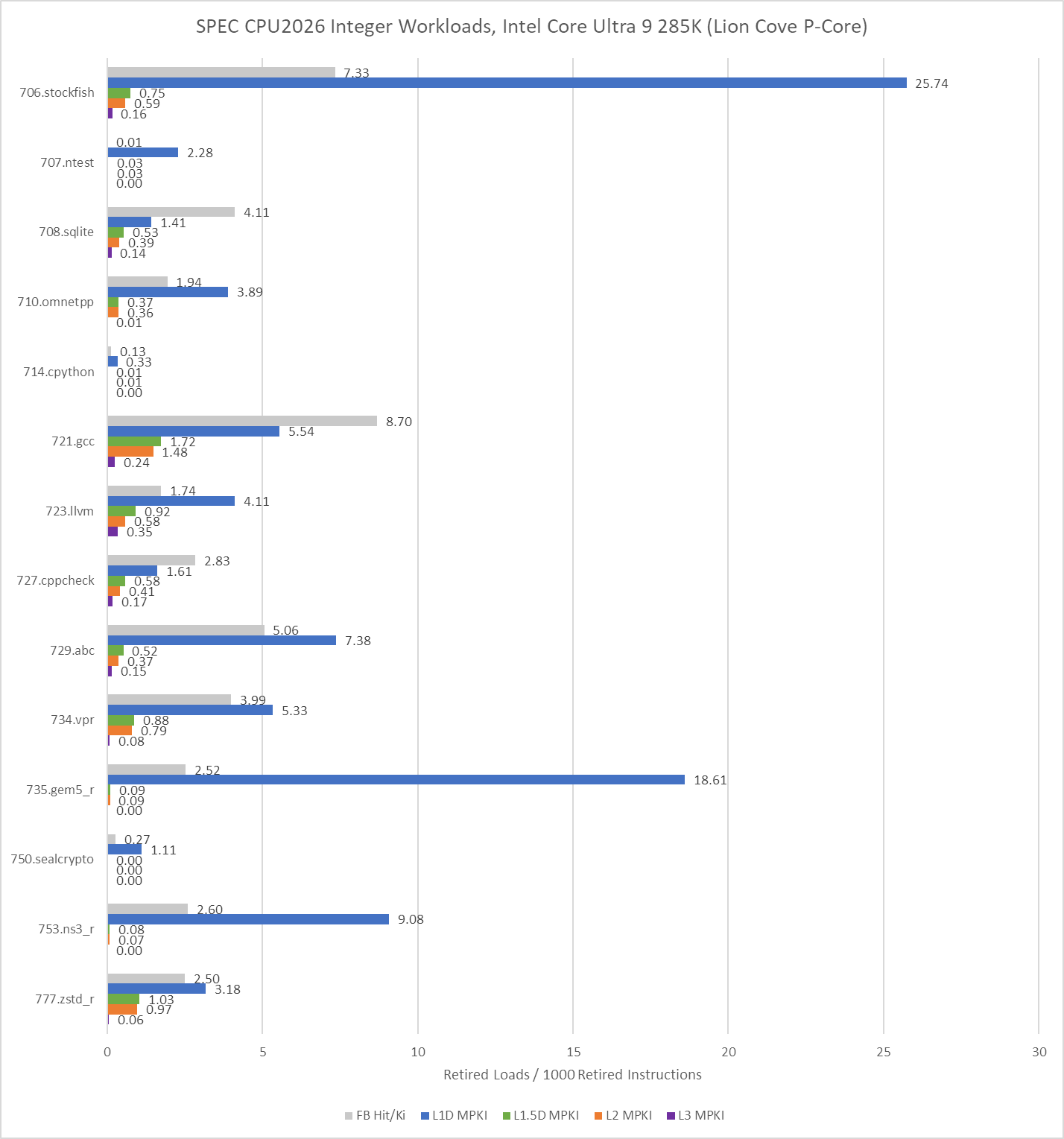
On the floating point side, 709.cactus is prickly for a 48 KB L1 data cache, but Zen 5’s larger caches do a good job of cleaning up the misses. AMD’s L2 and L3 caches do well in general across the floating point suite. Only 765.roms and 759.fotonik3d have significant last level cache miss activity.
L3 MPKI figures are lower on Intel, but those don’t tell the whole story. Intel’s performance counters limit counting to retired loads, which disregards accesses from any loads that are flushed. Performance counters on both AMD and Intel also only count the first miss to a cache line that initiates a refill request.
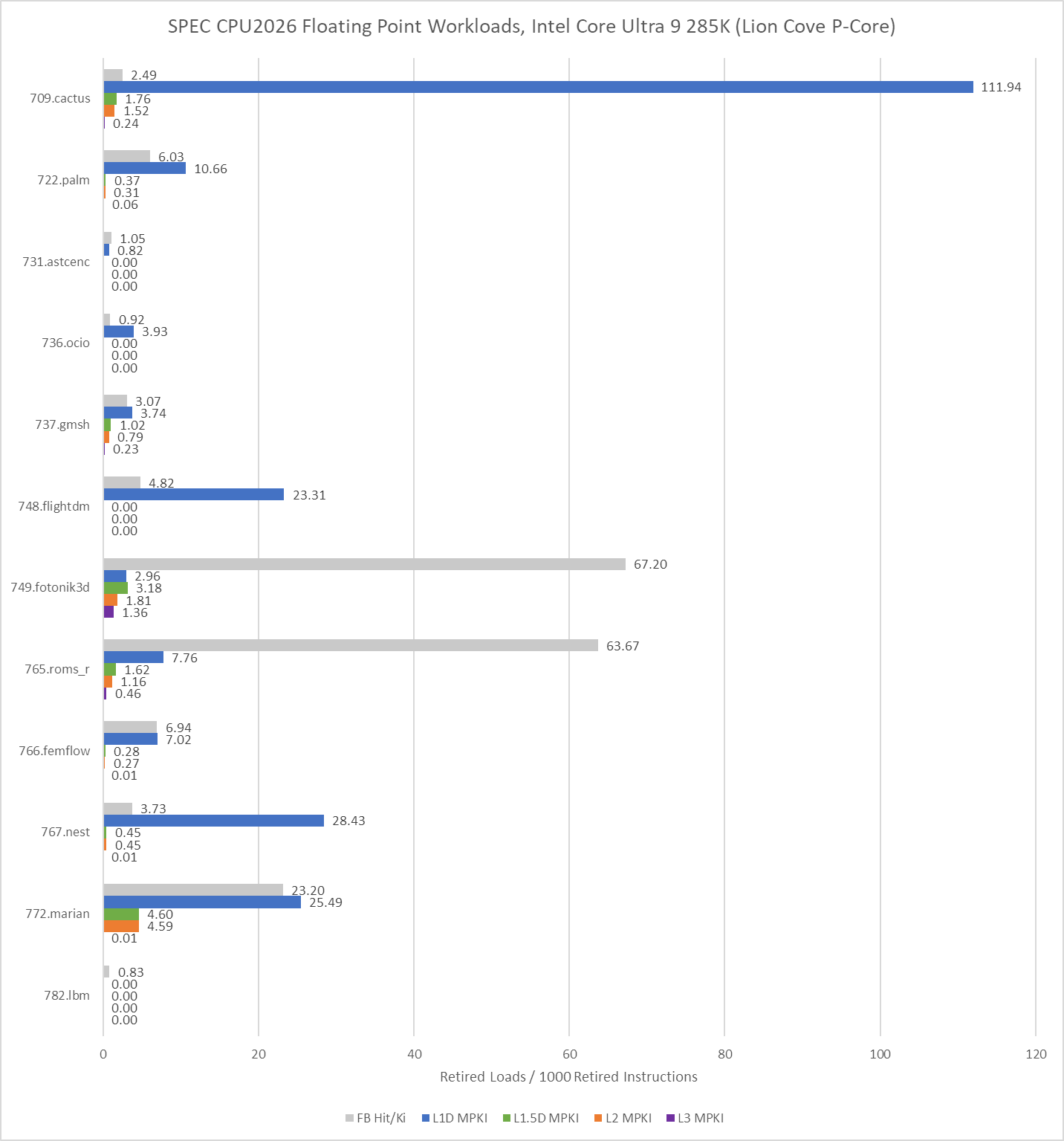
Intel’s performance counters can also account for Fill Buffer (FB) hits, which occur when a load asks for data from a cache line that already has an outstanding miss request. That can happen if data accesses have good spatial locality, and multiple instructions request data from the same cache line. FB hits can also happen if the prefetcher initiates a cache refill request before an instruction asks for it, but data hasn’t arrived yet when an instruction does make the request. I suspect 749.fotonik3d and 765.roms run into a combination of both. They have a lot of FB hits, but few instructions cause a fresh L3 miss. I suspect many instructions matched an existing miss request started by the prefetchers.
SPEC CPU2026 is a very different animal compared to its predecessor. The new suite has more variety on the code footprint side, with more tests that spill out of op caches and L1 instruction caches. On the other hand, branch prediction and data-side footprint have less variety. Few tests spill out of last level caches on AMD and Intel’s latest consumer chips, except for a couple of floating point workloads. I’m disappointed to see 520.omnetpp leave the room, because its behavior was the closest match across SPEC CPU2017 for gaming workloads.
Overall, those changes mean SPEC CPU2026 focuses more on core throughput than its predecessor. Larger instruction-side footprints do little to change that, because lowered branch prediction difficulties mean modern cores can smoothly stream code from their L2 caches. High IPC workloads certainly do exist, but it would have been nice if the newer suite improved coverage for lower IPC workloads too. Retaining an application like 520.omnetpp would have been nice. Instead, I feel like SPEC CPU2026 augments SPEC CPU2017’s coverage rather than being a perfect replacement.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。