在上一篇文章DeepWIKI 是如何工作的我分享了 DeepWIKI 可能的实现方式。文中留了一个问题:DeepWIKI 是如何将源代码仓库分块的?
这个问题的答案就是 AST 分块。
这篇文章我想分析一下两个软件开发辅助工具(Cursor, Cline)都是怎么实现「索引代码」的,其实它们和 DeepWIKI 的原理没有本质区别,都使用了 AST 分块的方法。
Abstract Syntax Tree(AST,抽象语法树)是源代码的树形表示,它反映了代码的语法结构。在代码分块时,AST 可以帮助我们更好地理解代码的语义边界。
AST 在各种编译、分析源代码工具中都广泛使用。例如前端的 Babel、TypeScript 编译器(TSC),就利用 AST 来将 es6 或者 TypeScript 代码转换成浏览器可理解的 js 代码。
下面是一个简单的例子,展示 AST 如何把 TypeScript 代码转换成树形结构,假设有一段 TypeScript 函数:
function greet(name: string) {
return "Hello, " + name;
}
经过 AST 工具的转换,它被抽象成下面的语法树结构:
后续编译器就可以遍历这个语法树,按节点转换成 Javascript 代码。
理解了 AST,就大致可以理解 DeepWIKI、甚至是 Cursor 这种代码编辑器如何构建代码索引的。
在Cursor 的官方文档中,可以看到关于它如何索引用户代码的相关描述。
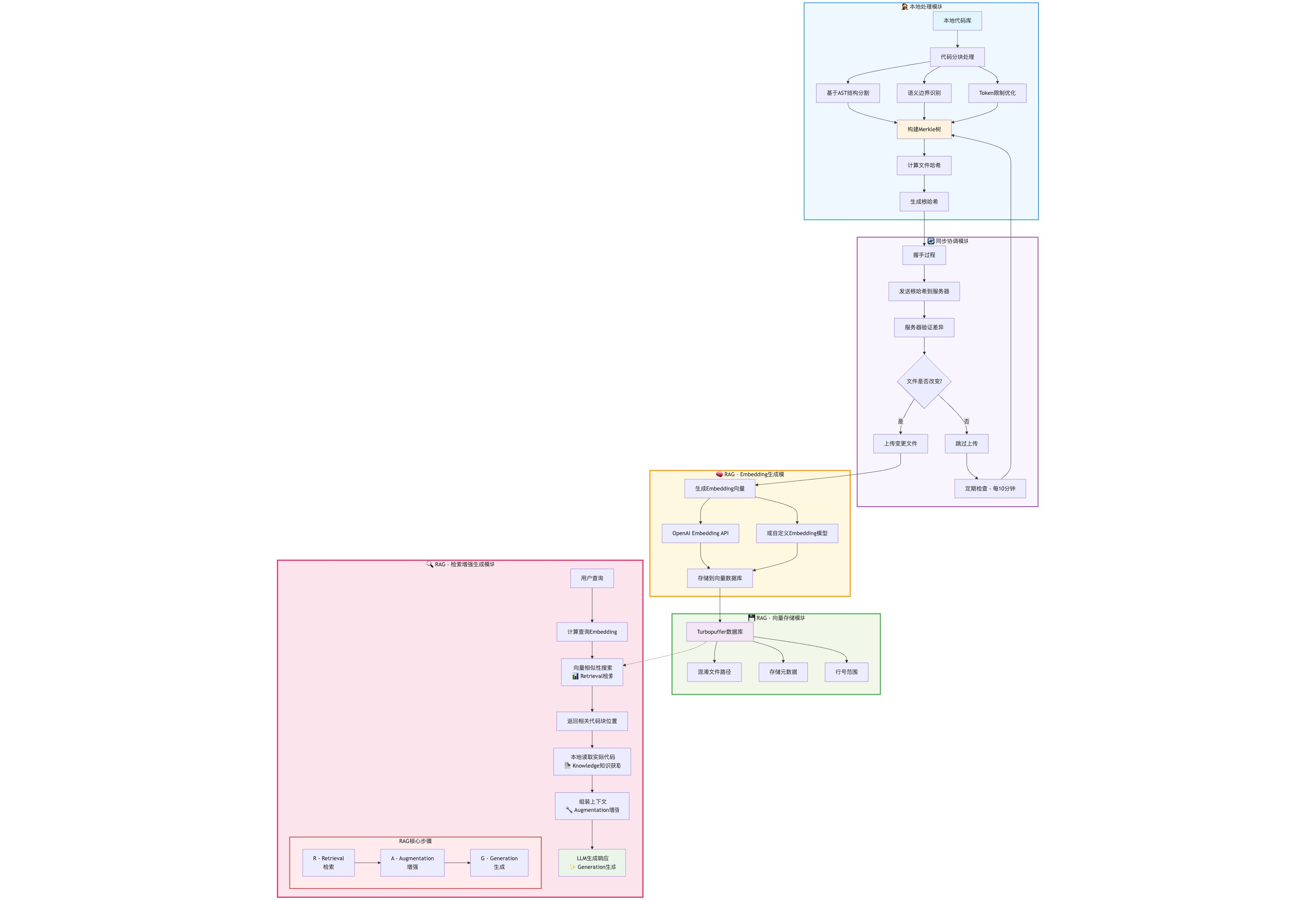
Cursor 会扫描用户代码仓库,计算文件哈希值并构建 Merkle 树,类似 Git 比较文件差异的原理,Cursor 用 Merkle 树来比较用户空间文件的差异,并且将用户修改过的文件以增量的方式上传到 Cursor 的服务器。
被上传的文件,会被分块并嵌入,存储在 Turbopuffer 数据库中。这就是将源代码构建成 RAG 的过程。
这里的分块使用了 AST 工具将代码先结构化成语法树,然后将序列化后的语法树节点切成小块,最后嵌入成向量存储起来。
Turbopuffer 中不仅存储了向量化后的代码,而且存储了一些元信息,如这段代码的行号,源文件路径等。
当 Cursor 试图补全用户代码或根据上下文生成新代码时,Cursor 会检索这个 Turbopuffer 数据库,匹配到相似度最高的向量并得到这段代码的文件路径、行号。之后 Cursor 在用户代码仓库中查找到对应的源代码并放入 LLM 的系统上下文里。最后 LLM 返回生成的新代码给 Cursor。
有网友整理了这张流程图:
Cline 的官方博客 可以让我们窥见它的实现思路。
Cline 是一个辅助编码的 AI Agent。Cline 并不上传代码并构建 RAG,而是主张更安全、可靠的方式管理用户的代码仓库。
下面是开发者对 Cline 原理的介绍:
When you point Cline at a codebase, it doesn’t immediately try to read every file. Instead, it begins by understanding the architecture. Using Abstract Syntax Trees (ASTs), Cline extracts a high-level map of your code – the classes, functions, methods, and their relationships. This happens through our list_code_definition_names tool, which provides structural understanding without requiring full implementation details.
Cline 会使用它们的 list_code_definition_names工具将源代码转换成 AST。Cline 把这个 AST 当作整个源代码的「地图」。
当 Cline 自动执行任务时,它会分析当前要修改的文件,从文件构建 AST,从 AST 生成自然语言上下文(类似 DeepWIKI 把代码转换成文档)。并将上下文传给 LLM,让 LLM 决定下一步是该修改文件,还是需要查看另一个文件补充更多上下文。
如果说 Cursor 比较的是向量空间代码片段的相似度,Cline 就是将代码片段转换成自然语言的描述,然后让 LLM 通过语义的理解,在源代码仓库中搜寻线索,比较代码片段之间的语义相似度。
Cline 这种实现方式,显然更安全,企业用户不用担心 Cline 滥用源代码。但是副作用就是消耗了更多 Token。不断在不同文件之间获取上下文也花费更多时间。对于一些特殊情况,它甚至会在两个文件之间循环跳转,陷入死循环。
从我自身感受来说,Cline 在一些模型(Deepseek-r1, OpenAI-4o)的表现上比 Cursor 的 Agent 模式更好,因为 Cline 的语义理解比向量相似度更充分利用这些模型的自然语言能力。
但是对于专门为编程优化过的 Claude-Sonnet,则没有明显差异,这时就要看用户希望更高的安全性还是更快的响应速度。
本文主要介绍了代码编辑器如何利用抽象语法树(AST)来构建代码索引和实现代码补全功能。
总的来说,AST 是理解代码语法结构的重要工具,不同的实现方式各有优劣。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。