GitHub - jina-ai/submodular-optimization: Submodular optimization for context engineering: query fan-out, text selection, passage reranking
Submodular optimization for context engineering: query fan-out, text selection, passage reranking - jina-ai/submodular-optimization
 GitHubjina-ai
GitHubjina-ai
After my previous article on submodular optimization for fan-out queries in DeepResearch, I received great feedback asking for a deeper dive into submodularity especially in information retrieval and agentic search. Today, I'll introduce two more applications of submodular optimization: text selection and passage reranking. Both tackle the same core challenge—optimal subset selection—that every DeepResearch-like system must solve.
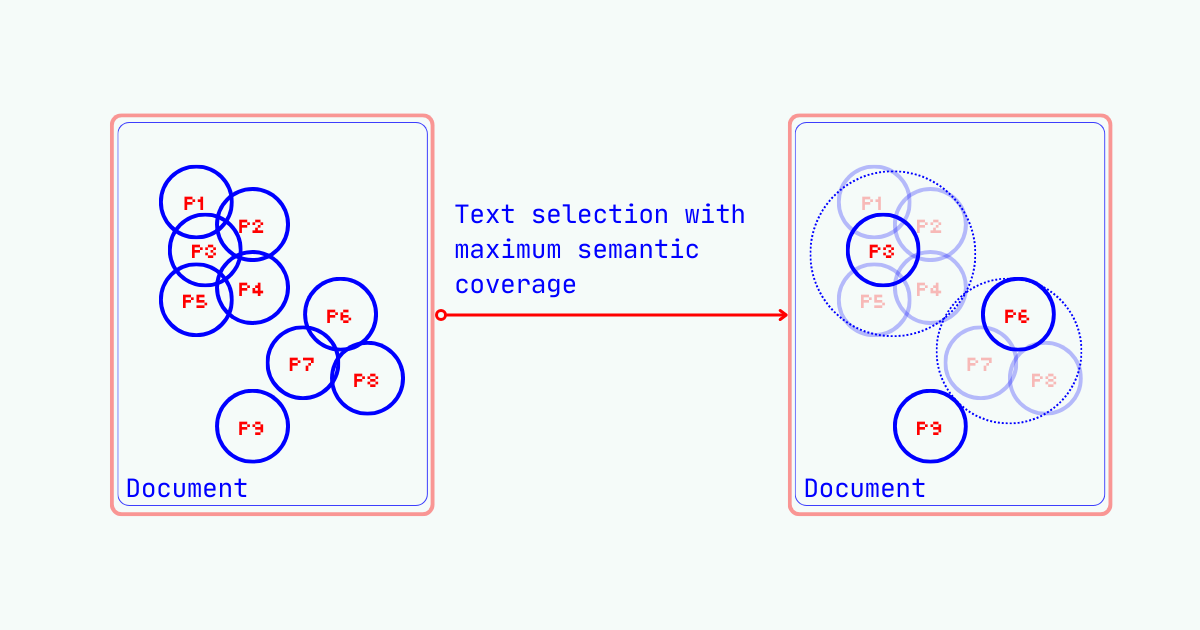
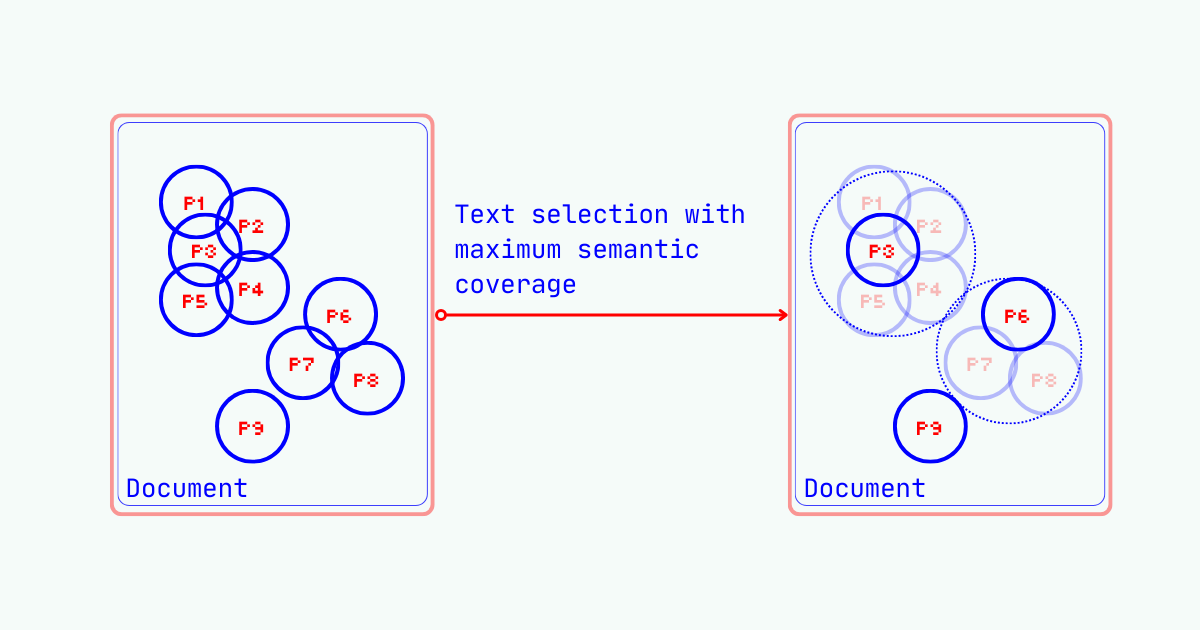
Real-world documents contain semantic redundancy – not every sentence carries equal importance for an LLM's reasoning. Imagine you have a lengthy document and need to extract the most representative information while staying within a token limit. This is text selection: choosing content that captures the document's essence under cardinality constraints. We want selections that are orthogonal to each other—minimizing shared information while maximizing total coverage. This applies at multiple levels: selecting sentences from documents, or tokens from sentences. One can also think of text selection as context optimization or compression. We reduce LLM token consumption while preserving the semantic richness needed for reasoning.
Passage reranking sorts candidate passages by their semantic relevance to a user query. At Jina AI, we've built specialized rerankers for this (jina-reranker-m0, jina-reranker-v2-multilingual-base), though our embedding models can also solve the problem. But here's the limitation: most rerankers—ours included—work in pointwise fashion. They score individual (query, document) pairs independently. They don't consider the shared information between passages: if passage 1 and passage 3 both score high but contain mostly identical information, wouldn't selecting just one of them be enough?
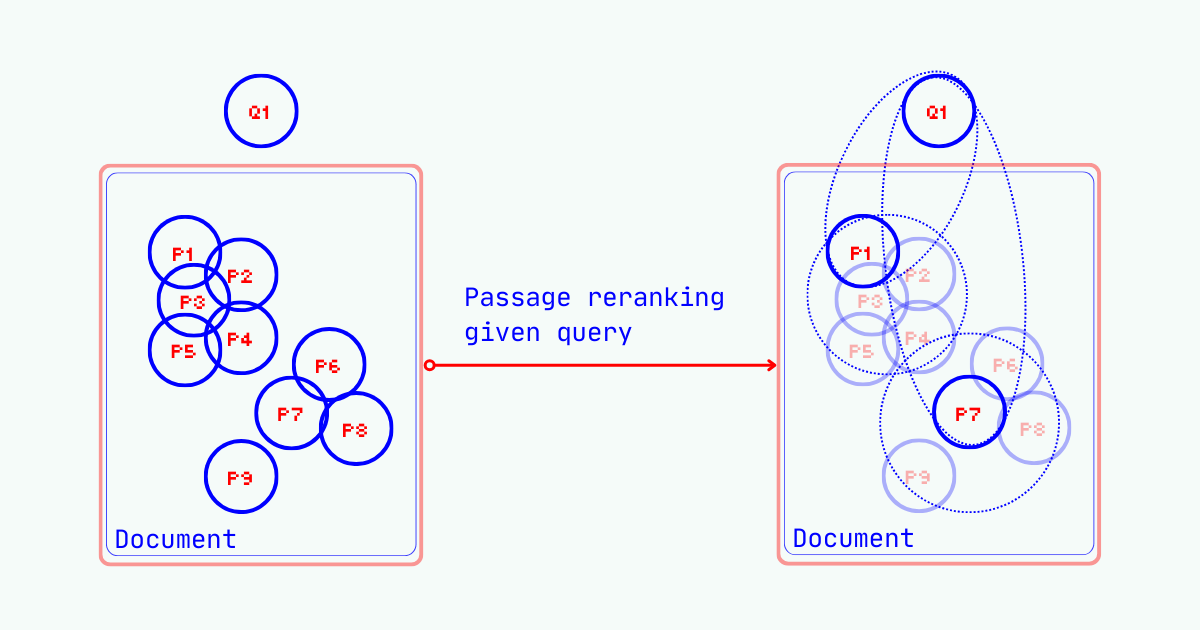
In DeepResearch, this becomes crucial. When agents call search tools and collect web snippets, we must determine which snippets deserve precious context window space for the next reasoning step. The selection follows the same "minimize overlap, maximize coverage" principle as text selection, but with an added objective—relevance to the original query must take priority.
Many researchers recognize the rising importance of context engineering, where we need to build, optimize, and "pack the context windows just right" (in Andrej Karpathy words) for building more effective agentic workflows. However, many just use LLM prompts to solve these problems "softly"—no guarantees, no theoretical foundation, questionable effectiveness. We can do much better.
In this article, I will show that both text selection and passage reranking yield to submodular optimization, which provides rigorous solutions. If you're unfamiliar with submodular functions, think "diminishing returns." We start with an empty set and incrementally add selected text or passages. Each addition provides value, but the marginal benefit decreases—capturing the intuition that diverse, non-redundant selections are most valuable. Formally, a function is submodular if for any sets and element :
This matches our intuition perfectly: we want selected elements to jointly cover the semantic space of the entire document, as we select more units, each new unit is less likely to cover previously uncovered semantic space.
Text Selection via Submodular Optimization
0:00
/1:04
First used jina-embeddings-v4's multi-vector feature to extract token-level embeddings from a passage, then applied submodular optimization to cherry-pick the tokens that provide the best coverage, finally call tokenizer and convert selections back to the strings at their org. positions. Think of it as a form of "compression"—you can adjust the top-k slider to dial in different "compress rates". Can you still make sense of the compressed text?
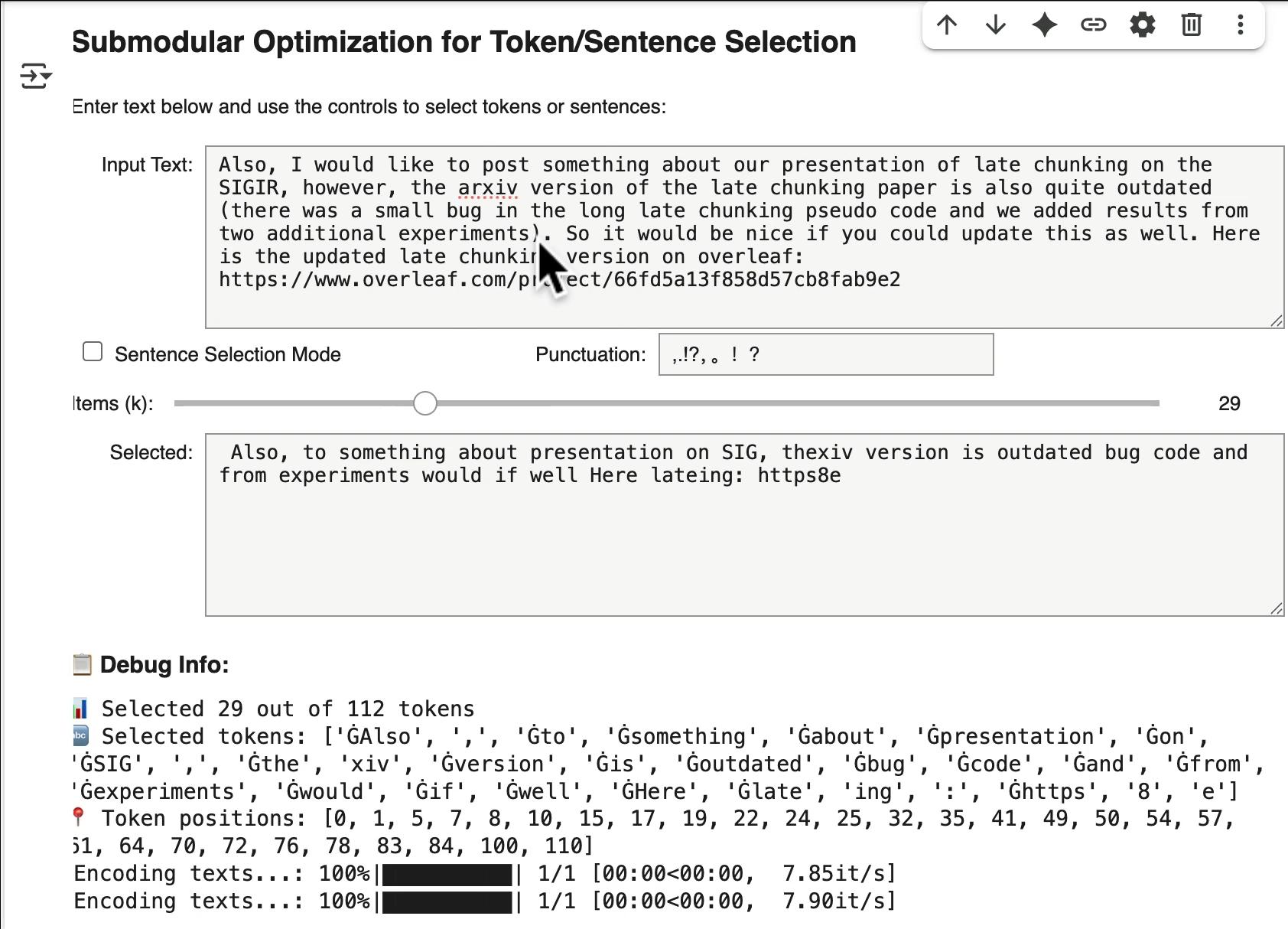
Google Colab


Implementation of text selection with submodular optimization.
Let's start with solving the text selection problem as it is essential for understanding submodularity and serves as a preliminary step for passage reranking. The problem is as follows:
Given a document with elements (tokens or sentences), we want to select a subset with that maximizes the coverage function:
where represents the cosine similarity between the embeddings of element and . Note, the coverage function is submodular because it satisfies the diminishing returns property. The max operation ensures we're measuring how well each element is represented by the closest selected unit, avoiding double-counting redundant information.
Get Token/Passage-Level Embeddings
For token-level selection, we leverage jina-embeddings-v4's new multi-vector embedding capability. Setting return_multivector=True returns one embedding per token, enabling our selection at the subword level.
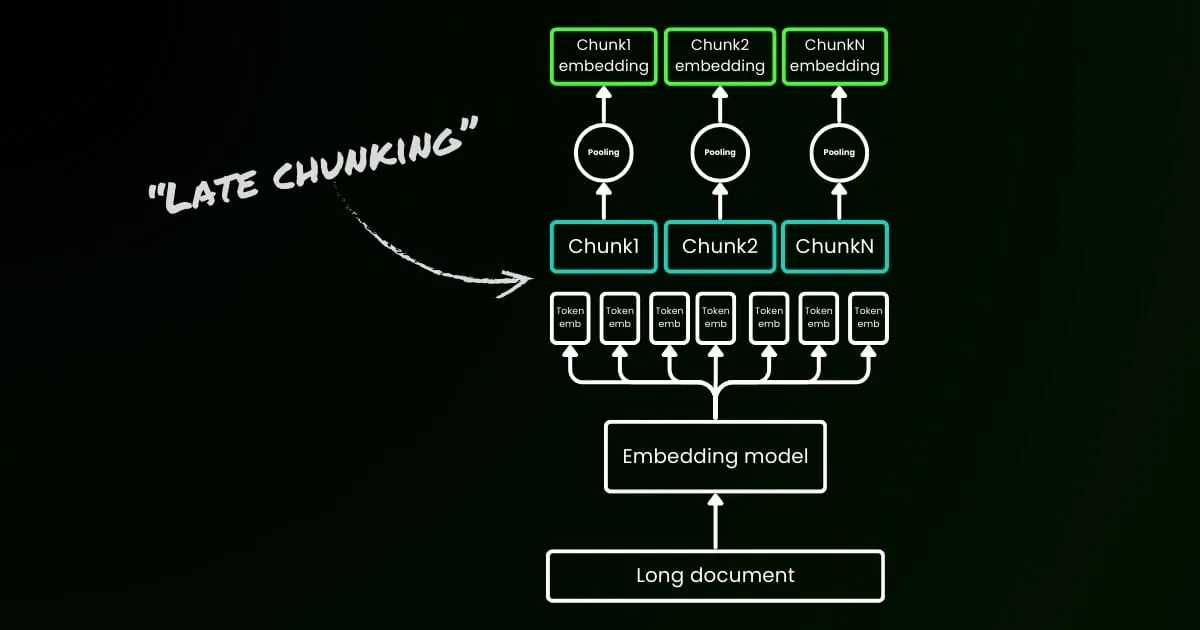
For passage-level selection, we just split documents by punctuation or newlines and embed each passage independently. Alternatively, one can also call our API with late chunking on to get contextual passage embeddings, which generally leads to better performance in downstream tasks.
Late Chunking in Long-Context Embedding Models
Chunking long documents while preserving contextual information is challenging. We introduce the “Late Chunking” that leverages long-context embedding models to generate contextual chunk embeddings for better retrieval applications.
 Jina AIMichael Günther, Han Xiao
Jina AIMichael Günther, Han Xiao
It's worth noting that since we're measuring semantic similarity within a homogeneous set of elements—all serving the same functional role rather than comparing heterogeneous elements like queries against documents (as we'll see in passage reranking)—we invoke jina-embeddings-v4 with the text-matching LoRA adapter enabled.
Jina Embeddings v4: Universal Embeddings for Multimodal Multilingual Retrieval
Jina Embeddings v4 is a 3.8 billion parameter universal embedding model for multimodal and multilingual retrieval that supports both single-vector and multi-vector embedding outputs.
 Jina AIJina AI
Jina AIJina AI

Since jina-embeddings-v3, our embedding models have been equipped with task-optimized LoRA. Read more about available LoRA in our v4 embeddings.
Lazy Greedy Algorithm
As in the previous article, we use the lazy greedy algorithm to solve the optimization problem. For monotone submodular functions, this algorithm achieves a approximation guarantee—a bound that is provably tight. The lazy greedy optimization exploits two fundamental properties of submodular functions: diminishing returns and the preservation of relative ordering between marginal gains across iterations. The algorithm works as follows:
- Initialization: Compute initial marginal gains for all elements and store them in a priority queue
- Lazy evaluation: At each iteration, extract the element with the highest cached gain
- Validation: If this element's gain was computed in the current iteration, select it immediately
- Recomputation: Otherwise, recompute its current marginal gain and reinsert into the queue
This lazy greedy algorithm dramatically reduces computational overhead, especially when marginal gains exhibit substantial variance across elements.
Passage Reranking via Submodular Optimization
Google Colab
The passage reranking task extends text selection by adding a new objective: the selected subset must be relevant to the given query. While text selection optimizes for pure diversity within a document, passage reranking must balance diversity against query relevance. Here are the key notations:
- is the selected subset of passage indices from the candidate set of passages—all content or memories in the DeepResearch system at a given step. represents the cherry-picked subset we want to carry forward to the next reasoning step. We have queries and candidate passages. In traditional search, , but in DeepResearch where queries are frequently rephrased and generated, we may have multiple queries at hand.
- is the similarity between passages and . This uses cosine similarity of jina-embeddings-v4 with task="text-matching" LoRA enabled for all passages as we did in text selection task.
- is the relevance score between query and passage . This is computed as the cosine similarity using jina-embeddings-v4 with
task="retrieval", prompt_name="query"for queries andtask="retrieval", prompt_name="passage"for passages, enabling the asymmetric retrieval LoRA and producing heterogeneous embeddings.
We can now formulate this using two different submodular functions, each capturing a distinct trade-off between relevance and diversity.
Facility Location Formulation
Each passage gets "covered" by its most similar selected passage, weighted by how relevant that selected passage is to each query. This formulation selects passages that are both query-relevant AND representative of many other passages.
The multiplicative interaction between query relevance () and passage similarity () creates "hubs"—passages that serve dual purposes as both relevant answers and diverse representatives. A highly relevant passage can cover many similar passages, while a less relevant passage provides coverage only if no better representative exists.
Saturated Coverage Formulation
For each passage, you receive credit equal to the minimum of its query relevance or how well it's covered by your best selected representative. This encourages selecting passages that can "saturate" the relevance of many other passages.
The min operation creates a relevance ceiling—you can't get more coverage credit than a passage's inherent relevance to the query. This formulation is more conservative, preventing over-selection of diverse but irrelevant passages.
Both functions are monotone and submodular, enabling the same lazy greedy algorithm with approximation guarantees.
Experimental Results
In our implementation, we use Jina Reader to fetch the plain text from our previous blog posts and evaluate different queries using passage reranking. I highly recommend that readers experiment with our Google Colab notebook using their own articles—content they're most familiar with will provide the most meaningful insights.
In our experiments, we select the top-10 passages from each document. Note that all three algorithms—query relevance only, facility location, and saturated coverage—exhibit the monotonicity: selecting a larger does not change the ranking of the first elements. For example, when comparing , , or , the top-9 passages remain identical across all values. The results are shown below.

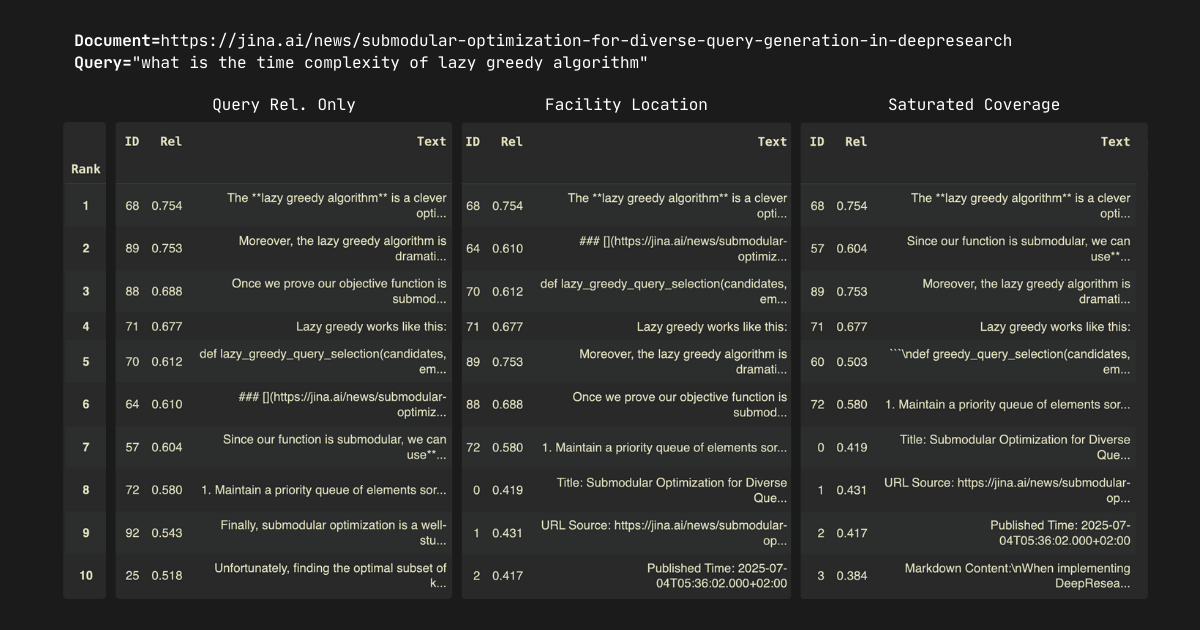
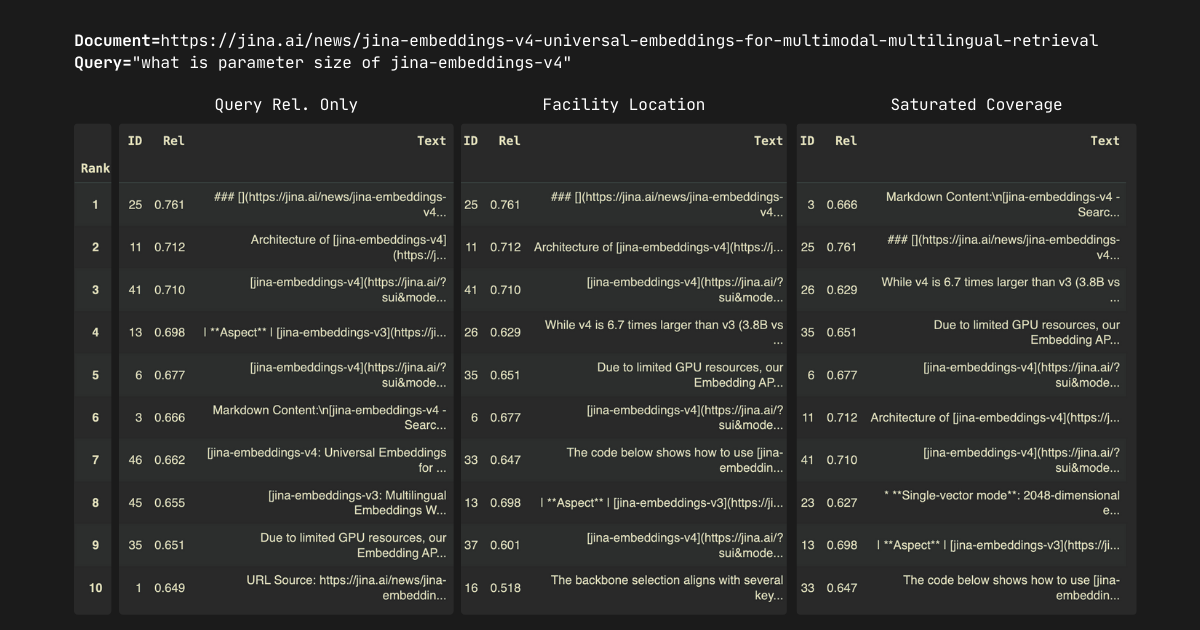
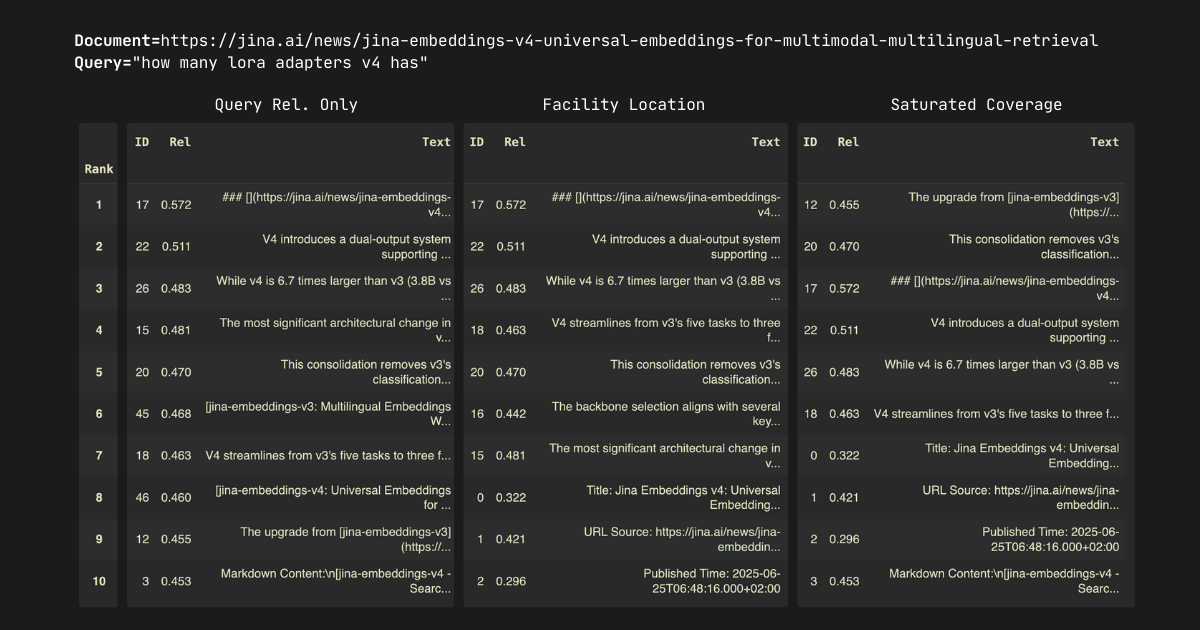
Here are some key observations. First, the submodular optimization algorithms loosely follow the query relevance scores but introduce strategic reorderings—passages "shift up and down" in rankings. This behavior aligns with our expectations since these algorithms optimize for redundancy minimization rather than pure relevance. The resulting rankings demonstrate strong quality.
Some readers may notice that in the first, second, and fourth examples, the submodular optimization results appear to "saturate" early, simply outputting ordered passages 0, 1, 2, etc. This isn't an algorithmic failure—it reveals one of submodular optimization's most valuable features that no existing rerankers are able to promise.
To better understand this "saturation" or "diminishing return" behavior, we plot the submodular function values for all possible set sizes from 1 to the maximum number of passages in the document. This reveals the diminishing returns property in action.
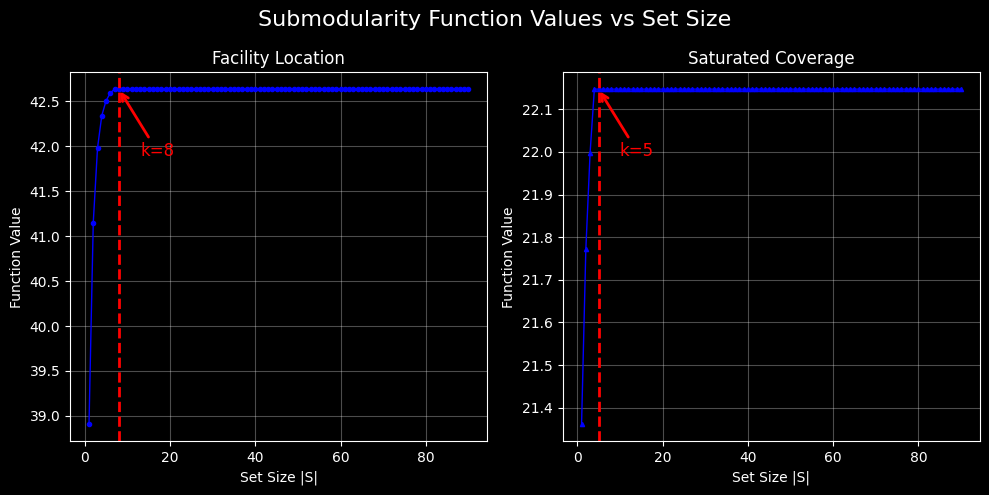
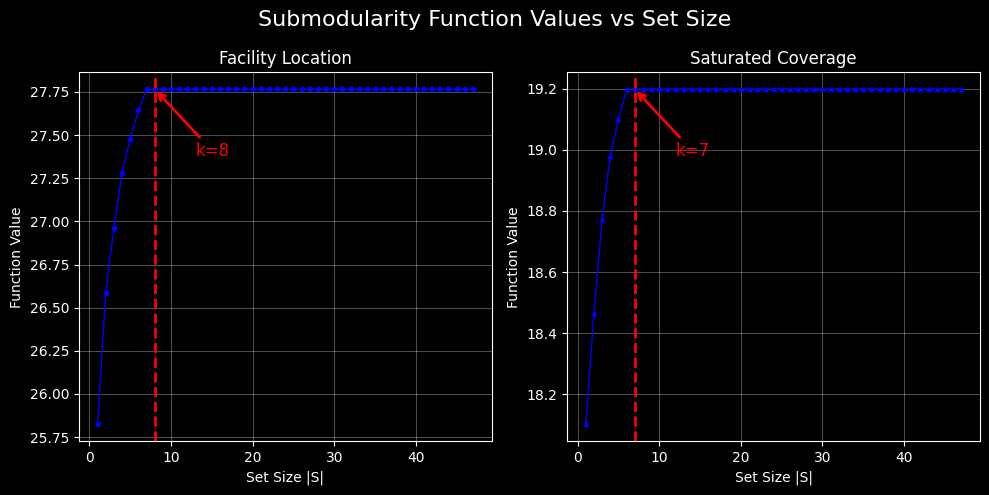
The plots above show how Facility Location and Saturated Coverage functions behave as we increase the selection size. Both exhibit the classic submodular pattern:
- Rapid initial growth: The steepest gains occur in the first few selections
- Diminishing returns: Each additional passage provides progressively less marginal benefit
- Saturation plateau: Function values flatten, indicating minimal benefit from further additions
Beyond these points, the marginal gains become negligible. This explains why our earlier ranking experiments showed sequential ordering (0, 1, 2, ...) - the algorithms correctly identified that additional passages contribute minimal value.
This behavior directly manifests the mathematical property of submodularity. The diminishing marginal gains we observe are not algorithmic artifacts but fundamental characteristics of the coverage functions. When the function value plateaus, we've reached the point where:
for all remaining passages .
Conclusions
Context engineering has emerged as a buzzword in AI, it's frequently hailed as a paradigm shift toward building agentic systems that curate the most relevant information to fill an LLM's context window, and this often starts with retrieving external data via RAG.
Text selection and passage reranking are integral components of context engineering, particularly in the processes of knowledge base selection, retrieval, and context compression. Passage reranking then refines this by reordering those selected texts based on query relevance to ensure the LLM receives the most useful information first, avoiding overload and improving output quality.
Submodular optimization offers three compelling advantages over traditional approaches for text selection and passage reranking:
Theoretical Rigor with Computational Efficiency
Unlike heuristic methods, submodular optimization provides provable guarantees. The lazy greedy algorithm runs in time—compared to combinations for exhaustive search—while achieving a approximation to the optimal solution. This means our solution is mathematically guaranteed to be at least 63% as good as the theoretically best possible selection. No prompt-based heuristic can promise this level of performance assurance.
Smart Stopping Criteria
The saturation behavior we observed provides an automatic stopping mechanism: when marginal gains approach zero, we know to stop adding elements. This capability is unachievable with existing pointwise or listwise rerankers, which operate independently on each item without understanding set-level diminishing returns. The function itself tells us when we've captured sufficient coverage.
Multi-Query Extension
The framework naturally extends to multi-query scenarios—common in DeepResearch where queries are frequently rewritten and rephrased. The same theoretical foundations and lazy greedy algorithms apply seamlessly. Prompt-based approaches lack this systematic extensibility, often requiring ad-hoc solutions for each new scenario.
These benefits stem from submodularity's mathematical foundations rather than engineering tricks. While others rely on prompt tuning and hope for good results, you should learn submodular optimization which provides a principled framework with formal guarantees—a crucial advantage for reliable, scalable context engineering.