"The plan is the product."
计划才是产品。——shadcn/improve README
shadcn 是谁,不用多介绍。他创建的 shadcn/ui 是 GitHub 上 Star 数最高的 React 组件库之一,11 万+,几乎凭一己之力改变了前端组件库的交付范式——不是"装一个 npm 包",是"把源码拷进你的项目,你拥有它,你改它,你对它负责"。这种对控制权和所有权的执念,是他所有作品的设计 DNA。
2026 年 6 月,他在这个 DNA 上又加了一层——开源了一个叫 improve 的 Agent Skill。一周之内,5000+ star。
improve 做的事情,说穿了就是一句话:用最贵的模型读代码库、找问题、写执行计划,用最便宜的模型照着计划敲代码。它自己不碰源码,产出只有一种东西——计划。
这个分工背后是一笔所有用 AI 写代码的人都在付、但很少认真算过的账。用 Opus 读代码库、找 bug、排优先级,值。用 Opus 敲每一行代码、跑每一个测试、写每一句 commit message,不值。但现在的 AI 编程工具不管这些——你给它们什么模型,它们就全程用什么模型。预算好的团队手动切模型——研究阶段用 Opus,实现了切 Sonnet,跑测试了再切 Haiku。切来切去,时间都花在模型下拉菜单上了。
improve 把这个手动切换内建成了自动分工:强模型只负责判断。执行扔给最便宜的、够用的模型。

第 13 章讲 GSD Core 用阶段循环、子智能体和持久化工件对抗上下文腐化。GSD 的回答是"给每个 Agent 一份干净的上下文"。本章讲同一个问题的另一个切面:不是管上下文,管成本。GSD 默认质量优先,谁干活无所谓。但真金白银的 API 账单不这么想。improve 的回答是:强模型做判断,弱模型做执行——把账单和质量一起管了。
安装一行:
1 | npx skills add shadcn/improve |
MIT 开源,遵循 Agent Skills 格式(agentskills.io),Claude Code、Cursor、Codex、OpenCode 装完就能调。
但它跟前面章节讲的技能有一个根本区别。Mattpocock 的 /diagnose 帮你修 bug。gstack 的 /review 帮你查代码。Goal Workflow 的 /goal 帮你实现功能。improve 反着来。你让它"帮我实现这个",它说不。你让它"帮我修这个 bug",它说不。它只做一件事:读你的代码库,找出该做什么,写成一份计划。
README 里有两句话定义了它的全部边界。第一句:"你是一个高级顾问,不是实现者。"第二句:"计划才是产品——它的质量决定了执行者能不能成功。"理解 improve 所有设计决策的钥匙就是这两句话。它不是执行工具,是决策工具。交付物不是代码,是决策。
这带来一个权力反转。大多数 AI 编程工具把写代码当作正事,写计划是可有可无的前置步骤。improve 反过来:计划是一等公民,代码只是计划的衍生品。一份好计划应该自包含到什么程度?你把它交给一个完全不了解这个项目的人,或者 Agent,他能照着做完,不用你坐在旁边解释。需要你解释,计划没写好。
improve 的经济账一句话:高杠杆的思考给贵模型,高重复的执行给便宜模型。

听起来像废话,谁不知道贵的模型好?但 improve 做的不是"用贵的 = 更好"这种粗糙选择。它分了工:
| 工作 | 性质 | 需要的智能 | 交给 |
|---|---|---|---|
| 读懂整个代码库 | 一次性、高杠杆 | 跨文件推理、架构判断、安全直觉 | Opus/GPT-4 级别 |
| 判断什么值得做 | 一次性、高杠杆 | 权衡、优先级、成本估计 | Opus/GPT-4 级别 |
| 写规格和计划 | 一次性、高杠杆 | 精确表达、边界定义、验证设计 | Opus/GPT-4 级别 |
| 照着计划写代码 | 重复、低杠杆 | 按指令执行、跑测试、报结果 | Haiku/GPT-4o-mini 级别 |
这个分工和第 12 章的 maker-checker 分离、第 13 章的瘦编排者模式有同一个源头:不同性质的活交给不同的 Agent。但分工轴不同。GSD 按阶段分(研究员 vs 执行器 vs 验证者),improve 按智能密度分。读代码、做判断、写规格,这些活智能密集,强模型贵得值。敲代码、跑测试、报结果,智能稀疏,弱模型够了。
improve 的 README 用一句话概括了这个经济逻辑:昂贵的、天花板高的模型做智能会累积的那部分——理解、判断、写规格;便宜的模型做执行。翻译过来就是:让最贵的模型做它最擅长的事,然后让便宜的照着做。
这里藏着一个关键前提,也是 improve 最深的洞见:执行的质量上限是计划的质量。弱模型拿烂计划产出烂代码。拿好计划——内联了文件路径、代码摘录、验证命令、STOP 条件——产出接近强模型。弱模型的瓶颈不是不会写代码,是没有上下文。自包含的计划刚好补上。
说白了,improve 干的事就是把强模型对代码库的理解蒸馏到一份 markdown 里,这份文件变成弱模型的上下文。强模型烧一次 token,弱模型烧很多次。只要计划好,每次执行都复用那一次深度分析。总账是省的。
improve 的工作流五步,每步明确的输入、输出和质量标准。
1 | Recon → Audit → Vet → Prioritize → Plan |

Recon 不分析,只测绘。规划前回答几个最基本的问题:
package.json、Cargo.toml、go.mod,不猜。src/ 还是 app/?monorepo 还是单包?测试放哪?配置放哪?npm test 还是 pytest?有没有覆盖率阈值?CONTEXT.md(第 13 章)、STRATEGY.md(第 15 章)、ADR 目录、PRD 文件,Recon 优先吸收。别人花 token 讨论出来的决定,不要重新花 token 再讨论一遍。Recon 的输出是一份代码库地图,后续所有阶段共享。它自己不产生发现,但所有发现依赖它。一个审计员不知道项目是 monorepo,可能把"每个子包有自己的 tsconfig.json"标记为冗余。实际上是设计决定。
整个流水线最烧 token 的阶段,也是强模型最值钱的地方。
improve 派出多个子智能体,每个扫一个维度,并行跑:
| 维度 | 关心什么 |
|---|---|
| 正确性 | 逻辑错误、边界条件、空值处理、竞态条件 |
| 安全 | OWASP Top 10、注入、敏感信息泄露、不安全的依赖 |
| 性能 | 不必要的分配、N+1 查询、阻塞 I/O、内存泄漏 |
| 测试覆盖 | 缺测试、脆弱的测试、不可测的代码结构 |
| 技术债 | 重复代码、死代码、过度抽象、违反约定的模式 |
| 依赖与迁移 | 过时的依赖、未解决的迁移、版本漂移 |
| 开发者体验 | 类型安全缺失、构建慢、开发环境摩擦 |
| 文档 | 缺失或过时的文档、误导性的注释 |
| 方向 | 缺失的功能、架构演进机会、roadmap 对齐 |
每个维度的子智能体独立工作,和第 13 章 GSD 的并行 mapper 同一个模式。并行跑,总时间等于最慢的那一个。
每条发现带四样东西:file:line 证据,不写"可能有注入风险"写 src/auth/login.ts:42;影响评估,如果不管会怎样;预估工作量,S/M/L/XL;置信度。
有一个重要选择:子智能体默认过度上报。宁可多报 100 个最后被筛掉的疑似问题,不能漏一个真的。假阳性浪费的是 Vet 阶段的 token,假阴性浪费的是将来的线上事故。token 比事故便宜。
Audit 产出发现,Vet 做质量控制。
做法很暴力:顾问角色重新读每一个被引用的源码位置,逐条核实"真的有问题吗?"
第 12 章说过 maker-checker 分离,写代码和查代码的不能用同一个 Agent,自己给自己打分太客气。Audit 也一样:发现者对自己的发现有确认偏差。子智能体找到一个问题的时候,已经带着"这里有问题"的假设读了那段代码。让它再读一遍,大概率还是觉得有问题。
Vet 用一个独立的 Agent 重新读,带着"这条可能是错的"的假设。被踢掉的发现记进误报清单,下次审计直接跳过。这个记仇机制很重要。没有它,每次审计都重新报同样的假阳性,你很快就学会忽略所有发现。
Vet 之后一批确认的发现。全做不现实。Prioritize 排优先级。
基础公式:
1 | 杠杆率 = 影响 ÷ 工作量 |
影响和工作量都有不确定性,改进后:
1 | 加权杠杆率 = (影响 × 影响置信度) ÷ (工作量 × 工作量置信度) |
一个影响极高但置信度低的发现("可能"有严重安全漏洞),和一个影响中等但置信度高的发现("确定"有个性能瓶颈),后者的加权杠杆率可能更高。公式把"把握有多大"算进去了。
输出是一张表,不是指令。Prioritize 不说"你应该做前三个",那是人做的决定。但它把信息排清楚,你花最少的时间就能选。
最后一步,对你选中的每个发现写一份可执行计划。存在 plans/ 目录,一个发现一个文件,纯 markdown,人读得了,Agent 也读得了。
计划有索引文件,记录顺序和依赖。计划 C 依赖计划 A 完成后的文件结构,依赖图会标出来。
五步走完就是"计划即产品"的完整闭环:Audit 告诉你有什么值得做,Vet 确认真的值得,Prioritize 告诉你先做哪个,Plan 告诉执行者怎么干。
improve 的命令设计有个原则:从最常用的路径出发,用标志而不是子命令表达变化。默认无参数走完整流水线,大多数时候这就是你要的。其他命令是变体。
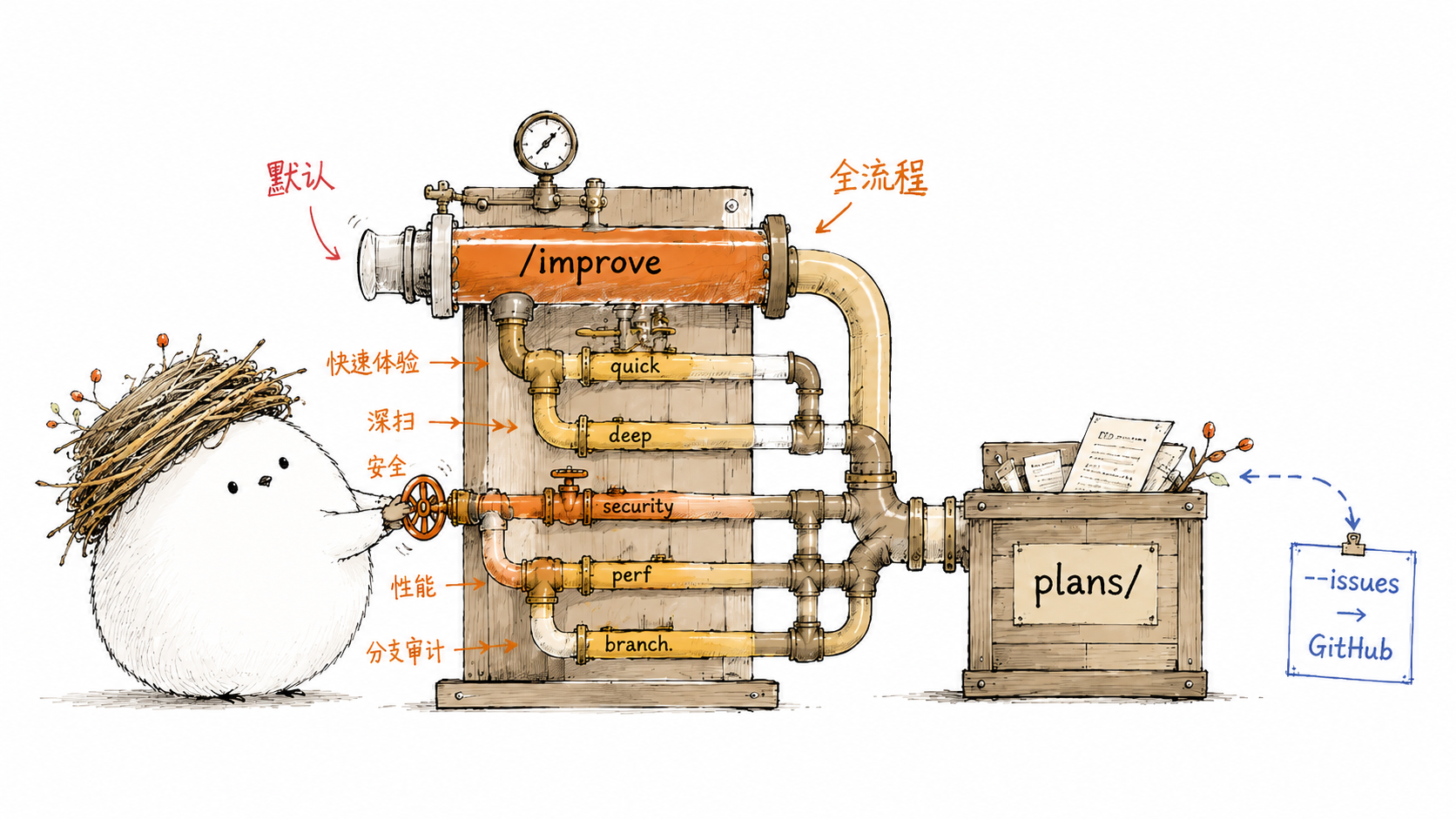
| 命令 | 做什么 | 什么时候用 |
|---|---|---|
/improve |
完整流水线 | 日常改进 |
/improve quick |
只扫热点,返回最优先的发现 | 快速体检 |
/improve deep |
穷尽扫描每个包、每个维度 | 上线前、接手新项目 |
/improve security |
只做安全审计 | 合规、安全评审前 |
/improve perf |
只做性能审计 | 优化轮 |
/improve tests |
只做测试覆盖 | 补测试前摸底 |
/improve bugs |
只做正确性审计 | Bug bash 前 |
/improve branch |
只审计当前分支变更 | PR 前自查 |
/improve next |
功能建议、roadmap 方向 | 下轮规划 |
/improve plan <描述> |
跳过审计,直接为一件事写计划 | 需求已明确 |
/improve execute <计划> |
隔离 worktree 派廉价执行器,完事审查 diff | 执行已批准的计划 |
/improve review-plan <文件> |
强模型评审已有计划 | 计划评审 |
/improve reconcile |
刷新 backlog,验证完成、解除阻塞、退役过时的 | 定期维护 |
带 --issues 时,improve 同时把计划发成 GitHub Issue,每个计划一个 Issue,带标签和依赖引用。计划从 plans/ 目录走出来,进入团队工作流,可以被 assign、comment、close。
/improve execute 是唯一碰代码的命令,唯一偏离"improve 不碰源码"的地方。但它很克制:
有一个人的决策点:审查通过后 diff 摆在你面前,你决定合不合。improve 不替你 commit,不开 PR,不 merge。它把执行自动化了,接受权在你手里。和第 11 章 kanbots 的"晋升永远是手动操作"同一个道理:代码最终要有人对它负责。
原理和命令都讲完了。下面走一遍真的——假设你维护一个 TypeScript monorepo,packages/ 下十几个子包,pnpm + vitest + tsup。你想看看代码库里藏着什么债。
第 1 步:装 improve。
1 | $ npx skills add shadcn/improve |
几秒装完。不需要配置,不需要 API key,不需要连什么外部服务。它就是一个技能文件加一组指令,装进你已有的 Agent。
第 2 步:跑一次全面审计。
1 | $ /improve |
Agent 开始干活了。先吐出来的是 Recon 摘要——它读了 package.json、tsconfig.json、.github/workflows/ci.yml、pnpm-workspace.yaml,把技术栈和构建命令摸清楚了。你扫一眼,没问题,等它继续。
接下来几分钟终端持续滚动。九个子智能体在并行跑,每个盯一个维度。你会看到进度提示:[Audit] correctness... done.、[Audit] security... done.、[Audit] performance... running...。总时间差不多等于最慢的那个维度,通常两三分钟。
第 3 步:看 Vet 结果。
Audit 跑完,improve 自动切到 Vet。它把 Audit 报的每一条发现重新读一遍源码,验证是不是真的。停下来的输出是这样的:
1 | [Vet] 32 findings → 23 confirmed, 6 rejected, 3 merged |
被踢掉的写进了 plans/.veto-log.md。下次审计这两个位置直接跳过。你注意到 23 个确认发现里有些你看一眼就知道是边角料——变量命名可以更好、注释可以补一补。快速往下翻,找那些你也不知道存在的问题。
第 4 步:看 Prioritize 排序表。
Vet 结束,Prioritize 把 23 条发现排成了一张表。前面几行是这样的:
| # | 发现 | 分类 | 位置 | 影响 | 工作量 | 杠杆率 |
|---|---|---|---|---|---|---|
| 1 | migrate-icons.ts:168 图标迁移循环内全量扫描,O(n²) |
性能 | perf-04 | 中 | S | 很高 |
| 2 | getShadowConfig 逻辑在 search.ts 和 view.ts 里分别实现,已有偏离 |
技术债 | debt-02 | 中 | M | 高 |
| 3 | CI 只跑 packages/core,packages/cli 零覆盖 |
测试 | test-01 | 高 | M | 高 |
| 4 | colorUtils.ts:34 暴露了内部函数 parseAlpha,公开 API 已覆盖 |
技术债 | debt-07 | 低 | S | 中 |
| ... | ... | ... | ... | ... | ... | ... |
你在这张表前面花了五分钟。不是看每条发现是什么——而是判断哪条值得现在修。发现 #1 工作量 S 杠杆率很高,闭着眼勾。发现 #2 你之前隐约感觉两处代码有重复但没细查过,improve 证实了而且偏离已经在发生,勾。发现 #3 是真实问题但需要写一整组 CI 测试,今天不想干这个,标记一下以后回来。发现 #4 和后面的十几条要么影响太低、要么你现在有别的事,不勾。
第 5 步:看生成的 Plan。
你勾了 #1 和 #2。improve 为每条生成一个 markdown 计划文件。你打开 plans/001-fix-icon-migration-o-n2.md:
1 | --- |
你扫了一眼。路径对。命令对。STOP 条件合理。份量够一个人(或一个 Haiku)30 分钟内干完。你把这份文件也扔给旁边新来的同事看了一眼,他点点头——项目他完全不了解,但这份计划他看得懂要改哪里、怎么验证、什么情况该停。
第 6 步:执行计划。
你决定先修 #1。
1 | $ /improve execute plans/001-fix-icon-migration-o-n2.md |
improve 在隔离 worktree 里切出一个干净分支,派 Haiku 干活。你的终端开始滚动:
1 | [Execute] Worktree created at .worktrees/improve-001/ |
第 7 步:审 diff,合入。
你打开 diff 看了一眼。改了一个文件,新建了一个测试文件,改动范围刚好在 165-200 行,测试覆盖了 3 个边界情况。没有顺手改别的。你敲了 y。commit 落地,worktree 自动清理。
第 2 个计划 plans/002-extract-shadow-config.md 你决定下午再跑。一样的流程——/improve execute,等两分钟,审一眼 diff,合。
一个小时下来你做了什么。
你打了两次 /improve execute。看了两张表(Prioritize 排序表、diff)。在 Prioritize 表前花了五分钟想"现在修哪个"。其余所有事——读代码库、找问题、验证真伪、排优先级、写执行手册、切 worktree、跑验证门禁、审查产出——全是 Agent 干的。强模型干了一次性的、判断密集的活(审计、核实、排优先级、写计划、审查 diff),弱模型干了重复的、跟随指令的活(敲代码、跑测试)。你的时间是花在了只有你能做的两件事上:决定什么值得修,确认修得对不对。
improve 有几条硬边界,写在指令里,不是建议。
不修改源码。 审计和计划阶段只读。分析代码、记录位置、写计划,写操作只在 plans/ 目录。这个边界让它能在任何代码库上安全跑,无论是个人项目还是生产环境核心服务。
不改动工作树。 审计在当前 checkout 上读,计划写到 plans/。不切分支,不 stash,不改任何工作状态。跑完一次 improve,git status 唯一的变化是 plans/ 下多了几个 untracked 文件。
不复现 secret 值。 审计发现硬编码密钥(这也是安全审计的一项),只记录文件路径、行号和密钥类型,比如 src/config.ts:15 — AWS_ACCESS_KEY_ID,不把密钥值拷进计划。计划引用行号,执行者读源文件,密钥值不会在 markdown 里到处复制。
拒绝"帮我实现"。 对它说"帮我实现这个计划",标准回答:我不实现任何东西。要执行计划用 /improve execute。要改进计划,描述你的疑虑。别让我即兴写代码。
这四条的意义不只在安全。它们定义了一种信任模型:improve 能在任何代码库上放心跑,因为它能造成的最坏结果是 plans/ 下多几个 markdown 文件。这种只读的安全性,是它和"让我帮你重构整个项目"那类 Agent 最根本的区别。
improve 单看是一个技能,放进全书的方法论地图,补了几个空白。
和第 3 章 SDD。 improve 的"计划即产品"是规格驱动的极致版:规格不是开发的输入,规格就是交付物。OpenSpec 和 Spec-Kit 把规格当人和 AI 的合约,improve 把这份合约写到弱模型能照做的粒度。同根,improve 走得更远。
和第 8 章 Goal Workflow 互补。 /improve plan 类似 /prd-to-spec,都是模糊需求到精确方案。方向不同:Goal Workflow 从人的需求往下游走("我想要这个"),improve 从已有代码往上游走("这个代码库还缺什么")。/improve execute 类似 /goal,都是规格变代码,但 improve 显式分离了计划模型和执行模型。两个流程能拼起来:improve 审计产出一批 plan,Goal Workflow 的 /goal 逐个实现,/review-it 审查,/ship-it 交付。
和第 12 章 Loop Engineering 上下游。 improve 可以当 Loop 里的"审计-排序"环节。Loop 定时触发 improve 做审计,产出排序后的计划,自动化层挑高杠杆率的派给执行循环。知识生产(improve)和执行调度(Loop)分开,各自用最合适的模型。
和第 13 章 GSD Core 分工。 GSD 管全阶段循环(Discuss → Plan → Execute → Verify → Ship),improve 只管前半段(审计和计划),执行留给别的工具。不冲突,一条链上的不同环节。GSD 管怎么做一个功能,improve 管该做哪些功能。一个负责过程可靠,一个负责方向正确。
和第 15 章 Compound Engineering。 improve 的 plans/ 目录是一个在累积的知识库。每次审计的误报清单让下一次更准,已完成计划的记录让 reconcile 能自动检测漂移。Recon 阶段读取的意图文档也在持续更新,审计随项目演进变精准。这和 Compound Engineering 的核心主张一样:每次工作让下次更容易。
和第 33 章 /review-it 互补。 improve 是事前主动审计,还没动手先想清楚。review-it 是事后审查,做完了回来检查。两个方向都重要,结合起来就是一个完整的质量闭环:improve 告诉你该做什么、怎么写,/goal 实现,/review-it 验货。
improve 把一个简单的经济逻辑做成了一个完整的工作流:贵的模型做判断,便宜的做执行。但它真正贡献的不是省钱,是重新定义了什么东西值得用最强模型。
Recon → Audit → Vet → Prioritize → Plan,五步流水加九类并行审计加加权杠杆率排序。它是一条"该做什么"的生产线,输出不是代码,是决策。写得够细的决策,细到一个人或一个弱模型能照着做到底。
"计划即产品"背后是一整套工程纪律:自包含上下文、机器可校验的验证门禁、硬 STOP 条件、Git Commit 戳、漂移检查。这些纪律回答一个问题:你不亲自写代码,怎么确保写的人不会搞砸?答案是把判断力蒸馏进计划,不只告诉它做什么,告诉它怎么判断做得对不对。
shadcn 把这个项目开源不到一周 5000+ star。社区的热情不是因为新技术,并行子智能体、验证门禁、worktree 隔离这些前面都讲过了。热的是它的主张:AI 编程的成本不必是刚性的。你不用为了质量把 Opus 用在每一行代码上。让 Opus 做它最擅长的,理解、判断、规划,执行外包给便宜的。在 AI API 按 token 计费的现实里,这个主张比任何架构模式都更直接地改变了你的开发成本。
最后,improve 最值得记的,不是它的命令和流水线。计划不是代码的附属品。计划是独立的、可积累的、随项目演进的知识资产。写好计划,今天能执行,下周能执行,换了三个 Agent 之后还能执行。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。