原文地址:https://geekplux.com/2018/08/28/how-to-implement-sankey-diagram

Google 搜索桑基图,可以搜到一大堆定义。简而言之,桑基图是一种数据流图,展示了数据是如何从左到右流向最后的节点,每条边代表一条数据流,宽度代表数据流的大小。桑基图常用于流量分析,可以很清楚的看出数据是如何渐渐分流的。本文着重讲解如何实现,理论方面的东西各位可以自行了解。
关键点有两个:
桑基图要展现的数据流,算是图(拓扑类、网络型或关系型)数据的一种。实现一个数据可视化图,最重要的就是拆解元素。而实现一个图数据可视化,则最重要的是分清“节点”和“边”。
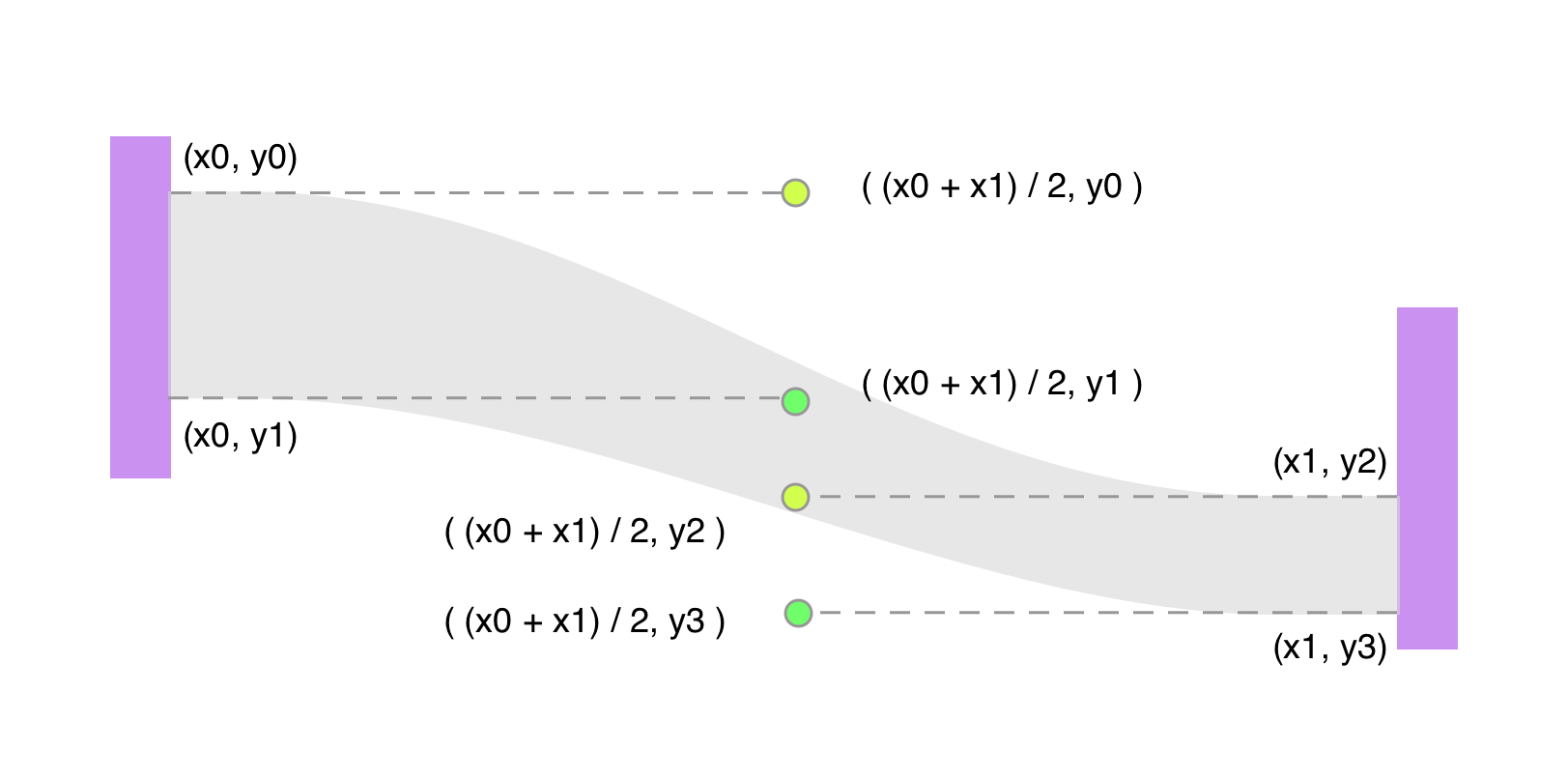
拆解元素之后,最重要的便是坐标的计算,这里包括点和边的坐标。而图形中,任何的元素都可以看作是点连线而成,所以元素坐标的计算实际上就成了点坐标的计算。比如桑基图中,节点是一个矩形,那么只需计算两个点(左上和右下)的坐标(x0, y0),(x1, y1)便可确定;边是一个带形,需要计算四个端点才能确定,带形的弧度则可由简单的三次贝塞尔曲线计算得来。
由此观之,实现桑基图的核心在于计算出以上的这些点坐标。其实实现任意一种可视化都是计算点的坐标。
当数据量到一定程度的时候, 桑基图中的边会出现重叠现象,造成一定的视觉混乱。如何减少可以阅读本文第二节。
经典的图数据结构一般是邻接矩阵和邻接表,我们也可以自己设计。我在做拓扑数据可视化的时候,会先和后端或数据同学商定好我需要拿到的数据结构,通常是这个样子:
{
nodes: [
{ foo: bar },
{ foo: baz },
...
],
links: [
{ source: 0, target: 1, value: 100 },
{ source: 1, target: 2, value: 10 },
...
]
}
而我拿到之后要做的第一步就是先把 nodes 和 links 串联起来,这里每个 link 的 source 和 target 分别是 nodes 的下标,当然你也可以设置其他的引用(指针),总之通过引用讲两者串联起来,变成:
{
nodes: [
{
foo: bar,
column: 0, // 节点所在第几列
row: 0, // 节点所在第几行
value: 100, // 节点数据流大小
sourceLinks: [
{
source: 0,
target: 1,
...
}
],
targetLinks: [
...
]
},
...
],
links: [
{
source: 0,
target: 1,
value: 100,
sourceNode: {
foo: bar,
column: 0,
row: 0,
...
},
targetNode: {
...
}
},
...
]
}
这样,对于某个节点来说,可以直接用 O(1) 的时间复杂度访问到它的任意相邻节点。
这里的计算方法可自己定,通常是取该节点入边和出边的数据流大小之和的最小值。
在桑基图的计算中,我们还需要进行一个关键的计算——计算节点在桑基图中的第几行第几列。
第几列的计算,即为节点在图中的深度计算:
第几行的计算,涉及到排序的问题,通常某一列中的节点都是按节点数据流大小,从大到小排序。
刚才我们说过,坐标计算可以分为两部分:节点和边。其中,边的坐标位置依赖于节点的坐标,所以应该先计算节点坐标。
但在计算坐标之前,首先要明确一个问题:是否限定视图的宽高。这个问题引申出两种节点坐标的计算方式。
如果不限定宽高,那么节点坐标的计算步骤很简单:
大致是这个思路,横坐标的计算取决于两个值,节点宽度和 节点水平间距;纵坐标的计算取决于 节点的数据流大小 和 节点垂直间距。
具体的计算代码,可根据你自己的数据结构来调整。
如果限定宽高,那么计算步骤需要换个思路:
这个思路是 d3-sankey 的实现思路。如果你有限定视图宽高的需求,那么可以直接使用 d3-sankey。
只要确定了节点坐标,边的坐标可以根据它源节点和目标节点的坐标来算出:
以上操作可以通过遍历每个 node 的 sourceLinks 和 targetLinks 来计算。得到边的四个端点以后,就可以算出三次贝塞尔曲线的控制点了:
通常要减少边的交叉,可以采用下面两种方法:
均值排序这个名字是我自己起的。。不过这个方法很实用有效。
对于每个源节点来说,都有相连的目标节点。这里的“均值”指的是所有相连目标节点所在行数的平均值(所有目标节点的行数相加,除以目标节点个数),这个平均值可以大致描述该节点每个出边的位置。每条出边都有这样一个值,这个值越小,则说明该出边要连接的目标节点的位置越靠上,反之越靠下。所以可根据这个值,从小到大排出出边在该节点上从上到下的位置。
我参与的 UBA (User Behavior Analytics 内部项目) 项目中,正好用到了桑基图。除了上述的图形绘制之外,主要复杂的是交互。
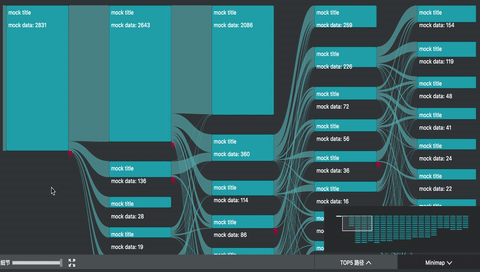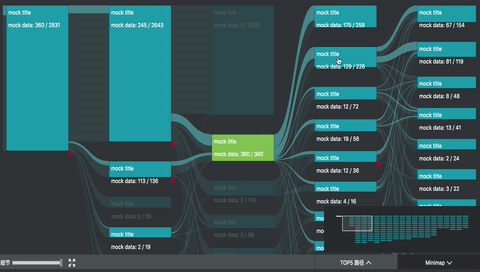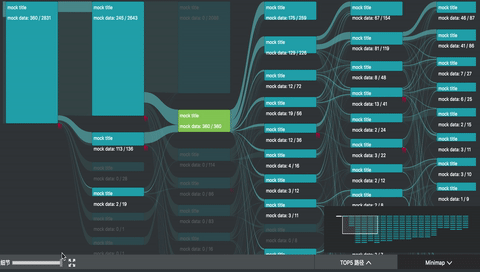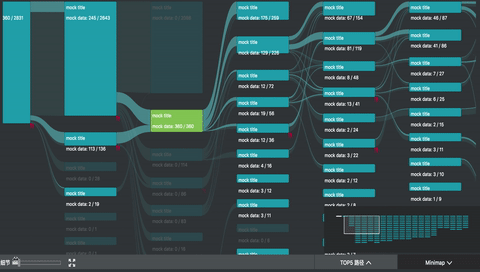
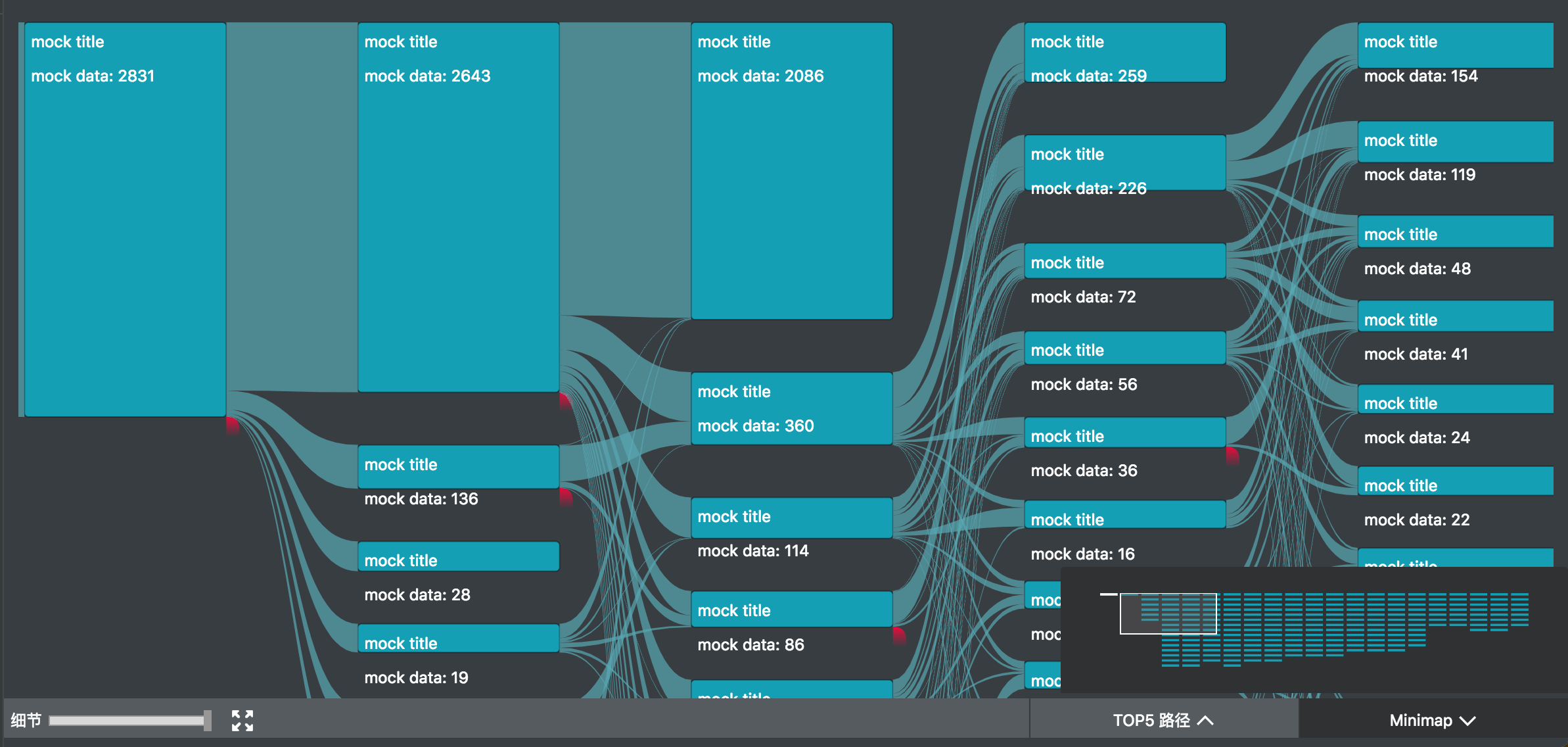
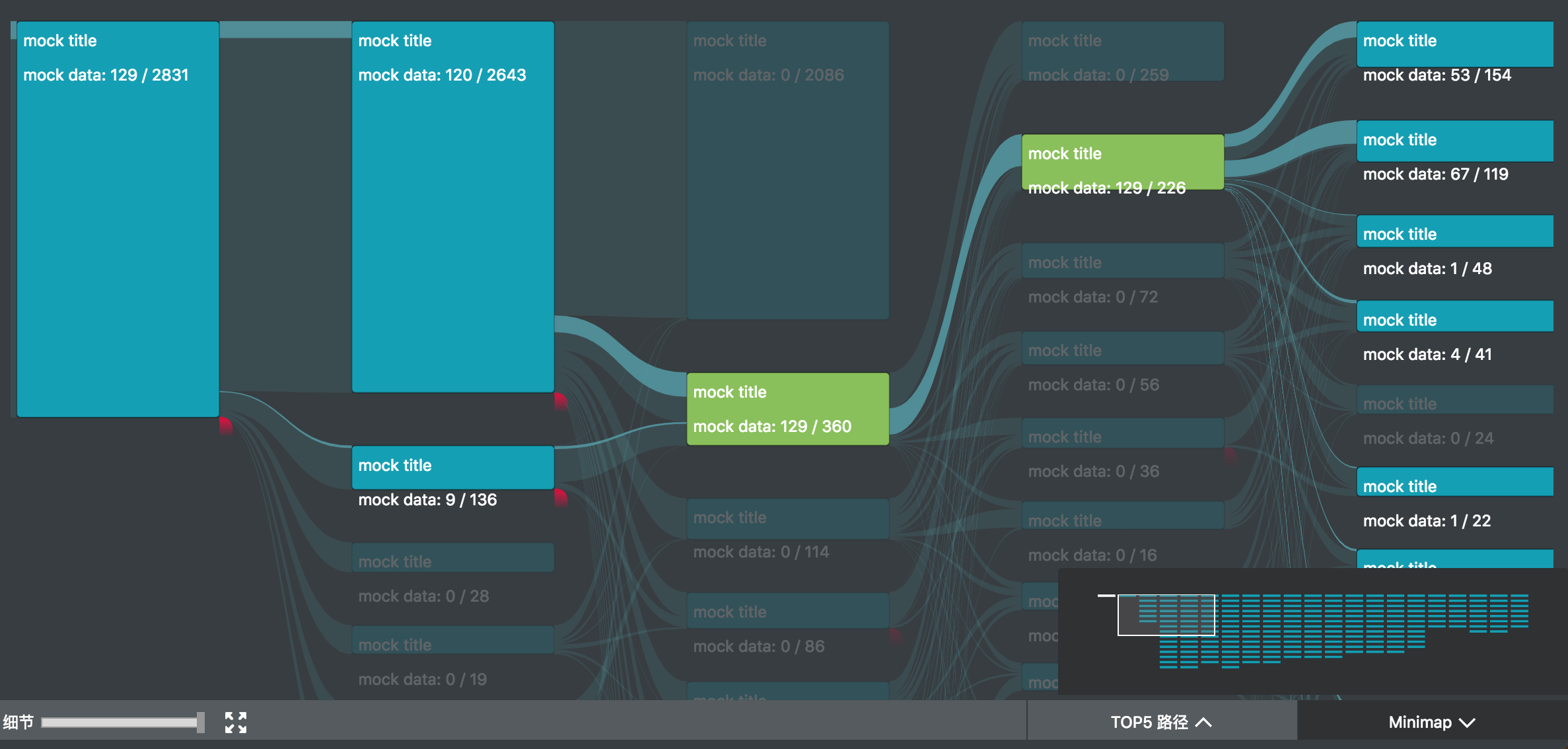
如图所示,除了基本的 hover 交互之外,项目中主要还有
整个桑基图实现下来发现绘制只是一些计算,交互才是更难抽象和处理的部分。
综上,桑基图是一个 展现数据流非常好用的视图,感兴趣的同学可以自己实现一个试试。除了我文章中这些基本的桑基图布局,你还可以试试其他变种,另外交互方面也可以突破刚才我提到的那些,比如我之前实现过点击节点进行折叠/展开的交互。总体来说可视化还是一个比较有意思的方向。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。