Note: Pricing and product information correct as of August 18, 2025, and subject to change.
Companies are racing to build chatbots that can have more natural conversations, AI assistants that can write better code, and systems that can analyze medical data more accurately. This means training massive AI models —like GPT-5 with potentially trillions of parameters. Training and running these massive models requires enormous computing power, which is where cloud GPU platforms come in.
Cloud GPU platforms have become the infrastructure layer for everything from multimodal AI models to realistic virtual worlds, eliminating the challenges of costly, complex hardware ownership. This article compares features, pricing, and platform capabilities of the best cloud GPU platforms available, so you can choose the GPU infrastructure that turns your next big idea into reality.
Key takeaways:
Matching the right GPU architecture (e.g., NVIDIA A100 & H100 Tensor Core GPUs, or newer Blackwell models) to your workload can impact training speed, inference latency, and cost-efficiency.
Beyond hourly rates, factors like spot instance availability, egress charges, and sustained-use discounts vary by provider and can influence which platform delivers the best long-term cloud ROI.
DigitalOcean Gradient™ AI GPU Droplets provide on-demand NVIDIA H100, H200, L40S, RTX 4000/6000 Ada, and AMD MI300X/MI325X GPUs,with straightforward pricing, making them accessible for teams needing high-performance compute without complex cost structures or long-term commitments.
Cloud GPU platforms like DigitalOcean, AWS, Google Cloud, Microsoft Azure, CoreWeave, RunPod, and Lambda each offer distinct features, pricing models, and scalability options.
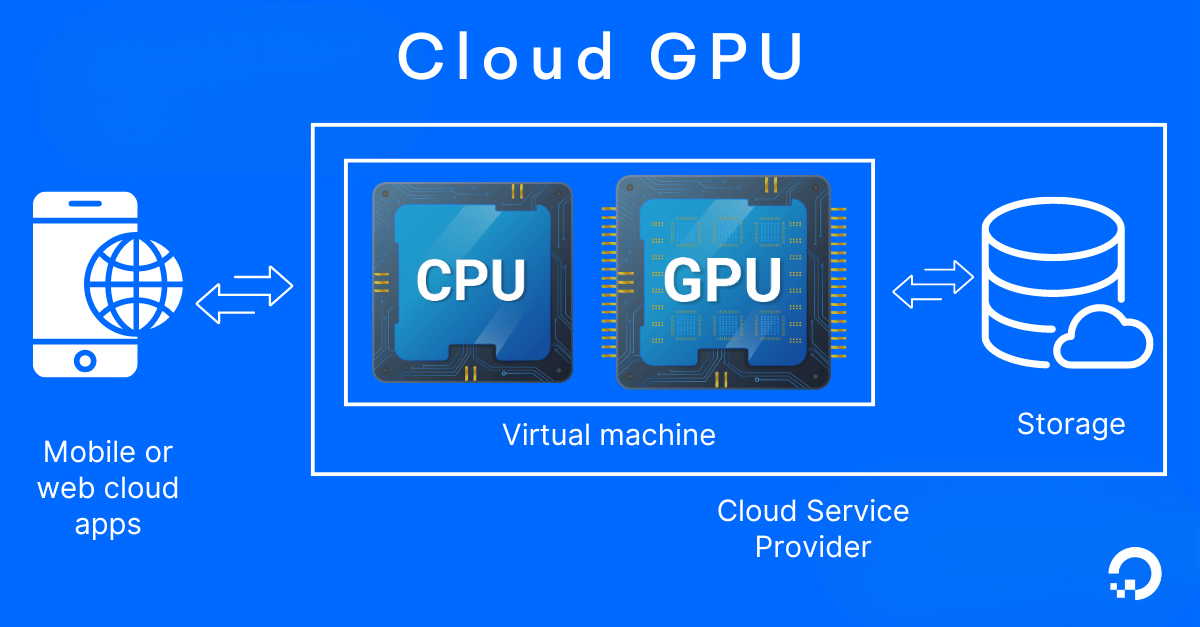
Cloud GPU platforms are cloud-based infrastructure services that provide access to high-performance GPUs for compute-intensive workloads. These platforms virtualize physical GPUs, such as NVIDIA A100, H100, or L40S, and deliver them through cloud instances or containers, for users to accelerate parallel processing tasks like deep learning, scientific simulations, 3D rendering, and real-time inference without managing on-premise hardware.
Users typically access these resources on-demand or through reserved instances, with pricing based on hourly usage, committed contracts, or spot pricing models that can reduce costs for flexible workloads.
💡Working on an innovative AI or ML project? DigitalOcean GPU Droplets offer scalable computing power on demand, perfect for training models, processing large datasets, and handling complex neural networks.
Spin up a GPU Droplet today and experience AI infrastructure without the complexity or large upfront investments.
Choosing the right cloud GPU platform depends on your workload requirements, performance targets, budget constraints, and operational preferences. From GPU architecture to orchestration support, each factor plays a role in improving compute efficiency and cost-effectiveness.
The right GPU model can impact performance. For example, NVIDIA A100 or H100 GPUs work well for training LLMs, while L40S or RTX 6000 (Ada) excel at low-latency inference. Consider memory bandwidth, tensor core support, and FP16/INT8 precision capabilities for AI workloads. Newer GPU generations significantly improve training speed, scalability, and energy efficiency.
Look for platforms that support configurable VM instances or containers with flexible GPU counts (single-GPU to multi-GPU nodes). Ensure support for autoscaling and distributed training if your workload involves large datasets or model parallelism. Scalability is important for production-level deep learning pipelines.
Evaluate benchmarks such as TFLOPS, memory bandwidth, and PCIe/NVLink interconnects to determine a platform’s raw compute power, data transfer efficiency, and suitability for your AI workloads. For example, the NVIDIA H100 delivers up to ~1,979 TFLOPS (FP16 Tensor Core) and a memory bandwidth of ~3.35 TB/s, while the A100 offers around ~624 TFLOPS (FP16 Tensor Core) and ~2 TB/s bandwidth. Also assess throughput metrics for your specific frameworks, like PyTorch or TensorFlow, and models. Platforms that offer pre-installed CUDA drivers and low-latency networking might help reduce training time.
💡Feeling overwhelmed by hyperscalers? Dive into our in‑depth comparison of AWS, Azure, and GCP to demystify how these giants differ in cost, services, and performance, and why exploring alternatives like DigitalOcean could be your smartest move.
Efficient data loading is important for GPU utilization. Choose platforms that offer high-throughput object storage, low-latency block storage, and integration with MLOps pipelines. Support for caching datasets on local NVMe disks can help avoid I/O bottlenecks during training or inference.
For scalable deployments, ensure compatibility with cloud orchestration tools like Kubernetes, or Docker. Platforms that offer pre-configured GPU-enabled containers like 1‑Click Models can help you simplify setup. Managed Kubernetes with GPU autoscaling helps teams in deploying multiple concurrent jobs.
Platforms that offer hourly billing with no long-term commitments are suitable for experimentation and burst workloads, while monthly pricing options can provide predictable costs for steady-state usage. Look for transparent pricing that includes compute, GPU, and bandwidth in a single rate, with no hidden fees for CUDA libraries or AI tooling. When budgeting, account for additional costs such as block storage, snapshot backups, and outbound data transfer, as these can impact the total cost of ownership in production environments.
Cloud GPU platforms are deployed for a range of use cases—from virtual reality streaming and large-scale geospatial mapping to weather forecasting and financial risk modeling. We’ve compiled a list of seven options, covering developer-friendly services, specialized inference platforms, and enterprise-scale GPU clusters, so you can match the right infrastructure to your workload.
DigitalOcean GPU Droplets are virtualized servers with high-performance NVIDIA and AMD GPUs, available in both single-GPU and multi-GPU configurations. These instances include local NVMe storage and AI/ML-ready images, for users to launch compute environments with pre‑installed drivers and frameworks in a few clicks. With substantial GPU memory, fast network links, and compliance with enterprise-grade standards, these Droplets support a range of workloads, from LLM training to real-time inference, while scaling across different regional data centers.
Key features:
Offers a broad hardware range, including NVIDIA H100 GPUs, H200 GPUs, L40S, RTX 4000/6000 Ada, and AMD Instinct MI300X or MI325X, available in both single-GPU and 8-GPU setups.
Provides pre-built Ubuntu images that include drivers, CUDA/ROCm toolkits, and container support (e.g., NVIDIA container toolkit for Docker), helping simplify environment setup and reproducibility.
Each GPU Droplet includes dual NVMe disks, a boot and a scratch disk, paired with high-speed networking (10 Gbps public, 25 Gbps private), and support across multiple regions.
Billed per second with a minimum five-minute charge, the Droplets help ensure transparency and reliability for production workloads.
With a 12-month commitment, H100 × 8 priced at $1.99/GPU/hour. MI325X × 8 costs $1.69/GPU/hour, and MI300X × 8 to $1.49/GPU/hour. On-demand pricing starts at $0.76/hour for RTX 4000 Ada, $1.57/hour for RTX 6000 Ada and L40S, $1.99/hour for AMD MI300X (single GPU), and $3.39/hour for a single H100.
AWS provides GPU‑accelerated compute environments to support AI/ML workloads and graphics-intensive tasks. They offer preconfigured machine images optimized for deep learning (DLAMIs) and GPU-equipped EC2 instances for varied use cases.
Key features:
DLAMIs come preinstalled with GPU drivers (e.g., NVIDIA CUDA, cuDNN), deep learning frameworks (TensorFlow, PyTorch), and communication libraries (NCCL), facilitating rapid GPU-based workload deployment across multiple instance families.
EC2 offers two GPU instance families: the P Family (such as P5, P6) optimized for intensive training and HPC workloads, and the G Family (including G4, G5, G6e) tailored for graphics rendering, streaming, and inference tasks.
Certain GPU instances, like the P4d models, help ultra-scalable distributed training using technologies like Elastic Fabric Adapter (EFA), GPUDirect RDMA, and 400 Gbps low-latency networking for efficient inter-node communication.
On-demand (pay‑as‑you‑go usage billed per second , with a one‑minute minimum) rates for H100-powered p5.48xlarge reach ~$98/hour, A100-based p4d.24xlarge runs $32.77/hour, and V100-based p3dn.24xlarge costs $31.21/hour.
Google Cloud’s Compute Engine helps users to attach NVIDIA GPUs like GB200, B200, H200, etc., to VM instances, to support AI/ML workloads. These GPUs can be provisioned via accelerator‑optimized machine series, where GPUs are automatically attached, or by manually attaching GPUs to general-purpose N1 machine types.
Key features:
Specialized machine series (A4, A3, A2, G2) come pre‑configured with attached GPUs for provisioning and optimized performance in Compute Engine environments.
Users can attach GPUs like T4, P4, P100, and V100 to N1 general-purpose instances, facilitating customization and workload-level tuning.
GPU-enabled VMs can be used in conjunction with Vertex AI, GKE, and Slurm schedulers, for deployment.
Google Cloud prices GPUs separately from the underlying VM’s compute and memory resources. Offers ‘a3‑highgpu‑1g’ instance, with 1 × H100 80 GB GPU, approximately at $11.06 per hour.
💡Explore our detailed guide on the top 7 Kubernetes platforms that rival GKE. Compare features, pricing, and ease of use to find the best fit for your workloads.
Azure provides GPU-accelerated VMs, categorized under the N-series and NG-series, designed for computing needs, from high-end AI model training and high-performance computing (HPC) to virtual desktop infrastructure (VDI) and cloud gaming. Azure GPUs are equipped with NVIDIA GPUs (e.g., Tesla V100, K80), NC-series VMs are optimized for compute‑heavy workloads such as deep learning training, scientific simulations, and 3D rendering.
Key features:
Starting with ND-series (e.g., Tesla P40), this line scales up to ND A100 v4 and ND H100 v5, each offering multi‑GPU configurations with NVLink and InfiniBand support for tightly coupled, distributed AI/HPC workloads.
Based on AMD Radeon PRO GPUs, NG-series VMs are tailored for cloud gaming and virtual desktop workloads.
ND-series variants support scale‑out clusters via GPU Direct RDMA and InfiniBand, alongside NVLink connectivity for distributed training and HPC workflows.
NC40ads H100 v5 instance is priced at approximately $6.98/hour per H100 GPU. For multi-GPU setups, the ND96isr H100 v5 (8 × H100 GPUs) costs approximately $12.29 per GPU/hour. The listed prices are for Linux VMs; prices for other operating systems may differ.
CoreWeave’s GPU compute instances are purpose-built for AI model training, inference, (HPC, and rendering workloads. These offerings are built with the NVIDIA architectures, like H100, H200, A100, L40S, L40, GB200 NVL72, and RTX Pro 6000 Blackwell Server Edition, and can be provisioned in both HGX/HGX NVL configurations and PCIe variants. Each GPU setup is paired with BlueField‑3 DPUs for offloading networking and storage tasks. CoreWeave also supports large multi-GPU clusters with InfiniBand networking and bare-metal Kubernetes orchestration.
Key features:
Provision GPUs ranging from GB200 NVL72 and H200 to A100 and L40S, including RTX Pro 6000 Blackwell edition for high-parameter inference, across both NVL/HGX and PCIe configurations.
Networking and storage tasks are offloaded using BlueField‑3 DPUs.
Multi-GPU clusters are connected with InfiniBand and high-throughput interconnects, for minimal communication latency and for distributed training.
Fully configured GPU instance pricing starts at $49.24/hour for 8× H100, $50.44/hour for 8× H200.
Runpod offers on-demand GPU compute for users to deploy cloud GPUs for AI, ML, and HPC workloads. The platform supports on-demand cloud GPUs, auto-scaling serverless workloads, and multi-node GPU clusters, suitable for use cases like real-time inference, model fine-tuning, agent-based systems, and compute-heavy tasks.
Key features:
Pricing information: On-demand rates start at $1.99–$2.69/hour for H100 configurations, $0.39/hour for L4-class GPUs, $0.33/hour for RTX A6000 and $0.40/hour A40. The pricing information is applicable to ‘Community cloud’.
Lambda provides large-scale GPU infrastructure optimized for AI training, inference, and research, featuring NVIDIA architectures like B200, H200, and H100 Tensor Core GPUs. The platform supports multiple deployment models, from private cloud reservations for tens of thousands of GPUs for on-demand multi-node GPU clusters and single-instance configurations. These GPUs are equipped with HBM3e memory and advanced interconnects, helping large-scale distributed training and high-throughput inference for LLMs.
Key features:
Dedicated access to large GPU fleets (e.g., NVIDIA B300 and GB300) with high-speed Quantum-2 InfiniBand networking.
One-click provisioning of NVIDIA B200 multi-node clusters for large-scale model training.
Lambda Stack with PyTorch, TensorFlow, CUDA, cuDNN, and NVIDIA drivers, offering managed installation and upgrade paths.
Single-instance hourly rates include $2.49 for H100. Multi-node configurations are $2.69/hour for H100 clusters.
How much does a cloud GPU cost?
Cloud GPU pricing varies widely depending on the provider, GPU model, and billing method. Entry-level GPUs such as NVIDIA T4 or V100 can cost $0.40–$0.60 per hour, while mid-tier models like the A100 range from $1.20–$2.50 per hour. High-performance GPUs such as the H100 or B200 can cost $2.50–$6.00+ per hour. Providers may offer discounts for long-term reservations or variable pricing for spot/preemptible instances.
What’s the difference between an NVIDIA A100 and an H100 GPU?
The NVIDIA A100 GPU (Ampere architecture) and H100 GPU (Hopper architecture) are both high-performance GPUs, but the H100 is newer, faster, and optimized for advanced AI workloads. The H100 offers higher tensor core performance, supports FP8 precision for faster training, and has improved memory bandwidth compared to the A100. In practice, H100s can reduce training times for large language models and complex simulations compared to A100s.
Do I need to know Linux to use a cloud GPU?
While many cloud GPU providers offer web interfaces and preconfigured environments, basic Linux knowledge is beneficial. Most GPU workloads involve command-line tools, package managers, and scripting for tasks like environment setup, data management, and model deployment. That said, platforms with managed notebooks, prebuilt containers, or serverless APIs can minimize the need for direct Linux usage.
What is a “spot instance” and should I use one?
A spot instance is a discounted, unused compute resource that a cloud provider can reclaim at any time. They can be cheaper than on-demand instances, making them suitable for non-critical, fault-tolerant workloads like batch training or experimentation. However, they’re not suitable for workloads requiring guaranteed uptime, as they can be interrupted without notice.
What are “egress fees” and how can I avoid them?
Egress fees are charges for transferring data out of a cloud provider’s network to another location, such as your local machine or another cloud. To minimize or avoid egress fees, you can process and store data within the same cloud region, use a provider that offers zero egress between its own services, and select providers with free or reduced egress for specific destinations.
Unlock the power of GPUs for your AI and machine learning projects. DigitalOcean GPU Droplets offer on-demand access to high-performance computing resources, enabling developers, startups, and innovators to train models, process large datasets, and scale AI projects without complexity or upfront investments.
Key features:
Flexible configurations from single-GPU to 8-GPU setups
Pre-installed Python and Deep Learning software packages
High-performance local boot and scratch disks included
Sign up today and unlock the possibilities of GPU Droplets. For custom solutions, larger GPU allocations, or reserved instances, contact our sales team to learn how DigitalOcean can power your most demanding AI/ML workloads.
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。