OpenTelemetry made telemetry possible everywhere – turning observability pipelines into distributed production infrastructure. Distributed infrastructure requires a control plane for inventory, governance, and safe change.
At 500 collectors across hybrid environments, operational overhead becomes a production risk. The moment telemetry pipelines become a distributed infrastructure, they inherit the operational problems of one.
When teams move past initial deployment into long-term maintenance, they encounter the consequences of unmanaged infrastructure:
Left unaddressed, these operational pains become significant consequences for the business:
Ultimately, this reliance on manual changes results in a massive operational impact for every update.
Teams need the same rollout control and governance for observability pipelines that they already expect from Kubernetes and CI/CD.
In practice, that means a control plane that can:
Coralogix Fleet Management provides that control plane for OpenTelemetry at scale.
Fleet Management acts as the control plane for OpenTelemetry, giving teams centralized visibility into collector health, versions, and resource usage across their fleet.
Concretely, the control plane shows up in two places:
Inventory & health (Agent Catalog): Centralized operational visibility into agent health, versions, and resource footprint – so you can find outliers and gaps without manual investigation.
Controlled change (Supervisor-enabled remote configuration): A supervised mechanism to deliver approved configuration updates and restart collectors so configuration rollouts are repeatable, targeted, and auditable.
To ensure this control plane remains open and vendor-agnostic, the system utilizes OpAMP (Open Agent Management Protocol). This standardizes the communication between the management plane and your agents, ensuring consistent orchestration.
The Architecture: Remote configuration is made possible by the OpenTelemetry Supervisor, which manages each Collector instance. The interaction follows a secure, structured flow:
To understand the value of a telemetry control plane, let’s consider a scenario: a security audit identifies exposed PII in your telemetry, requiring an immediate redaction configuration update across every OTel pipeline in your organization.
This is a major hurdle. Organizations often struggle to implement PII redaction across hundreds of collectors, leading to fragmented policies where some data is missed entirely. Without orchestration, these shifts are slow, inconsistent, and prone to error.
In a traditional, unmanaged setup, pushing a security update follows a grueling, manual path that mirrors the slow pace of legacy infrastructure management:
With Fleet Management, this operational loop is compressed into a single, auditable workflow.
Step 1: Before making a change, use the Agent Catalog to verify your fleet’s current state. This centralized visibility shows which versions are active and identifies outliers that require specific attention.
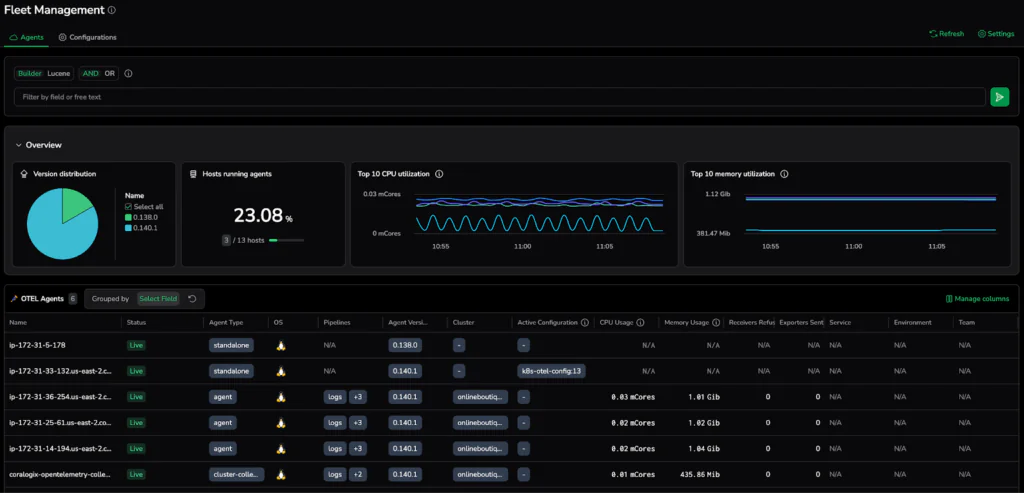
Step 2: Targeted Precision (Selectors) instead of “bulk update and pray” approaches isolate specific hosts or clusters, allowing for safe canary rollouts where you test redaction logic on a subset of agents before a global push.
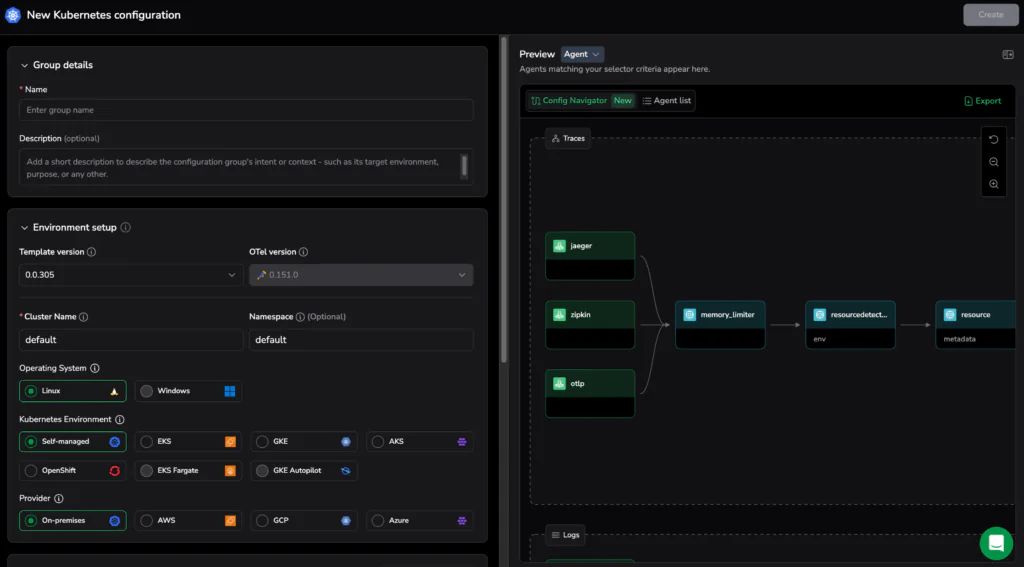
Step 3: Preview and activate a coordinated config set (Configuration Family) to ensure Agent, Gateway, and Cluster Collector configs stay synchronized. The UI provides a built-in preview so you can see which agents match the selectors before activation.
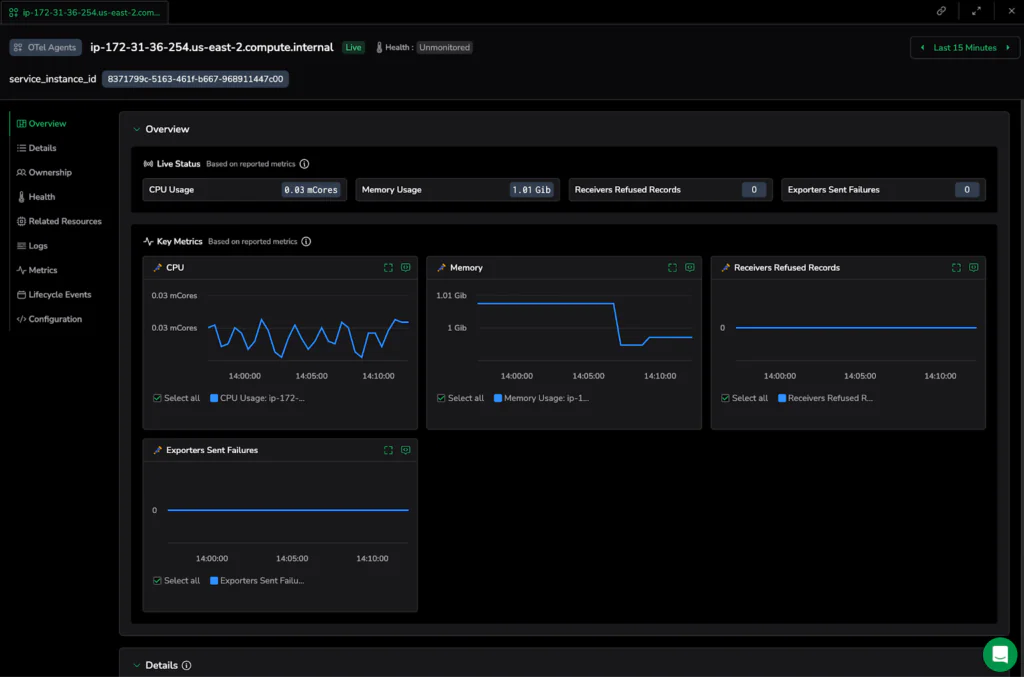
Step 4: Monitor Rollout Health as the Supervisor retrieves the new configuration during its next update check. You can monitor the rollout status as it converges across the fleet. If a collector fails to apply the configuration, you can drill down into its diagnostics to pinpoint the bottleneck and resolve it immediately.
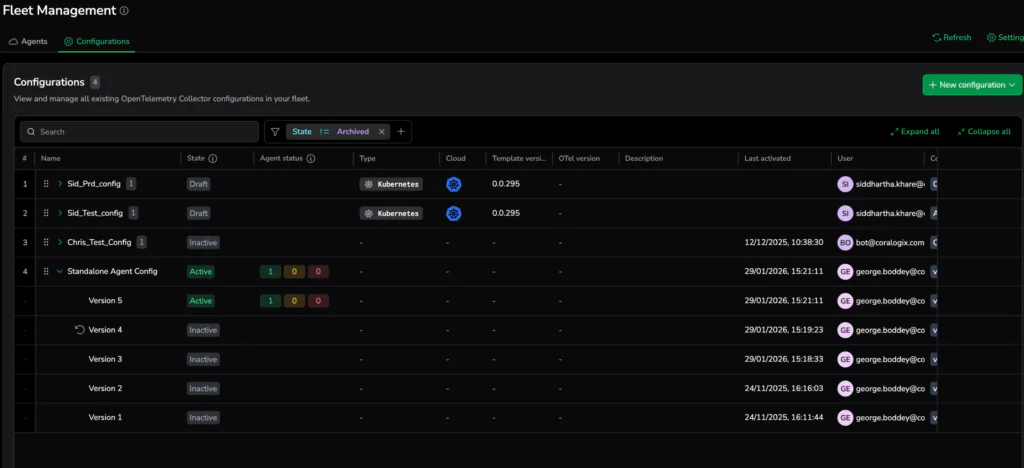
The emergence of OpenTelemetry solved telemetry generation. The next operational challenge to overcome is telemetry governance at scale. Observability pipelines are more distributed than ever, so infrastructure organizations need the same deployment safety, visibility, and lifecycle control they already expect from Kubernetes and CI/CD systems.
Coralogix Fleet Management turns telemetry changes from manual infrastructure work into controlled, observable deployments. It ensures that as your OpenTelemetry footprint grows, your operations remain consistent, audited, and scalable.
If you are ready to move from manual configuration to automated fleet orchestration:
Get Started with Coralogix Fleet Management
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。