大型网站,比如门户网站,在面对大量用户访问、高并发请求方面带来的问题
1大并发:在同一个时间点,有大量的客户来访问我们的网站,如果访问量过大,就可能造成网站瘫痪。
2大流量:当网站大后,有大量的图片,视频, 这样就会对流量要求高,需要更多更大的带宽。
3大存储:你的数据量会成海量的数据,如果我们的数据放入一张表,是无法应对的。可能对数据保存和查询出现问题。
基本的解决方案集中在这样几个环节:使用高性能的服务器、高性能的数据库、高效率的编程语言、还有高性能的Web容器,(对架构分层+负载均衡+集群)这几个解决思路在一定程度上意味着更大的投入。
解决方案:
一、提高硬件能力、增加系统服务器。(当服务器增加到某个程度的时候系统所能提供的并发访问量几乎不变,所以不能根本解决问题)
二、使用缓存(本地缓存:本地可以使用JDK自带的 Map、Guava Cache.分布式缓存:Redis、Memcache.本地缓存不适用于提高系统并发量,一般是用处用在程序中。比如Spring是如何实现单例的呢?大家如果看过源码的话,应该知道,Spiring把已经初始过的变量放在一个Map中,下次再要使用这个变量的时候,先判断Map中有没有,这也就是系统中常见的单例模式的实现。)
三 、消息队列 (解耦+削峰+异步)通过异步处理提高系统性能,降低系统耦合性
在不使用消息队列服务器的时候,用户的请求数据直接写入数据库,在高并发的情况下数据库压力剧增,使得响应速度变慢。但是在使用消息队列之后,用户的请求数据发送给消息队列之后立即 返回,再由消息队列的消费者进程从消息队列中获取数据,异步写入数据库。由于消息队列服务器处理速度快于数据库(消息队列也比数据库有更好的伸缩性),因此响应速度得到大幅改善。
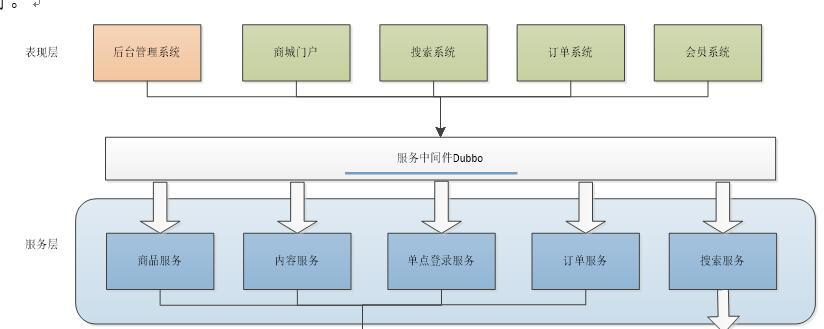
通过使用消息中间件对Dubbo服务间的调用进行解耦, 消息中间件可利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型,可以在分布式环境下扩展进程间的通信。通过消息中间件,应用程序或组件之间可以进行可靠的异步通讯,从而降低系统之间的耦合度,提高系统的可扩展性和可用性。
四 、采用分布式开发 (不同的服务部署在不同的机器节点上,并且一个服务也可以部署在多台机器上,然后利用 Nginx 负载均衡访问。这样就解决了单点部署(All In)的缺点,大大提高的系统并发量)
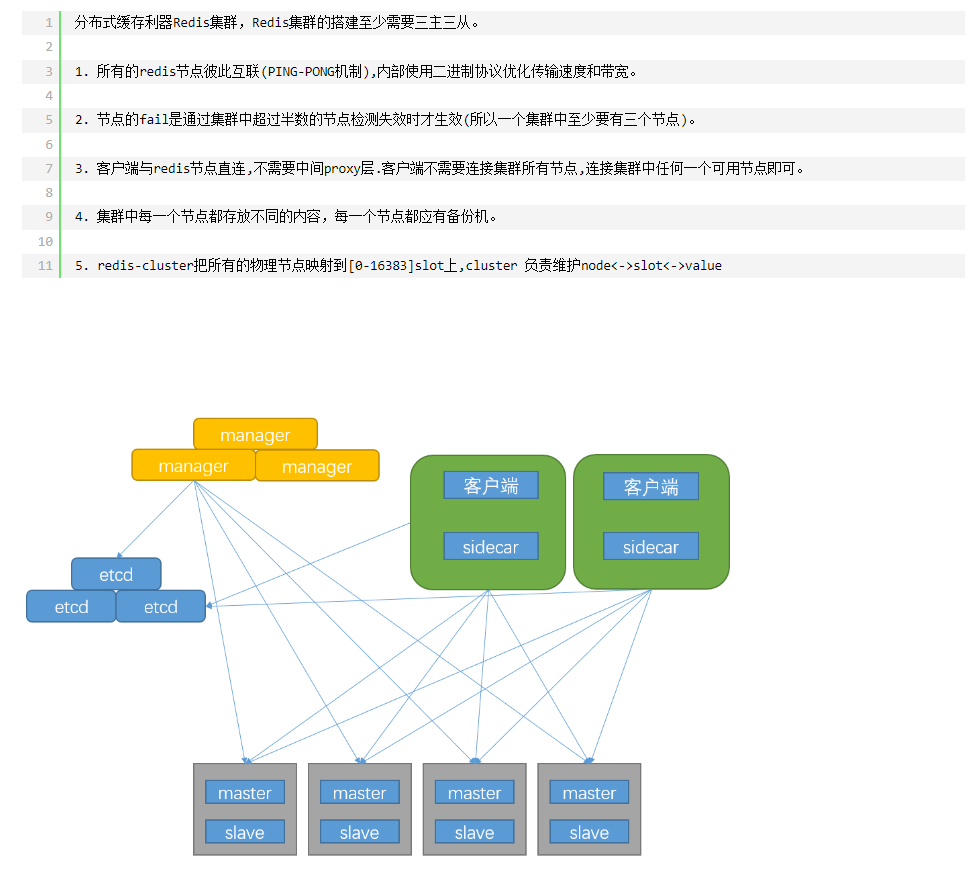
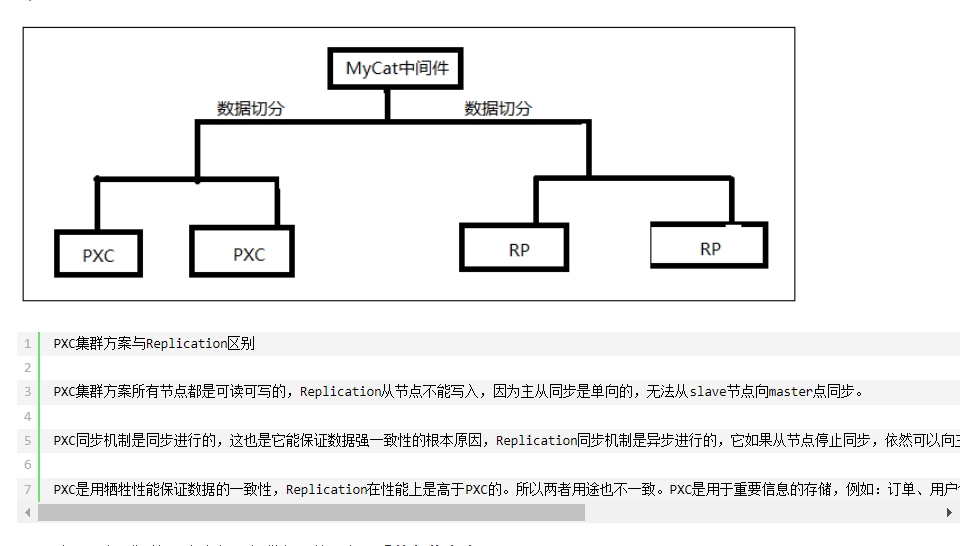
五 、数据库分库(读写分离)、分表(水平分表、垂直分表)
PXC高可用集群与Replication集群结合方案
这种的集群在遇到单表数据量超过2000万的时候,mysql性能会受损,所以一个集群还不够,我们需要把数据分到另一个集群,这个称为“切片”,就是把大量的数据拆分到不同的集群中,每个集群的数据都是不一样的,通过MyCat这个阿里巴巴的开源中间件,可以把sql分到不同的集群里面去。
六、 采用集群 (多台机器提供相同的服务)
七、CDN 加速 (将一些静态资源比如图片、视频等等缓存到离用户最近的网络节点)
八、浏览器缓存 页面静态化(使用php自己的ob缓存技术实现, 主流的mvc框架(tp,yii,laravel)模板引擎一般都自带页面静态化 )
九、使用合适的连接池(数据库连接池、线程池等等)
十、适当使用多线程进行开发。
十一、使用镜像
镜像是大型网站常采用的提高性能和数据安全性的方式,镜像的技术可以解决不同网络接入商和地域带来的用户访问速度差异,比如ChinaNet和EduNet之间的差异就促使了很多网站在教育网内搭建镜像站点,数据进行定时更新或者实时更新。有很多专业的现成的解决架构和产品可选。也有廉价的通过软件实现的思路,比如Linux上的rsync等工具。
十二、图片服务器分离
大家知道,对于Web服务器来说,不管是Apache、IIS还是其他容器,图片是最消耗资源的,于是我们有必要将图片与页面进行分离,这是基本上大型网站都会采用的策略,他们都有独立的、甚至很多台的图片服务器。这样的架构可以降低提供页面访问请求的服务器系统压力,并且可以保证系统不会因为图片问题而崩溃。
在应用服务器和图片服务器上,可以进行不同的配置优化,比如apache在配置ContentType的时候可以尽量少支持、尽可能少的LoadModule,保证更高的系统消耗和执行效率。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。