Mitchell对机器学习的定义:一个计算机程序,它在某一个task里面,根据以前的经验experience,可以通过计算来提高performance。总结一下就是:在一定的场景里面,我们定义一个指标,如果我们有标记好的数据,也就是样本,然后通过计算得到一个模型。模型的输入是样本,输出是预测的概率。所谓的机器学习就是一个计算的过程,无论是训练还是预测。
场景+指标+样本-》机器学习模型
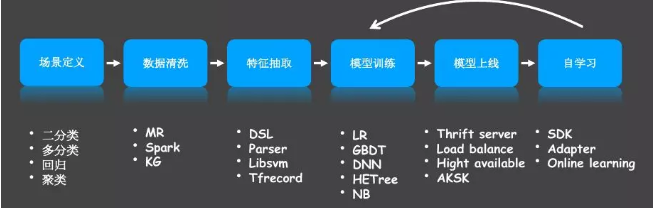
定义模型的使用场景,也就是业务逻辑。场景定义有很多种,包括二分类,多分类。很多时候我们在做一些银行的业务,目标是提高利润。但这并不是机器学习业务能理解的东西。假设这是一个营销的业务,系统会给用户发送理财产品推荐的短信。我们把场景定义成二分类,即推荐什么样的理财产品用户的购买概率更高,对这个理财产品可以做模型预测,即买或是不买的概率。
数据清洗。数据清洗跟传统的大数据处理其实没什么区别,有些特征可能需要补全或者去掉。用到的技术就是,MR(MapReduce)或者Spark,还会用到Knowledge Graph的领域知识。
特征抽取。我们要从数据里生成一些特征,特征其实也是数据的字段,但只是用于机器学习。例如数据里可能有人的性别和年龄,但生成的特征可能是几十万维甚至几百万维的。例如对于线性模型,我们不能将原始数据直接放进去。怎么做特征抽取呢?这跟后面使用的模型框架有关,我们必须生成框架支持的格式。在真正做的时候我么会定义一个特征抽取的DSL,用户通过简单的描述就可以将生成Spark任务。对DSL我们做了一个AST的parser,可以支持像libsvm或者TensorFlow的TFRecord格式。
模型训练。在训练的时候选择就很多了,业界已经证明的一些机器学习算法有LR、GBDT、DNN、NB(Naive Bayes)等。还有我们自研的将离散值转连续值的算法HETreeNet,因为树模型对连续值支持更好。我们可以使用不同的框架,例如TensorFlow就是一个很好的DNN框架。
模型上线。模型上线以后就是一个服务,我们可以部成一个微服务或者单机起的一个进程。我们目前用Thrift server。上线以后同样要解决例如负载均衡和高可用的问题,还有认证授权,我们使用AKSK的加密方法。
自学习。跟普通的应用不一样,大部分机器学习模型都是有时效性的。例如头条里面的推荐,最近一个月大家都在关注娱乐,那么娱乐特征可能是重要的,那我们就要拿增量的数据来继续训练模型。这里我们就需要一些SDK的功能,还要支持不同的数据源。模型训练可能是离线的,我们从Database里取出数据就可以了,在自学习时可能就要接Kafka或者一些Streaming的数据。我们模型的框架还支持online learning,也就是在线更新模型权重。
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。