一、Hbase 写入慢时的集群异常指标
关于hbase写入优化的文章很多,这里主要记录下,生产hbase集群针对写入的一次优化过程。
hbase写入慢时,从hbase集群监控到的一些指标 -hbase 采用HDP 2.6 ,Hbase -1.1.2
基于此 任务 目前的写入慢,并非集群硬件配置造成,而是hbase集群参数设计等设置有问题。
二、重新梳理了hbase了 写入流程
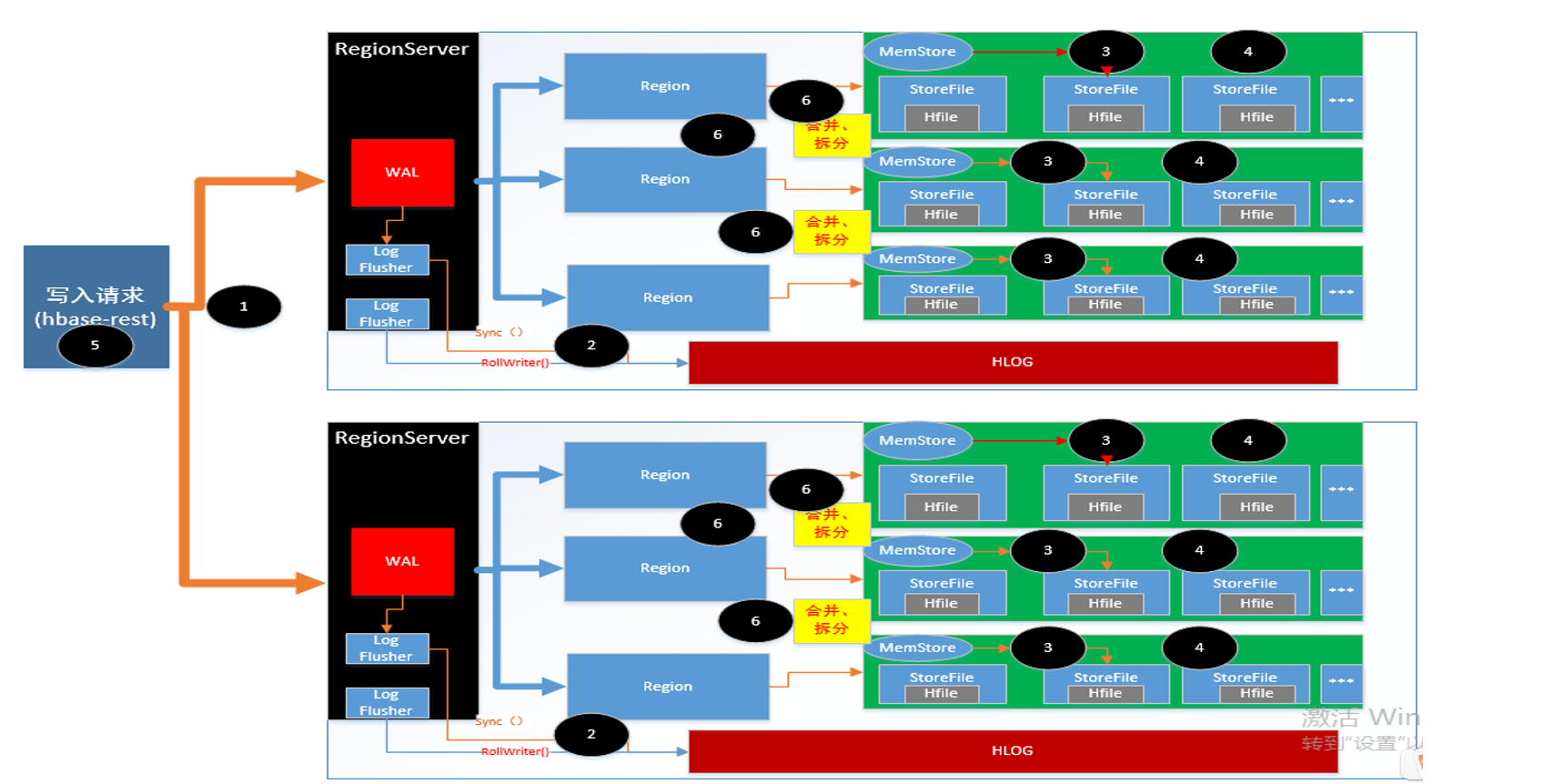
hbase 写入流程,这里就不在追溯,以上是根据理解,自己画的写入流程图 。可以查询的资料较多,这里推荐几个地址
hbase 社区 http://hbase.group/
w3c:https://www.w3cschool.cn/hbase_doc/hbase_doc-vxnl2k1n.html
牛人博客:https://www.iteblog.com/archives/category/hbase/
三、参数优化
基于以上,优化的思路主要分为如下
3.1 利用分布式集群优势,确保请求负载均衡
结合具体数据的RowKey特征创建预分区,注意:如果rowkey 业务数据为GUID,此时要注意guid 的首字母已经做了限制 即0-9 a-f 此时创建再多的分区,起作用的仅是0-9 a-f 开头的分区
create 'Monitor_RowDataMapping6','d', SPLITS => ['HSF.Response.Receive|', 'HSF.Response.Sent|', 'Teld.SQL|','HSF.Request.Time|', 'HSF.Request.Count|', 'HSF.Request.Receive|','HSF.Request.Sent|','Teld.Boss|','Teld.Core|','Teld.Redis|','Teld.WebApi|','TeldSG.Invoke|']
3.2 减少集群阻止写入的频率和时间
对于写入量很大的监控数据不在写入wal,alter 'Monitor_RowData', METHOD => 'table_att', DURABILITY => 'SKIP_WAL‘

由于region split 期间,大量的数据不能读写,防止对大的region进行合并造成数据读写的时间较长,调整对应的参数,
如果region 大小大于20G,则region 不在进行split
hbase.hstore.compaction.max.size 调整为20G 默认为 Long.MAX_VALUE(9223372036854775807)
region server在写入时会检查每个region对应的memstore的总大小是否超过了memstore默认大小的2倍(hbase.hregion.memstore.block.multiplier决定),
如果超过了则锁住memstore不让新写请求进来并触发flush,避免产生OOM
hbase.hregion.memstore.block.multiplier 生产为8 默认为2
Memstore 在flush前,会进行storeFile的文件数量校验,如果大于设定值,则阻止这个Memsore的数据写入,
等待其他线程将storeFile进行合并,为了建设合并的概率,建设写入的阻塞,提高该参数值
写入数据量比较大的情况下,避免region中过多的待刷新的memstore,增加memstore的刷新线程个数
hbase.hstore.flusher.count 调整到20 默认为1
3.3 增加RegionServer 服务端的处理能力
hbase.regionserver.handler.count 默认值为10 调整到400
3.4 客户端请求参数设置
hbase.rest.threads.max 调整到400
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。