一、大数据下的ETL工具是否还使用Kettle
kettle 作为通用的ETL工具,非常成熟,应用也很广泛,这里主要讲一下 目前我们如何使用kettle的?
在进行大数据处理时,ETL也是大数据处理的主要场景之一。 针对大数据下的ETL, 在大数据研究之初,曾经花费很大精力去寻找大数据下比较成熟的ETL工具,但是不多。主要分类如下:
大数据下的ETL处理过程和传统关系型数据库下的ETL处理过程,我的理解本质还是一样的,要说区别 可能是大数据下需要ETL处理的数据速度足够快,这就要求可以充分利用分布式的能力,比如利用分布式的资源进行分布式的的计算。
基于使用经验和产品成熟度,在大数据下我们针对一些对数据处理速度不是非常之高的场景,我们仍然使用kettle。 这里我为什么不说数据量,因为对于一个ETL过程,说数据量是无意义的,好的ETL工具的核心引擎一定是一个类似现在的流式计算
也就是说数据向水一样的流动,流动的过程中做数据处理。也可kettle本身的含义类似。
基于个人的理解,任务kettle的优势主要体现在以下几点
2.运行时
3.可扩展性
4.待完善点
目前kettle 的定位:
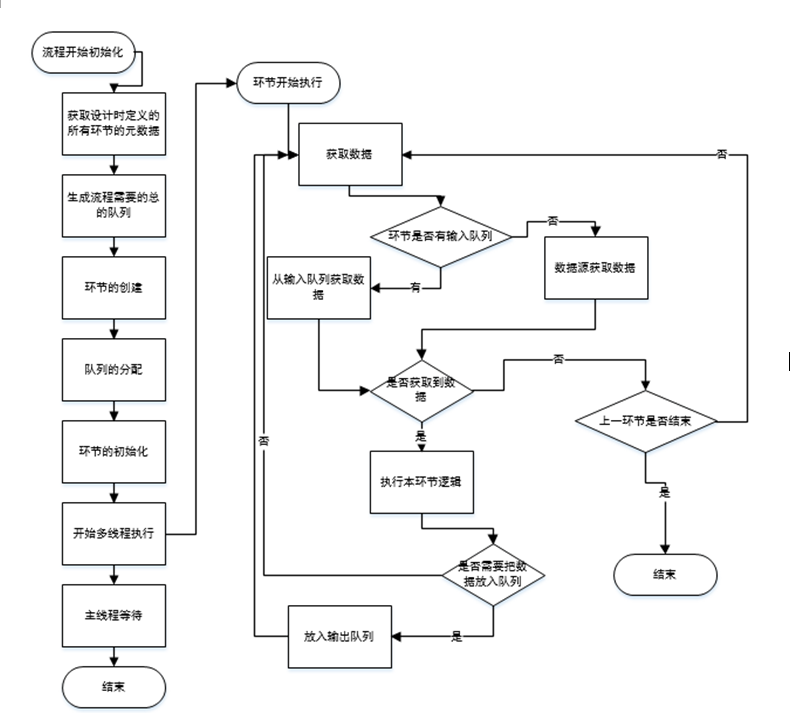
2.2 数据流处理的核心序列
2.2.1 任务的执行顶层序列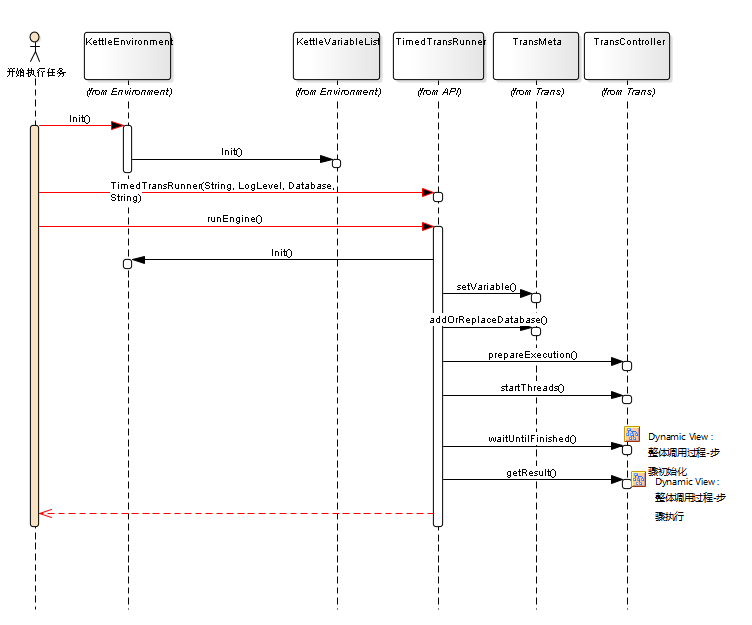
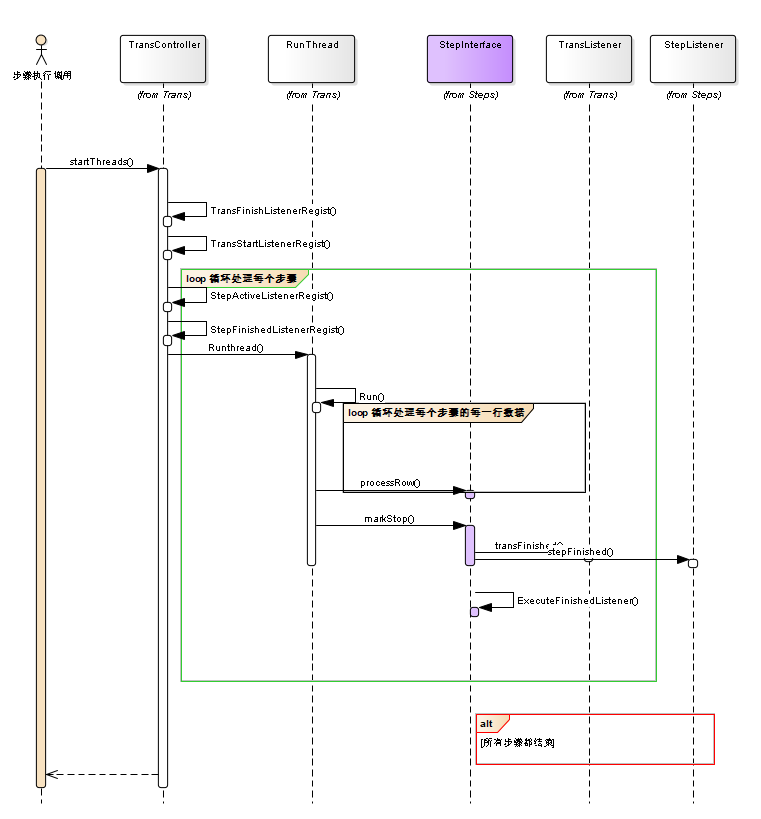
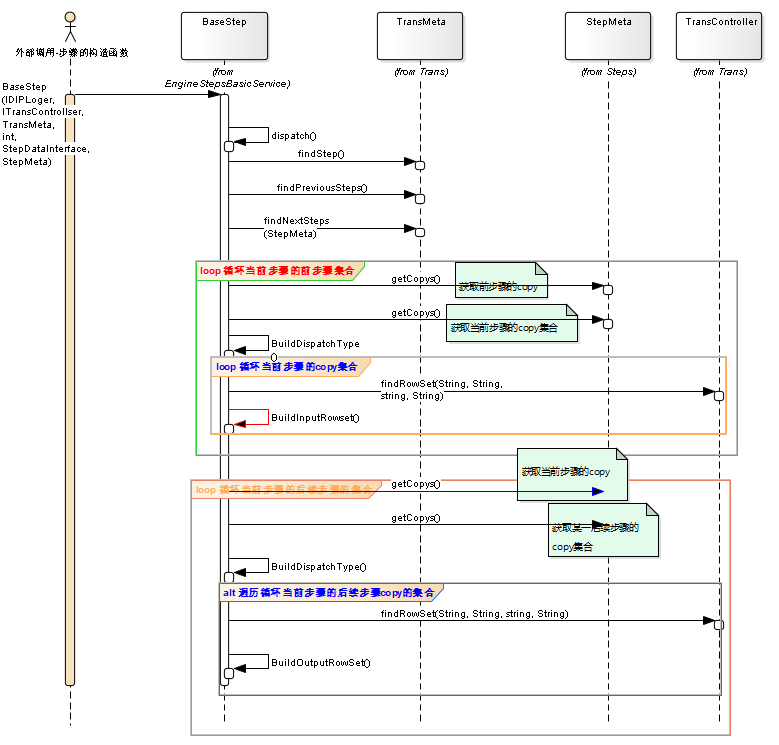
2.2.2步骤的初始化

每个步骤队列的分配过程
数据放入队列

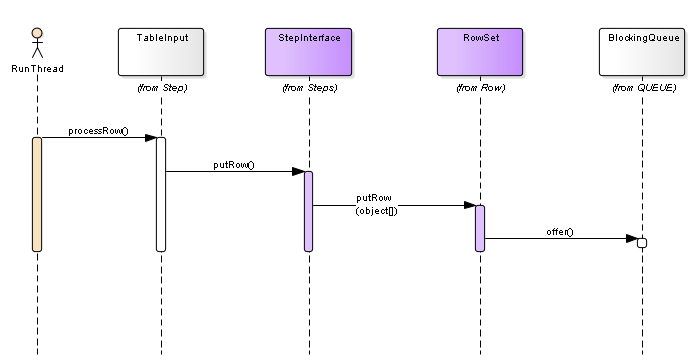
2.2.5 table out put

以上 是kettle 核心数据流处理的核心过程。分享给大家
此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。