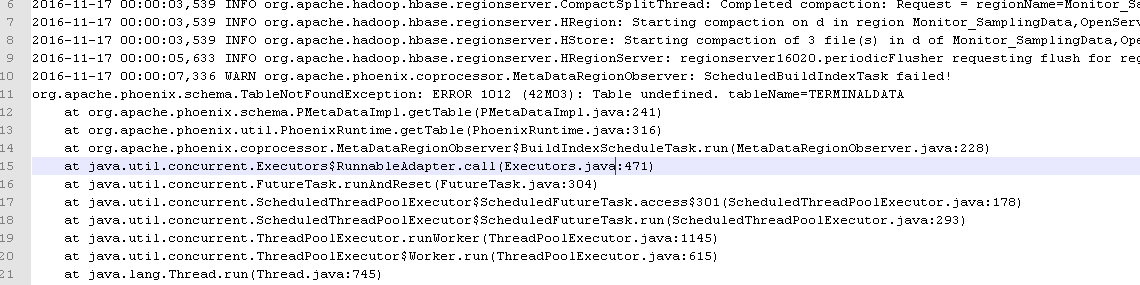
;
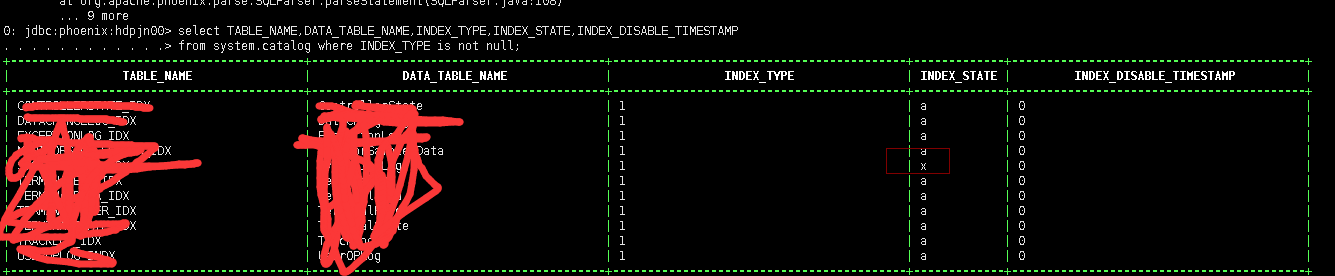
验证sql 是否走索引 发现没有走
.修复索引
Wed Nov 16 11:06:26 GMT 2016, null, java.net.SocketTimeoutException: callTimeout=60000, callDuration=73626: row '' on table 'SYSACTIONLOG_IDX' at region=SYSACTIONLOG_IDX,,1463835204579.ce4eb5993504052a305c8807d6234d93., hostname=workernode2.reddog.microsoft.com,16020,1479228656092, seqNum=1438608 (state=08000,code=101)
 修改phoenix 的执行超时(index.phoenix.querytimeout) ,后执行 再次 仍然出现错误
修改phoenix 的执行超时(index.phoenix.querytimeout) ,后执行 再次 仍然出现错误
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>9200000</value>
</property>
<property>
<name>hbase.rpc.timeout</name>
<value>9200000</value>
</property>
<property>
<name>hbase.regionserver.lease.period</name>
<value>9200000</value>
</property>
<property>
<name>phoenix.query.timeoutMs</name>
<value>9200000</value>
</property>

目前 怀疑 应该在HDInsight 节点下的phoenix 目录下的hbase-site.xml 增加上面的几个参数,但是原生的HDP下phoenix的目录下没有这个hbase-site.xml。 有时间进一步验证....

此内容由惯性聚合(RSS阅读器)自动聚合整理,仅供阅读参考。 原文来自 — 版权归原作者所有。